Data sizes are growing rapidly, and this has forced enterprises into re-designing their data architectures to keep up. Because of this, many companies are discovering that they, in fact, require several components to manage their data: a storage layer to store it, a governance layer to manage it, and a query layer to gain business insights from it.
These three layers (storage, governance, and query) become increasingly difficult to maintain at the data sizes and query loads demanded by modern data systems. Therefore, it's more important than ever to design a system where these three layers can symbiotically exist with each other. We call this unified analytics.
In this tutorial, we’ll walk through a zero-migration solution for blazing-fast data lake analytics using StarRocks as the OLAP query layer. Also, we will see just how fast StarRocks is on the lake by comparing StarRocks and Presto in a TPC-DS 1TB test.
What To Know Before Getting Started
About StarRocks
First, what is StarRocks? If you're unfamiliar with this popular Linux project, you should know that StarRocks is a high-performance analytical database. It's designed to enable real-time, multi-dimensional, highly-concurrent data analysis across a wide variety of scenarios. You can get more details here, and download it for free here.
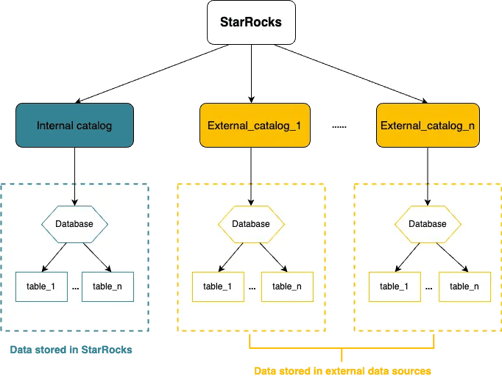
StarRocks' Hierarchy of the data object
From Catalog to Database to Table, StarRocks has a three-layered hierarchy of data objects.
-
The internal catalog contains internally managed databases and tables.
-
External catalog describes how to connect and authenticate to an external data system you want StarRocks to read data from.
-
StarRocks External Catalog supports 2 types of metastores:
-
Amazon Glue
-
Hive metastore
-
-
StarRocks External Catalog supports 4 table formats:
-
Solution Architecture
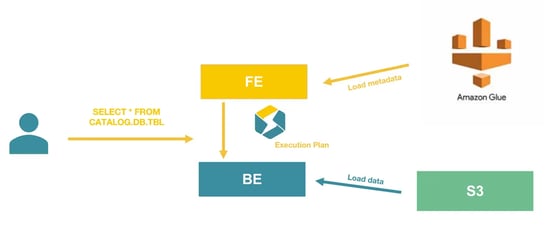
In this solution, we will use AWS as the infrastructure. We will:
-
Upload Parquet data to S3
-
Generate metadata in Amazon Glue
-
Deploy StarRocks with docker-compose
-
Prepare the necessary IAM role and policies to grant StarRocks access to S3 and Glue
Finally, we will use StarRocks' external catalog to retrieve Metadata in AWS Glue and query data in S3 directly without data load.
Solution Walkthrough
The SSB dataset
In this tutorial, we will use the SSB (Star Schema Benchmark) for demonstration. The SSB dataset is a standard benchmark dataset used for testing and evaluating the performance of database management systems (DBMS) and online analytical processing (OLAP) systems. On how to generate the SSB dataset or how to benchmark StarRocks with it, you can find more details on this page.
For demonstration purposes, in this exercise, we will use a modified version of SSB, which has the same schemas of the SSB dataset, but on a smaller scale at around 50MB in total size.
Upload the data into S3
The prepared 50MB SSB dataset can be downloaded from https://cdn.starrocks.io/dataset/ssb_50mb_parquet.tar.gz. Then you can decompress and upload the entire ssb_50mb_parquet folder/directory into your desired S3 bucket. For detailed instructions on how to upload into S3, you can refer to the official AWS documentation. We recommend that you directly drag the whole directory into S3 using the Amazon S3 console.
For the remainder of the tutorial, let's assume that the dataset is in s3://<your-bucket>/ssb_50mb_parquet/.
AWS Glue
There are many ways to set up AWS Glue for the data on S3. In this tutorial, for simplicity, we will use crawler to do it.
