In late 2022, ClickHouse released its open source performance benchmark project, ClickBench. This benchmarking tool quickly generated a lot of attention and discussion. Data warehouse vendors and data infrastructure engineers rushed to the site to check out who ranked as the 'fastest' analytical database.
We applaud ClickHouse for not only providing such a helpful tool, but also for supporting a culture of healthy competition in the community by vetting and accepting results submitted by other groups. The team behind StarRocks had the pleasure of collaborating with the ClickHouse team to discuss test results, and this experience was nothing short of enlightening.
A Tale of Two Databases: Who Is the Fastest Analytical Database?
If you've been keeping an eye on ClickBench's latest results, you've probably come across some of the entertaining discussions related to the products competing for the number one spot on the chart. ClickHouse could have easily turned ClickBench into a vendor-biased marketing tool, but to their immense credit, the ClickHouse team displayed great sportsmanship by accepting results from other projects in the space. This included StarRocks, which ran up near the top of the chart immediately. In fact, StarRocks briefly held the number one spot on its first day on ClickBench.
We could end the story there, but ClickHouse turned around with some impressive results from their next release that put them back on top. Just like any great athlete, ClickHouse wasn't going down without a fight.
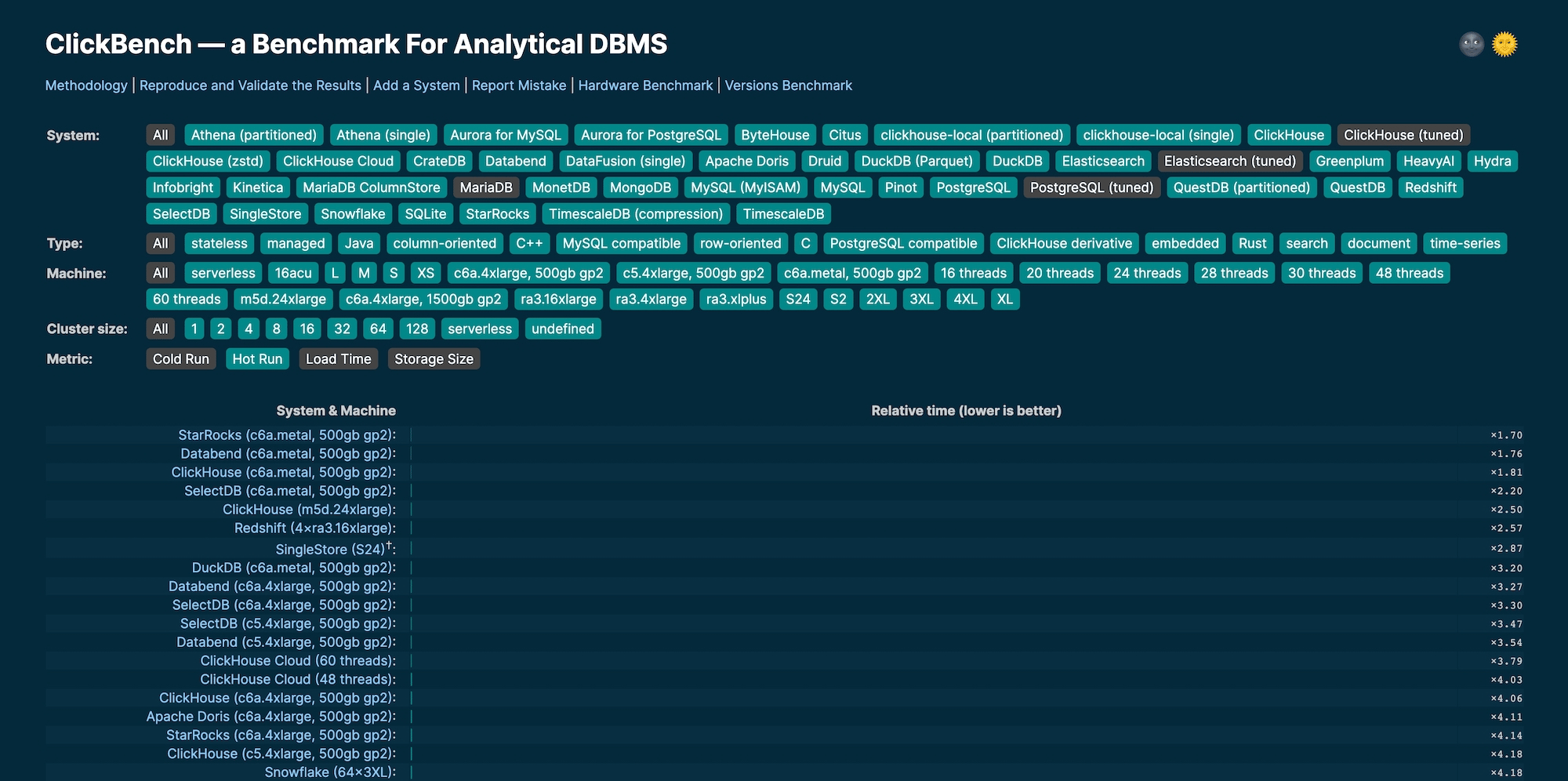 StarRocks in the top spot on ClickBench (February 27, 2023).
