As we look back on 2025, we want to thank everyone who has been part of the StarRocks journey, helping advance real-time analytics for lakehouse and AI workloads. Your support and contributions made the year’s remarkable growth possible. Now, as we step into 2026, this is a good moment to reflect on the milestones that defined 2025 and to look ahead to what the coming year holds.
🚀 Engineering Highlights: A Breakthrough Year for Performance
Major Milestone: StarRocks 4.0 Release
StarRocks released version 4.0 on October 17, marking a significant step forward in both performance and usability. The release delivers approximately 60% faster query execution year over year on TPC-DS, reinforcing StarRocks’ position as a high-performance analytics engine.
This release significantly strengthens Apache Iceberg support, including hidden partition handling, faster metadata parsing, a new compaction API, and native Iceberg table writes. JSON is now treated as a first-class data type, enabling 3–15× faster out-of-the-box queries without the need for data flattening. In addition, real-time analytics becomes more cost-efficient through smarter compaction, metadata caching, and file bundling, reducing cloud API calls by up to 90%.
StarRocks 4.0 also introduces catalog-centric governance for Apache Iceberg and expands support for a broader range of workloads with features such as Decimal256, multi-statement transactions, and ASOF JOIN. Operational usability is further improved with node blacklisting, case-insensitive identifiers, and global connection IDs, making cluster management and debugging simpler and more reliable.
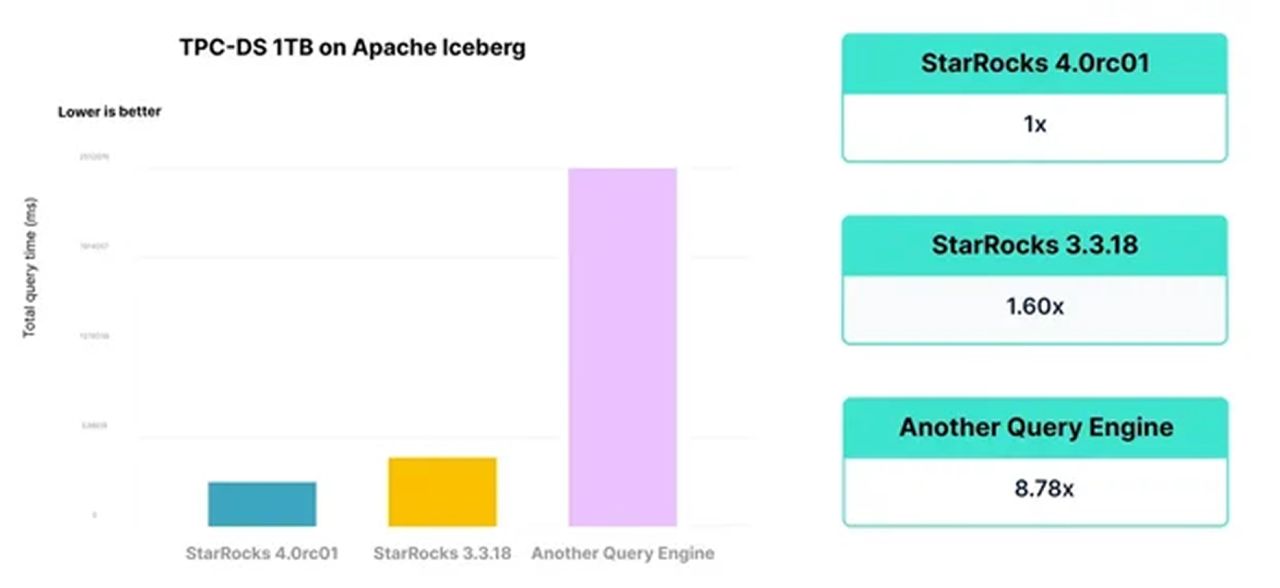
Apache Iceberg: From An External Lake Format to A Native Lakehouse Foundation
In 2025, StarRocks took a more deliberate and systematic approach to Apache Iceberg. Rather than optimizing individual features in isolation, we treated Iceberg as a first-class component of the lakehouse and focused on addressing real-world challenges such as performance stability, query slowdowns, and operational complexity. The goal extended beyond peak performance to delivering end-to-end predictability, allowing users to run mission-critical Iceberg workloads with confidence in production.
We began by improving how the optimizer understands lake data. By learning from real query execution, StarRocks reduced its reliance on incomplete metadata and generated query plans that more accurately reflect actual data distributions.
At the data access layer, the focus shifted toward stability and predictability.
Enhancements to caching and I/O behavior reduced performance variability caused by large queries, mixed workloads, and remote storage.
In parallel, more Iceberg-specific complexity was absorbed into the engine itself, making Iceberg tables behave much more like native tables for both querying and ingestion.
Finally, as Iceberg adoption expanded in production environments, StarRocks strengthened lifecycle management and security capabilities, improving traceability, maintainability, and overall enterprise readiness.
Materialized Views: A "Zero-Jitter" Acceleration Layer for Real-Time Lakehouse Workloads
In production systems, the real challenge is often not how fast queries run, but how predictable their performance is. Constant data changes, traffic spikes, and fragile caches can all lead to inconsistent query latency.
Recent StarRocks releases strengthened Materialized Views (MVs), positioning them as a reliable acceleration layer for lakehouse workloads. Multi-column partitioned MVs now align directly with Apache Iceberg and Hive table partitions, enabling efficient incremental refreshes and more consistent MV utilization.
For SLA-critical workloads, clearer MV rewrite behavior and options like
force_mv ensure queries reliably use precomputed results, while newly ingested data is incorporated in a controlled and predictable manner. As a result, performance consistency and data freshness become intentional design choices rather than incidental outcomes.Operationally, improved lifecycle management through partition-based retention policies keeps MVs compact, manageable, and cost-efficient over time.
Taken together, these changes turn MVs from ad-hoc optimizations into a dependable foundation for predictable, low-jitter lakehouse performance.
Real-Time Analytics
Real-time analytics was a major focus for StarRocks in 2025. From OLAP and lakehouse analytics to serving as the foundation for AI agents, delivering low-latency, real-time query performance has become more critical than ever.
At a high level, StarRocks' real-time analytics efforts can be grouped into three key areas:
Ingestion
-
Batching small writes into efficient transactions (Merge Commit).
-
Reducing compaction and small file overhead with Load Spill and file bundling.
-
Making real-time ingestion cheaper and more scalable on object stores.
Query Performance
-
Deep operator and optimizer enhancements for faster joins, aggregations, and spill handling.
-
Smarter caching and statistics for faster planning and execution.
-
First-class support for JSON and complex real-time data types and workloads.
Operational Reliability
-
Better partition lifecycle management (TTL, merging) for real-time/up-to-date analytics.
-
MV improvements for efficient incremental refreshes and query acceleration.
-
Plan stability tooling to reduce latency variance under real workloads.
Further reading:
🌍 Community Growth and Engagement