First go to AWS Glue - Tables and click "Add tables using crawler"
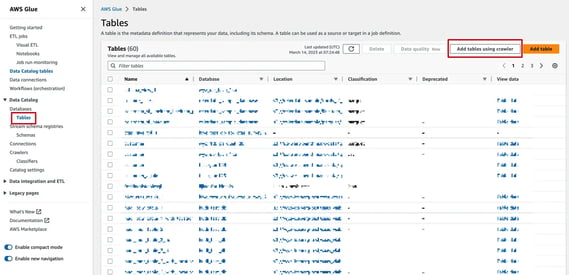
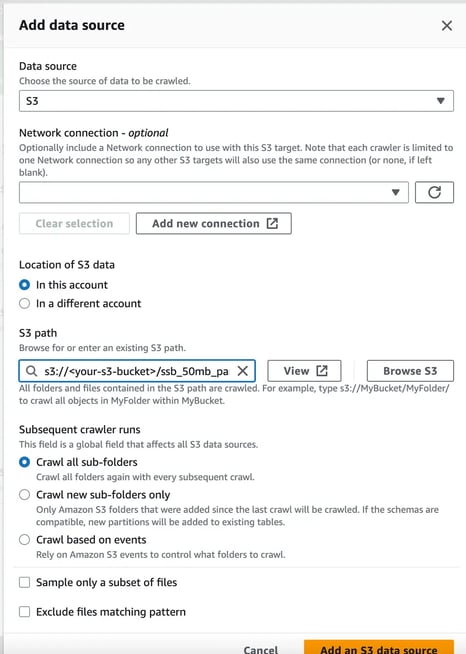
For the data source, we simply input the S3 URL where the dataset is stored in. You can use the S3 URL of the ssb_50mb_parquet home directory, as the crawler is able to crawl all sub-directories recursively.
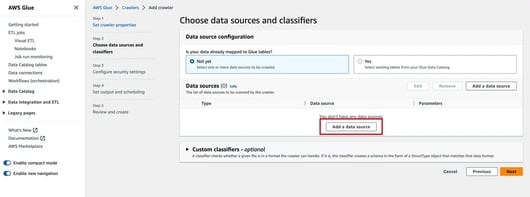
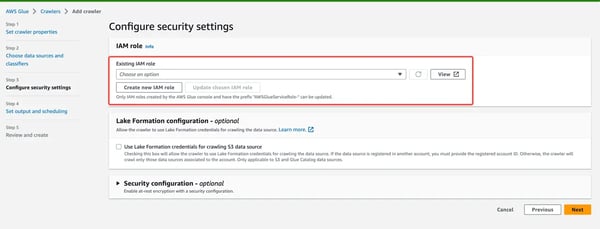
It is recommended to create new IAM role for AWS Glue Crawlers. However, you can use an existing role if one already exists.
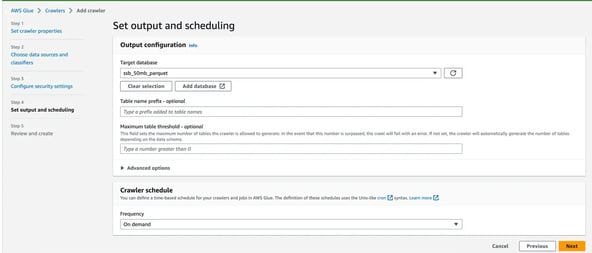
Next... We create a database...
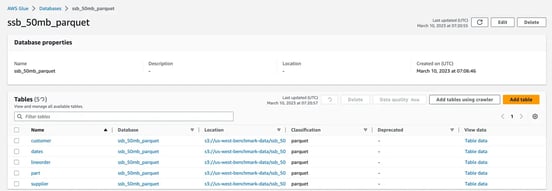
And we are done.

AWS authentications
In order to let StarRocks successfully access data in S3, we need to configure the following authentications:
-
Allow access to the S3 bucket
-
Allow access to Amazon Glue
In this tutorial, for simplicity, we will use the IAM instance profile to grant privileges to StarRocks.
Go to AWS IAM and create an IAM role with the following policies attached.
Note: If you are using an existing instance with instance profile attached, simply attach the following policies to the role.
