There are a lot of different database solutions which offer a dizzying number of features. This guide is meant to help you match the features or capabilities to your requirements.
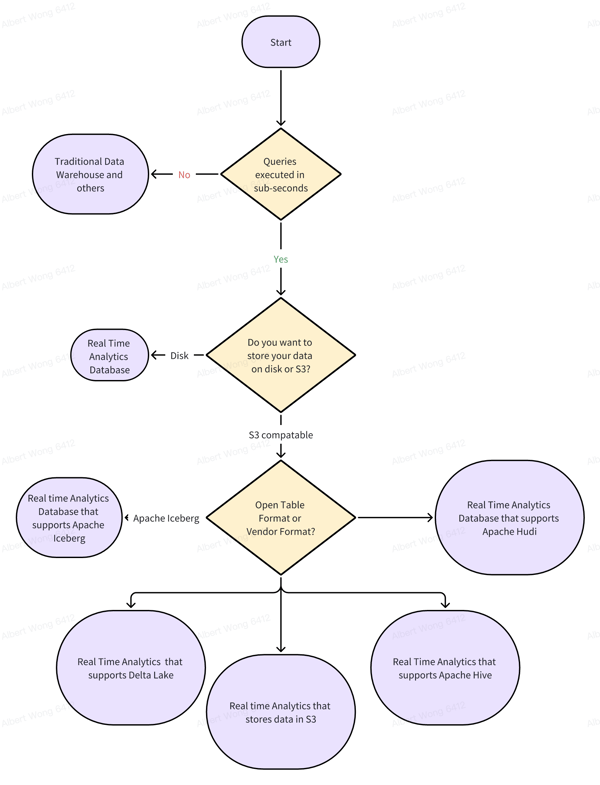
First, let's think about use cases. Who are your users? Do you have a few users with fixed reporting like traditional business intelligence or are you doing customer facing analytics where there could be 1000s of users with adhoc queries that want data as fresh as possible. Does the database support common scenarios in adtech, martech, and fintech? Do you have mutable data or immutable that you want to do analytics on? If it's more fixed reporting, support for materialized views will be important. If there is a need to quickly make changes to the schema or need for ad-hoc queries, the ability to have normalized tables and JOINS will be important to reduce the burden on data engineers. If you are working with mutable data, you're going to need a database that does upserts and deletes with real time streaming.
Next, let's think about where you store the data. It used to be everything is on local disk but now companies are moving to open table formats that support object stores (S3). It's gotten to the point where open table formats are almost as fast as local disk but cost 5% of the cost of local SSD disks. That's a huge amount of saving when you're storing terabytes or petabytes of data.
The TL-DR; for picking an OLAP database
-
If you're looking for a keep it simple (KISS) data lake solution, Dremio is hard to beat. It's an opinioned data lakehouse with Apache Iceberg has its foundation. See more below for the details and cons.
-
If you're looking for data lake solution that can talk to everything and be a traditional data warehouse, StarRocks is the winner here. They support all the major open table formats, can store data on local disks and they're very fast. So fast that they rank #1 on ClickBench for query performance.
-
If you're looking for real time anatylics platform, people hover over ClickHouse and StarRocks. Both dominate the ClickBench query performance benchmark. ClickHouse has been in the market longer so they have more integrations and feature maturity however StarRocks is rapidly catching up.
-
Losers are the databases listed in the traditional data warehouse. It's hard to compete with the databases that came after them since all of them were purpose built to be better, faster and cheaper.
Traditional Data Warehouses in the marketplace
They handle traditional batch data warehouse use cases very well. You can create tables, have indexes, materialized views, views, etc etc etc. On top of that most if not all have have elastic infrastructure abilities, can be consumed as a managed service with usage based pricing and are on "the cloud".
SnowflakeIf you need a general-purpose analytics engine for business intelligence and reporting, Snowflake is a great option. However, it is not well-suited for interactive slice and dice at scale, due to cost and resource scaling.
|
AWS RedShiftRedshift was built for traditional BI. Great integration with the AWS ecosystem however performance/cost ratio isn't optimal and you're locked to the AWS environment.
|
Google BigQueryBigQuery is a great analytics engine and GCP probably has the best data engineering and data science tooling of any public cloud vendor. It's the "easy button" for GCP but compared to others in the marketplace, it's not that fast or cheap.
|
PostgreSQL and MySQLThese are fast and capable relational databases for general purpose transactional workloads (modifying single or small groups of data). But for analytics at scale, they can bottleneck user-facing queries, and other similar analytical queries (data aggregation queries across large gigabyte, terrabyte and petabyte datasets).
|
ElasticsearchElasticsearch is great if your data is JSON and you need to query in JSON. However the technology is based on Apache Luence (1999) and it's very mature (2010). It doesn't have the design of the new OLAP databases on the market like SIMD, query cost based optimizer, a vectorized engine or ability to read/write to open table formats like Apache Iceberg and Apache Hive. There is more maintenance needed to keep a cluster up and running and has a reputation for being resource-hungry.
|
Azure Analysis ServicesAs Microsoft's native solution in Azure cloud, it is tightly integrated into the Microsoft stack, which makes it easy for you to use. However the negatives is cost, complexity to figure and manage, and performance (size and complexity of the model, amount of data being processed and number of users accessing the model).
|
Real time analytics OLAP databases and other systems
They're different than traditional data warehouses in that they do all the traditional data warehouse stuff better and faster (cloud native architecture, high concurrency to meet user facing needs, SIMD for performance, vectorized engine for performance, column stores for performance, real time ingestion to support data freshness, data tiering through the support of local disk and open table formats on S3). Most, if not, all are built after 2010.
