StarRocks 3.5 introduces a focused set of improvements across reliability, performance, and security. This release adds cluster-level snapshots for disaster recovery, optimized batch ingestion to reduce small files, more flexible partition lifecycle management, and multi-statement transactions for ETL workflows. It also brings performance gains for data lake queries through automatic global dictionaries, along with support for OAuth 2.0 and JWT to simplify authentication. This post highlights the most impactful updates in 3.5.
Cluster Snapshots for Backup and Recovery
StarRocks 3.5 adds built-in support for cluster-level snapshots in shared-data (compute-storage separated) deployments. This fills a key gap in backup and disaster recovery.
Snapshots automatically capture the full cluster state—catalogs, tables, users, permissions—and save it to object storage alongside your data. Only the latest snapshot is retained by default, minimizing storage overhead.
%EF%B9%96width=1928&height=1160&name=image%20(3).png)
Restoring is straightforward:
-
Point a new or existing cluster to the snapshot path in object storage.
-
StarRocks reloads metadata and reuses existing data files—no data copy needed.
-
Recovery completes in minutes, with minimal disruption.
This provides a low-cost, automated way to recover from failures or regional outages. It simplifies disaster recovery for teams running critical analytics workloads on StarRocks in shared-data mode.
Batch Ingestion Optimization: Reducing Small Files and Improving Query Performance
In StarRocks 3.5, batch ingestion is now more efficient and reliable, especially when handling large volumes of data. Previously, batch ingestions often produced many small files due to memory limits. These small files increased query overhead and triggered expensive compaction tasks. In some cases, queries right after ingestion suffered from instability or even failed due to these small file problems.
To address this, StarRocks 3.5 introduces a Load Spill mechanism:
-
When memory usage reaches a threshold during ingestion, intermediate data is spilled to disk in larger chunks.
-
The system can skip compaction entirely in many cases, since data is already well-organized.
| Data Volume & Mode | Load Spill Enabled | Ingest Time | Compaction | Query immediately after load |
| 100GB – Single Thread | No | 16.5 min | 8 min | 1.29 s |
| Yes (Local + S3) | 19 min | N/A | 0.15 s | |
| Yes (S3 Only) | 23 min | N/A | 0.12 s | |
| 1TB – Single Thread | No | 2h 15min | 34 min | 56.25 s |
| Yes (Local + S3) | 2h 42min | N/A | 0.72 s | |
| 100GB – 5 Parallel Loads | No | 33 min | 49min 30s | OOM |
| Yes (Local + S3) | 45 min | N/A | 0.52 s |
Key benefits:
-
Query performance is stable immediately after ingestion.
-
Compaction time and resource usage are significantly reduced.
-
Ingestion jobs are more reliable under concurrent or high-volume loads.
Smarter Partition Management: Simplify Lifecycle, Reduce Overhead
As tables grow, managing partitions becomes increasingly painful. Without proper controls, it's easy to end up with thousands of tiny partitions—slowing down queries, bloating metadata, and making data cleanup a manual chore.
StarRocks 3.5 introduces two key features to address these issues: time-based partition merging and automated partition TTL.
Time-Based Partition Merge
In many workloads, recent data is queried at a fine granularity (e.g. daily), while historical data is accessed less often and can be partitioned with less granularity (e.g. monthly). But previously, StarRocks required all partitions to use the same granularity—leading to excessive partition counts and slow planning.
With 3.5, you can now use
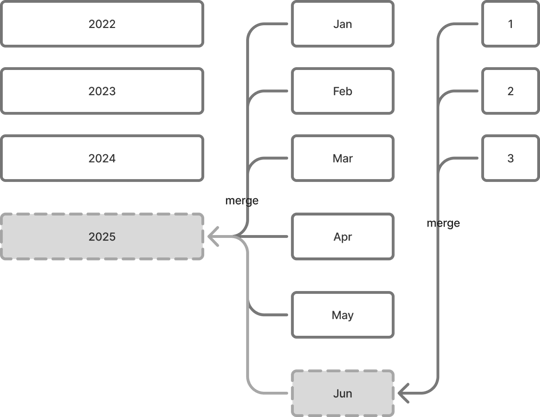
ALTER TABLE ... PARTITION BY <time_expr> to merge fine-grained partitions into coarser ones over a date range. For example, merge daily partitions from January into a single monthly partition. This results in:
-
Faster query planning with fewer partitions to scan.