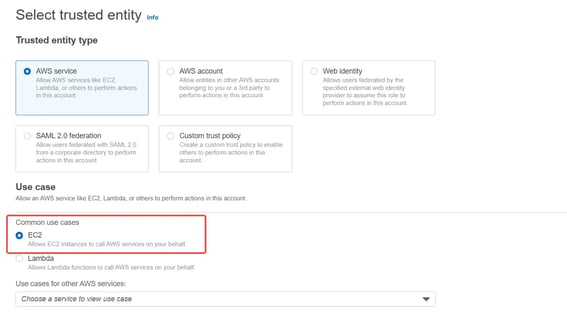
Regarding AWS IAM instance profile, you can read more in an AWS blog here.
For other methods such as IAM user or assumed role, you can read more here.
S3
StarRocks accesses your S3 bucket based on the following IAM policy:
Note: Remember to change the<bucket_name>according to the bucket where you put the dataset in.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "s3",
"Effect": "Allow",
"Action": ["s3:GetObject"],
"Resource": ["arn:aws:s3:::<bucket_name>/*"]
},
{
"Sid": "s3list",
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::<bucket_name>"]
}
]
}
Glue
StarRocks accesses your AWS Glue Data Catalog based on the following IAM policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetPartition",
"glue:GetPartitions",
"glue:GetTable",
"glue:GetTableVersions",
"glue:GetTables",
"glue:GetConnection",
"glue:GetConnections",
"glue:GetDevEndpoint",
"glue:GetDevEndpoints",
"glue:BatchGetPartition"
],
"Resource": [
"*"
]
}
]
}
Deploy StarRocks
Launching an EC2 instance
We have a blog that covers StarRocks' deployment methods extensively. For this tutorial, if you want to get your hands dirty and follow along with the exercise, you can quickly spin up an EC2 instance and deploy a StarRocks environment with docker-compose.
When Launching the EC2 instance, in Advanced details - IAM instance profile, you can attach the role that you just created in the previous step.
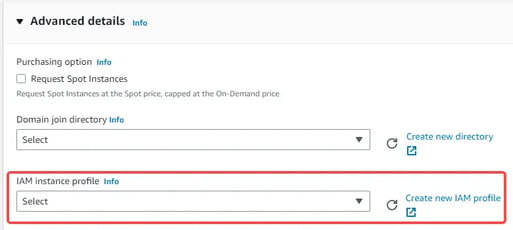
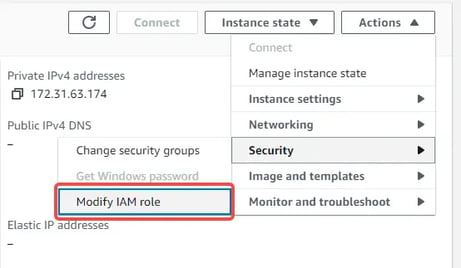
If you are using an existing EC2 instance, you can:
-
Attach the role to the EC2 instance (like the image below).
-
Attach the policy to the role that is already attached to the existing EC2 instance.
Deploy with docker-compose
With docker-compose, you can deploy a StarRocks environment in only a few simple steps.
Note that with this docker-compose yaml file, you will simulate a StarRocks Cluster with 1 FE and 1 BE in the docker environment.
Also, volumes are mounted for data persistence, all data including BE storage, FE metadata and logs for BE and FE are persisted in the ./starrocks directory when deployed.
Note: It is not recommended to deploy StarRocks in a production environment using docker-compose.
# Download the yaml template
# This template simulates a distributed StarRocks cluster with one FE and one BE
wget https://raw.githubusercontent.com/starrocks/demo/master/deploy/docker-compose/docker-compose.yml
# Start the deployment with the yml file
sudo docker-compose up -d
# See the containers of FE and BEs
# See the simulated 1FE and 3BE cluster in the docker network
sudo docker ps
# Get the FE's IP
sudo docker inspect <fe-container-id> | grep IPAddress
# Connect to you StarRocks cluster using mysql client
mysql -h <fe-IPAddress> -P 9030 -uroot
Create an external catalog
We now have everything we need to create an external catalog to connect to AWS Glue. Because we previously setup using instance profile in the previous section, we only need to tell StarRocks to use instance profile, and we are good to go.