ClickhouseThere are a lot of things to like about Clickhouse (2012). They have fast query performance, support integration to open table formats like Apache Iceberg (read only) and Apache Hudi (read only) and support JOINS.
The cons is join performance, not being good at upserts, requires vertical scaling, not good at horizontal scaling, data partitioning is "basic" and query planner isn't good.
In addition ClickHouse is particularly good at aggregations and filters, but because it was intended for immutable data, it does not do well with update or delete queries.
More details can be read at https://www.starrocks.io/blog/starrocks-vs-clickhouse-the-quest-for-analytical-database-performance
|
Trino / StarBurst / PrestoDB / AWS AthenaLarge mature community (2013) that has a lot of users and reference customers. Very good at what they do, specifically being a federated query engine.
Both engines are used for large-scale data processing.
StarRocks has some unique features, like automatic query rewrites and partition-level refresh in materialized views, a cache system that can improve query performance, and better join performance through different algorithms that can be used to reorder join execution.
More details can be read at https://www.starrocks.io/blog/comparison-of-the-open-source-query-engines-trino-and-starrocks
|
Apache Pinot / StarTreeApache Pinot started as an internal project at LinkedIn in 2013 to power a variety of user-facing and business-facing products. The first analytics product at LinkedIn to use Pinot was a redesign of the social networking site's feature that allows members to see who has viewed their profile in real-time. Apache Pinot dominate, from a marketing perspective, as the company to use for user-facing realtime analytics.
The negatives with Apache Pinot as I understand it is: slow performance (4x slower on ClickHouse Benchmark compared to StarRocks), no Cost Based Optimizer (which means they need to write more optimized queries with Pinot, and Pinot is going to have a hard time dealing with complex queries) and cannot query Apache Iceberg or Apache Hudi or any of the open table formats on data lake (can't take advantage of open analytics formats and cloud based storage).
|
Apache Druid / ImplyIt is developed by (2011) the ad analytics company Metamarkets. Druid offers low-latency data ingestion, flexible data exploration and analysis, high-performance aggregation, and easy horizontal scaling. It can process data at a high scale and provisions pre-aggregation capabilities.
The negatives with Apache Druid: slow performance (40x slower on ClickHouse Benchmark compared to StarRocks), lack of support for all types of JOINS which means more engineering to support denormalization, does not support real-time upserts (you need to use a background process which is more engineering) or any way to push/write data in real time, and limited indexing capabilities.
|
Databricks PhotonIf you're all in Databricks, where this is their next generation product for data processing. They market it as THE data lakehouse. The query engine is closed source and the open table format, Delta Lake, is open source*** (really cool features are not open sourced unless you "buy" the enterprise version). Realistically, the market is skeptical of their open source commitment and doesn't want a semi-closed solution.
|
SingleStoreA very mature product (2011) that is a solid HTAP choice. They can be configured to have rowstore tables or columnstore tables with the idea that you can get the best of both worlds.
Although they don't have an open source product, they do have a community version of their product that is "free". They also don't really do open table formats.
|
FireboltFounded in 2019, they are similar to Rockset except their pedigree is Microsoft SQL server and GCP BigQuery. What interesting is that they use a forked version of ClickHouse as the query layer and then wrote a PostgreSQL protocol compatible SQL layer. This sounds all great but it's all closed sourced and only available through a managed service.
|
DremioThere is a lot to like for Dremio (2015). They built a data lakehouse product on top of Apache Arrow and Apache Iceberg. The product is fast and they know their space.
The cons is that they really only support Apache Iceberg as their open table format. If you want to use Apache Hudi, Apache Hive or Delta Lake, it's just not possible (yet).
|
RocksetA new player in the OLAP market (2019) that came out of Facebook. Built on top of RocksDB, Rockset has a great technology heritage.
Downside is that they are only available as a cloud-based service and not open source. Based on prices, it seems to require more IT resources to get that query performance.
|
StarRocksStarRocks was founded in 2020 by several members of the Apache Doris team who spun off to form a new project with a different direction. Although the StarRocks product was initially based on Doris, 90% of the StarRocks codebase is now new. The product does many things well. Fast performance as measured by ClickBench, the ability to support all types of joins, mysql protocol support and the ability to connect to all major open table formats like Apache Iceberg, Apache Hudi, Apache Hive and Delta Lake and can also use local disk,
The cons is that they are still relatively new in the database market. StarRocks lack feature maturity, could use more quality of life, and ease of use features in their product.
|
“When to StarRocks” checklist
- I have large scale aggregations with strict performance SLAs
- I need to support high queries per second for analytics on large data volumes
- I need real-time insights from streaming data or insights from batch data analytics
- I can’t cache queries results or pre-define them in advance
- I need the ability to use JOINS in my queries because writing denormized tables is too much work
- I want to query local disk, remote disk and open table formats like Apache Iceberg, Apache Hudi, Apache Hive and Delta Lake.
- I want to use open source software
“When not to use StarRocks” checklist
- I have security certification requirements (can be provided by CelerData)
- I want to use a managed service (can be provided by CelerData)
- I want security features (can be provided by CelerData)
- I have inverted index search use cases for my data