StarRocks in the top spot on ClickBench (February 27, 2023).
But the StarRocks community is not so easily discouraged. Only a few months later StarRocks re-claimed the top spot with its latest release.
This race is reminiscent of the competition you'd find between famous sports rivalries: Ronaldo and Messi, Federer and Nadal, and even the Lakers and Celtics. Okay, maybe that's a little dramatic, but the StarRocks community continues to enjoy its intense, but friendly, competition with ClickHouse.
While ClickBench is an excellent indicator of performance for certain scenarios, and StarRocks and ClickHouse are basically neck and neck in that race, we believe there is much more to a great analytical database than what is covered by ClickBench alone.
Going Beyond ClickBench: Properly Evaluating High-Performance Analytical Databases
Sticking with the sports analogy, ranking in ClickBench is just one of the many competitions (query performance) under a larger category (top analytics databases), like the 100-meter freestyle in swimming. To be seen as the best, StarRocks needs to compete and win in different competitions, not just one. Because analytical workloads in real life vary drastically from customer to customer, we need to support all scenarios well.
One great athlete comes to mind in this example: Michael Phelps. Not only did he win the 100-meter freestyle gold in the Olympics, but he also won the 200-meters, 400-meters, butterfly, and medley competitions.
 Could StarRocks and ClickHouse be the greatest rivalry since Messi vs. Ronaldo? Probably not, but it's fun to think about.
Could StarRocks and ClickHouse be the greatest rivalry since Messi vs. Ronaldo? Probably not, but it's fun to think about.
That's the level of success the StarRocks community aspires to. At StarRocks, we believe there are other scenarios not covered in ClickBench that matter in real life. So we have also been publishing test results against other important test sets such as TPC-H and SSB.
Factors we believe should be highlighted for proper evaluation are:
-
Query performance on joined tables without de-normalization - This is a critical feature to simplify the analytics data pipeline and improve timeliness. ClickBench only focuses on de-normalized table query performance.
-
Scalability to handle growing data volumes - Modern analytics architectures needs to be distributed and scalable. ClickBench is great for single node configurations, but how easy is it to add or remove a server from the distributed platform? This is important to know.
-
High concurrency queries - More and more use cases require support for large numbers of concurrent queries. ClickBench only tests a single query session, so we need to investigate the performance of 100s or 1000s of concurrent queries.
-
Ingestion speed - This is another area ClickBench doesn't cover. While processing queries is critical, it is also important to handle high-speed data ingestion in real-time.
This isn't an exhaustive list of factors that should be tested, but for ClickBench to adopt them would make the tool more valuable for evaluation purposes.
Similarities Between Clickhouse and StarRocks
Massively Parallel Processing (MPP) with SIMD
Cost-based Optimizer (CBO)
Pipeline Execution Framework
-
Reduce the cost of task scheduling for various computing nodes in the query engine.
-
Increase CPU utilization while processing query requests.
-
Automatically adjust the parallelism of queries execution to fully leverage the computational power of multi-core systems, thereby enhancing query performance.
Differences Between Clickhouse and StarRocks
Clickhouse JOIN performance isn't as good
While ClickHouse excels in analytical queries and big data processing, its join performance isn't always on par with its other capabilities. Several factors contribute to this, making understanding the challenges and potential solutions crucial.
Key Reasons for Join Performance Limitations:
1. Lack of dedicated optimizer for joins: ClickHouse relies on its general cost-based optimizer for join queries. This optimizer, while robust for other tasks, might not always choose the most efficient join algorithm for complex queries, impacting performance.
2. Limited pre-aggregation support: ClickHouse doesn't extensively utilize pre-aggregation before joins, a common technique for optimizing query performance. Pre-aggregation involves summarizing data beforehand, reducing the amount of data needed for the join operation.