CREATE EXTERNAL CATALOG lakehouse
PROPERTIES
(
"type" = "hive",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.s3.use_instance_profile" = "true",
"aws.glue.region" = "<glue_region>", -- e.g. us-west-2
"aws.s3.region" = "<s3_region>", -- e.g. us-west-2
);
Now we can take a look at what we have created:
-- To see the catalogs
show catalogs;
-- Show databases from the `lakehouse` catalog
show databases from lakehouse;
-- Use the database
use lakehouse.ssb_50mb_parquet;
show tables;
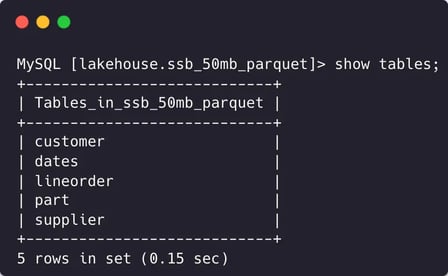
StarRocks can now directly scan data on S3 without any data loading/migration.
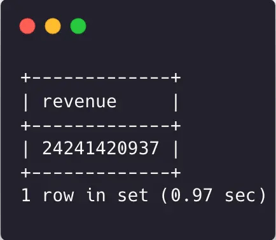
MySQL [lakehouse.ssb_50mb_parquet]> select sum(lo_extendedprice*lo_discount) as revenue
from lineorder, dates
where lo_orderdate = d_datekey
and d_year = 1993
and lo_discount between 1 and 3
and lo_quantity < 25;
Benchmark Results
One advantage of using StarRocks in data lake analytics is its performance. In this section, we take a look at just how fast a fully-fledged StarRocks cluster is on the lake.
The benchmark test is carried out on AWS, with StarRocks and Presto querying the same 1TB set of TPC-DS data on S3 in parquet format, and metadata in the Hive metastore on AWS EMR.
Version
|
StarRocks
|
Presto
|
|
2.5.1
|
0.267
|
Hardware
Presto is deployed with Hive together in AWS EMR.
EMR configuration
|
EMR Master
|
m5.xlarge * 1
|
|
EMR Core
|
r6i.2xlarge * 8
|
StarRocks configuration
|
StarRocks FE
|
m6.xlarge * 1
|
|
StarRocks BE
|
r6i.2xlarge * 8
|
Testing
Neither StarRocks nor Presto has local disk based cache turned on.
Results
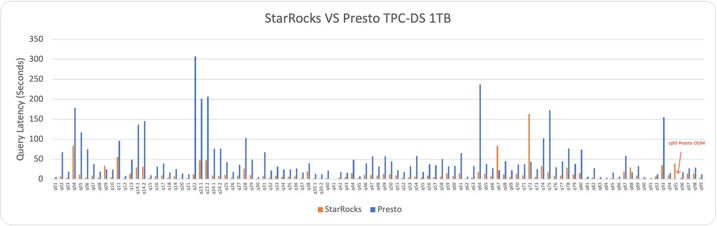
With the above configuration, StarRocks successfully completed all TPC-DS queries on 1TB, while Presto failed on query 95 with OOM.
Excluding query 95, StarRocks is 3.38 times faster than Presto.
Get Started Unifying Your Data Lake Analytics Right Now
This tutorial highlights the seamless integration of StarRocks with the data lake ecosystem. By leveraging the external catalog feature, we showcased how StarRocks enables users to access the latest data in their data lake without the need for any data migration. Additionally, the performance comparison between StarRocks and Presto on the TPC-DS 1TB benchmark test revealed that StarRocks outperforms Presto by 3.38 times. These benefits make StarRocks a powerful tool for businesses looking to efficiently manage and analyze their data at scale.
You can try this for yourself right now. Download StarRocks here to get started, join the community Slack channel, and check out the StarRocks documentation page to learn more.