StarRocks community is growing faster than ever, with strong momentum across regional adoption and contributor activity. The Slack community has surpassed 5,000 members, and GitHub stars exceeded 11,000, reflecting increasing global interest in the StarRocks project. StarRocks now has 500+ contributors to the main GitHub repository, and the number of new PRs has remained steady, demonstrating a consistent level of development activity.
StarRocks Contributor Awards

StarRocks Awards 2025 marks our most comprehensive and internationally representative contributor recognition to date, honoring not only those who advance our technology and share real-world best practices, but also those who grow local communities and inspire others along the way.
👉🏻 See the full list: Meet Our 2025 StarRocks Award Recipients!
📍 Events & Meetups
StarRocks Summit 2025

In September 2025, we hosted our biggest virtual Summit thus far—StarRocks Summit 2025— with over 32 speakers from around the world, showcasing significant adoption and major performance breakthroughs.
Organizations including Coinbase, Pinterest, Intuit, and Demandbase shared how they achieved petabyte-scale, sub-second query performance while reducing infrastructure costs with StarRocks.
👉🏻 Watch on demand: StarRocks Summit 2025
Real-Time & Lakehouse Meetups
This year, StarRocks partnered with the Apache Iceberg community to explore how to build open, fast, and governed lakehouse architectures. Our journey took us across many cities in the U.S., connecting with practitioners and sharing real-world experiences.

Beyond the U.S., StarRocks maintained a strong presence across APAC and Europe, made possible by passionate community members who actively participated in and hosted local events.

🔭 Looking Ahead to 2026
As we look back and celebrate a year of progress, we also have several exciting initiatives planned for 2026:
Real-Time Analytics
Real-time analytics is one of StarRocks' key strengths, and an area where the product has built deep, proven capabilities. In the next phase, we will focus on further expanding this advantage by prioritizing the following areas:
-
Automatic tablet splitting to simplify operations and improve ease of use at scale.
-
Continued performance and efficiency improvements to further optimize real-time analytics workloads.
-
Enhanced system observability to give users deeper visibility into cluster health, performance, and runtime behavior.
Lakehouse
Our focus is guided by two core objectives:
- Deliver performance that is fast enough to run analytics directly on the lake.
- Be robust and capable enough to serve as a true replacement for traditional data warehouses such as Snowflake.
To achieve these goals, we will concentrate on the following priorities:
-
Continue investing in performance leadership, building on our strengths in fast query execution.
-
Expand from fast queries to end-to-end speed, ensuring inserts, deletes, and updates are equally efficient.
-
Support the full spectrum of data management operations, simplifying administration and day-to-day operations.
-
Achieve full support for all Apache Iceberg v3 table formats in the year ahead.
AI & Intelligent Optimization
We plan to embed AI-driven performance intelligence directly into the analytics engine. This includes building vector indexing and AI-assisted analytics capabilities. Together, these efforts will allow customers not only to run analytics efficiently, but also to explore AI-powered personalization, automation, and intelligent decision-making.
That’s the overall direction for 2026, though adjustments may be made along the way. If you have any suggestions or ideas, feel free to open a feature request on GitHub or discuss with the community in our Slack channel!
❤️ Get Involved
Join our thriving community:
-
Contribute to the project on GitHub
-
Join our Slack community
-
Follow us on LinkedIn and X (Twitter)
If you're interested in hosting a StarRocks regional meetup or partnering with us (on upcoming events), feel free to reach out to the community organizer: 📩 kate.shao@celerdata.com