3. Challenges with large tables: Shuffle JOIN is the only type of join that scales well especially across large tables. While ClickHouse supports distributed joins across multiple nodes, it does not have the ability to perform data shuffling at query time. As of right now, implementation of Shuffle JOIN is still in progress (https://github.com/ClickHouse/ClickHouse/issues/41340).
More information can be read at https://celerdata.com/blog/from-denormalization-to-joins-why-clickhouse-cannot-keep-up.
Clickhouse is not good at upserts
While ClickHouse excels at many tasks, particularly analytical queries on large datasets, upserts (operations combining insert and update) aren't its strong suit. This primarily stems from its design choices and underlying storage engine specifics. Here's why:
1. Lack of Dedicated Upsert Mechanism: ClickHouse doesn't offer a native upsert function. You can achieve similar functionality with specific table engine configurations and workarounds, but it's not as straightforward or efficient.
2. Immutable Storage: ClickHouse tables are built on immutable storage, meaning data updates involve inserting new rows instead of modifying existing ones. This approach prioritizes efficient reads and data append, but complicates handling updates directly.
3. Eventual Deduplication: Updatable table engines like ReplacingMergeTree handle updates by eventually merging duplicate rows with the same sorting key during background maintenance processes. This means:
- Duplicates exist temporarily: Before the merge, your data may contain duplicated rows, potentially impacting queries.
- Queries need awareness: You need to consider potential duplicates in your queries, adding complexity.
- Performance considerations: Frequent updates can lead to more merges and performance overhead.
Clickhouse requires vertical scaling, not good at horizontal scaling
While ClickHouse can benefit from both vertical and horizontal scaling, it does have a strong preference for vertical scaling, meaning increasing resources within a single node rather than adding more nodes to the cluster. This bias stems from several key factors in its architecture and design:
1. MergeTree Engine: ClickHouse's default storage engine, MergeTree, is optimized for append-only workloads with efficient data writes and fast columnar reads. Its log-structured merge-tree design doesn't require data redistribution during horizontal scaling, but increasing vertical resources (CPU, RAM) significantly enhances processing power within a single node.
2. Limited Sharding Benefits: Unlike other distributed databases, ClickHouse doesn't rely heavily on sharding (dividing data across multiple nodes) for scalability. Adding shards involves complex rebalancing configurations and can introduce overhead without a proportional increase in performance.
3. Cost-Effectiveness: Vertically scaling by adding resources to existing nodes can be more cost-efficient than horizontally scaling by adding new nodes and managing a larger cluster infrastructure. However, vertical scaling also has limitations:
- Hardware Bottlenecks: Adding resources within a single node can eventually reach hardware limitations in terms of CPU, RAM, or storage capacity.
- Single Point of Failure: Larger nodes become single points of failure, requiring additional redundancy measures for high availability.
- Limited Parallelism: For extremely high workloads, even with increased resources, vertical scaling might not provide enough horizontal parallelism compared to a well-configured horizontally scaled cluster.
Clickhouse data partition is 'basic' and Query Planner isn't good
ClickHouse's data partitioning and query planner have received mixed reviews, with some considering them "basic" or needing improvement. Here's a breakdown of the potential reasons behind these critiques:
Data Partitioning:
- Limited Options: Compared to other database systems, ClickHouse offers a more limited set of partitioning options. While it supports range and list partitioning, features like hash partitioning and automatic repartitioning are currently unavailable.
- Manual Configuration: ClickHouse partitioning requires manual configuration at table creation time, limiting dynamic adaptation to changing data distributions.
- Impact on Query Performance: While partitioning can improve performance for certain queries targeting specific partitions, it might not be as effective for more complex queries involving multiple partitions or scans.
Query Planner:
- Cost-Based Optimizer (CBO) Limitations: While ClickHouse employs a CBO, its capabilities might not always translate to optimal execution plans for complex queries or specific data distributions. This can lead to suboptimal performance in some cases.
- Join Optimization: Join performance in ClickHouse has been a point of improvement, as the CBO might not always choose the most efficient join algorithm. Lack of support for dedicated join algorithms like shuffle joins also contributes to limitations.
Driving Greater Analytical Database Performance Through Open Source
The success of ClickBench is a testament to the the power of open source, both in how it brings together developer communities like StarRocks to take on new challenges, and in its fostering of open competition and innovation between projects. On a similar note, earlier this month, the StarRocks project was donated to the Linux Foundation, and we are sure the project will grow even faster in its new home.
Hats off to ClickHouse. It's an honor to compete with them. It pushes StarRocks to be a better project.
What do you think of StarRocks' latest achievement on ClickBench? Join the StarRocks Slack and share your thoughts.