Appendix
Detailed TPC-DS 1TB Benchmark results:
| TPC-DS query | StarRocks (ms) | Presto (ms) |
| QUERY01 | 1396 | 5602 |
| QUERY02 | 7564 | 67612 |
| QUERY03 | 4453 | 19257 |
| QUERY04 | 83890 | 179031 |
| QUERY05 | 11471 | 116819 |
| QUERY06 | 4324 | 75175 |
| QUERY07 | 9503 | 38054 |
| QUERY08 | 4435 | 18571 |
| QUERY09 | 33782 | 24845 |
| QUERY10 | 4720 | 24162 |
| QUERY11 | 55866 | 96272 |
| QUERY12 | 2166 | 8071 |
| QUERY13 | 14327 | 48399 |
| QUERY14-1 | 29239 | 136633 |
| QUERY14-2 | 31269 | 145513 |
| QUERY15 | 3106 | 10042 |
| QUERY16 | 7369 | 31600 |
| QUERY17 | 9274 | 39211 |
| QUERY18 | 4972 | 17163 |
| QUERY19 | 7593 | 25529 |
| QUERY20 | 2204 | 14219 |
| QUERY21 | 2354 | 12873 |
| QUERY22 | 11825 | 307246 |
| QUERY23-1 | 47558 | 201035 |
| QUERY23-2 | 47491 | 206666 |
| QUERY24-1 | 9038 | 76511 |
| QUERY24-2 | 8835 | 76487 |
| QUERY25 | 10985 | 42687 |
| QUERY26 | 3556 | 18346 |
| QUERY27 | 9170 | 36419 |
| QUERY28 | 26926 | 102762 |
| QUERY29 | 10649 | 48294 |
| QUERY30 | 2172 | 5201 |
| QUERY31 | 8279 | 67779 |
| QUERY32 | 3154 | 21816 |
| QUERY33 | 8459 | 31885 |
| QUERY34 | 6128 | 24672 |
| QUERY35 | 5647 | 25013 |
| QUERY36 | 7393 | 27418 |
| QUERY37 | 3049 | 17389 |
| QUERY38 | 19992 | 39870 |
| QUERY39-1 | 2205 | 13207 |
| QUERY39-2 | 2016 | 12378 |
| QUERY40 | 2643 | 21859 |
| QUERY41 | 224 | 702 |
| QUERY42 | 4316 | 18426 |
| QUERY43 | 5451 | 16222 |
| QUERY44 | 15649 | 48599 |
| QUERY45 | 2524 | 7057 |
| QUERY46 | 10769 | 39547 |
| QUERY47 | 10472 | 57071 |
| QUERY48 | 9075 | 31896 |
| QUERY49 | 13434 | 57325 |
| QUERY50 | 12877 | 44546 |
| QUERY51 | 9396 | 22463 |
| QUERY52 | 4213 | 18288 |
| QUERY53 | 4810 | 33088 |
| QUERY54 | 6759 | 58635 |
| QUERY55 | 4241 | 18279 |
| QUERY56 | 8498 | 37189 |
| QUERY57 | 4612 | 35054 |
| QUERY58 | 6620 | 50588 |
| QUERY59 | 14672 | 32286 |
| QUERY60 | 8384 | 33503 |
| QUERY61 | 14968 | 65473 |
| QUERY62 | 2020 | 6520 |
| QUERY63 | 4938 | 32817 |
| QUERY64 | 18243 | 237344 |
| QUERY65 | 13701 | 37700 |
| QUERY66 | 7722 | 28130 |
| QUERY67 | 83858 | 22395 |
| QUERY68 | 11868 | 45134 |
| QUERY69 | 5441 | 22879 |
| QUERY70 | 13581 | 36521 |
| QUERY71 | 9895 | 37342 |
| QUERY72 | 163834 | 43341 |
| QUERY73 | 6084 | 25284 |
| QUERY74 | 33158 | 102358 |
| QUERY75 | 17449 | 172819 |
| QUERY76 | 8789 | 29867 |
| QUERY77 | 9334 | 44491 |
| QUERY78 | 29065 | 77308 |
| QUERY79 | 11439 | 38682 |
| QUERY80 | 15420 | 73728 |
| QUERY81 | 1811 | 6300 |
| QUERY82 | 4338 | 27938 |
| QUERY83 | 960 | 5371 |
| QUERY84 | 981 | 3606 |
| QUERY85 | 2288 | 17002 |
| QUERY86 | 2195 | 6448 |
| QUERY87 | 19935 | 58678 |
| QUERY88 | 29254 | 17461 |
| QUERY89 | 9428 | 33007 |
| QUERY90 | 3003 | 5255 |
| QUERY91 | 637 | 2477 |
| QUERY92 | 7198 | 12313 |
| QUERY93 | 34985 | 155395 |
| QUERY94 | 9907 | 15563 |
| QUERY95 | 39820 | OOM |
| QUERY96 | 3395 | 17456 |
| QUERY97 | 14429 | 27018 |
| QUERY98 | 14461 | 29098 |
| QUERY99 | 3931 | 12412 |