-
Lower metadata and memory usage, especially on historical data.
-
A cleaner, more scalable partition layout aligned with access patterns.
Partition TTL: Automated Expiry Policies
Manually deleting expired partitions is error-prone and doesn’t scale. StarRocks 3.5 introduces a partition TTL policy that handles this automatically.
-
Define
partition_retention_condition(e.g. keep the last 3 months). -
StarRocks will regularly evaluate the rule and drop old partitions without intervention.
-
Works with all partition types—range, list, and expression-based.
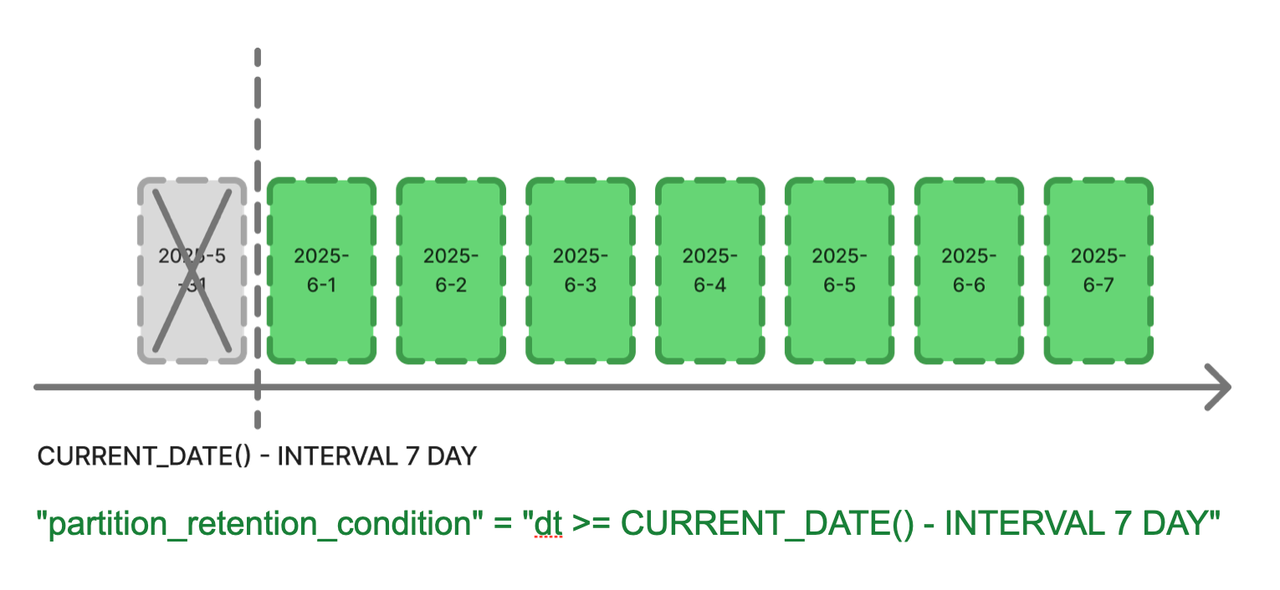
You can update TTL policies at any time using
ALTER TABLE, and you can still manually delete partitions with a WHERE expression for special cases.ALTER TABLE t1 DROP PARTITIONS WHERE dt < CURRENT_DATE() - INTERVAL 3 MONTH;
More Flexible Materialized Views
Materialized views (MVs) are essential for accelerating queries, but managing them at scale hasn’t always been easy—especially when working with partitioned or tables managed by external catalogs. StarRocks 3.5 introduces improvements that make MVs more flexible, lightweight, and aligned with actual usage patterns.
Challenges with Previous MVs:
-
Only one partition column was supported, limiting compatibility with multi-column partitioned tables.
-
MVs could grow large and stale over time without automated cleanup.
What’s New in 3.5:
-
Multi-column partitioning MVs can now inherit multiple partition columns from the base table (e.g.,
date,region). This ensures:-
Better alignment with both internal and lakehouse (Iceberg/Hive) tables.
-
More efficient refreshes and partition pruning.
-
- Partition TTL support Define retention policies for MV partitions using the same TTL mechanism as base tables to automatically remove old partitions during refresh.
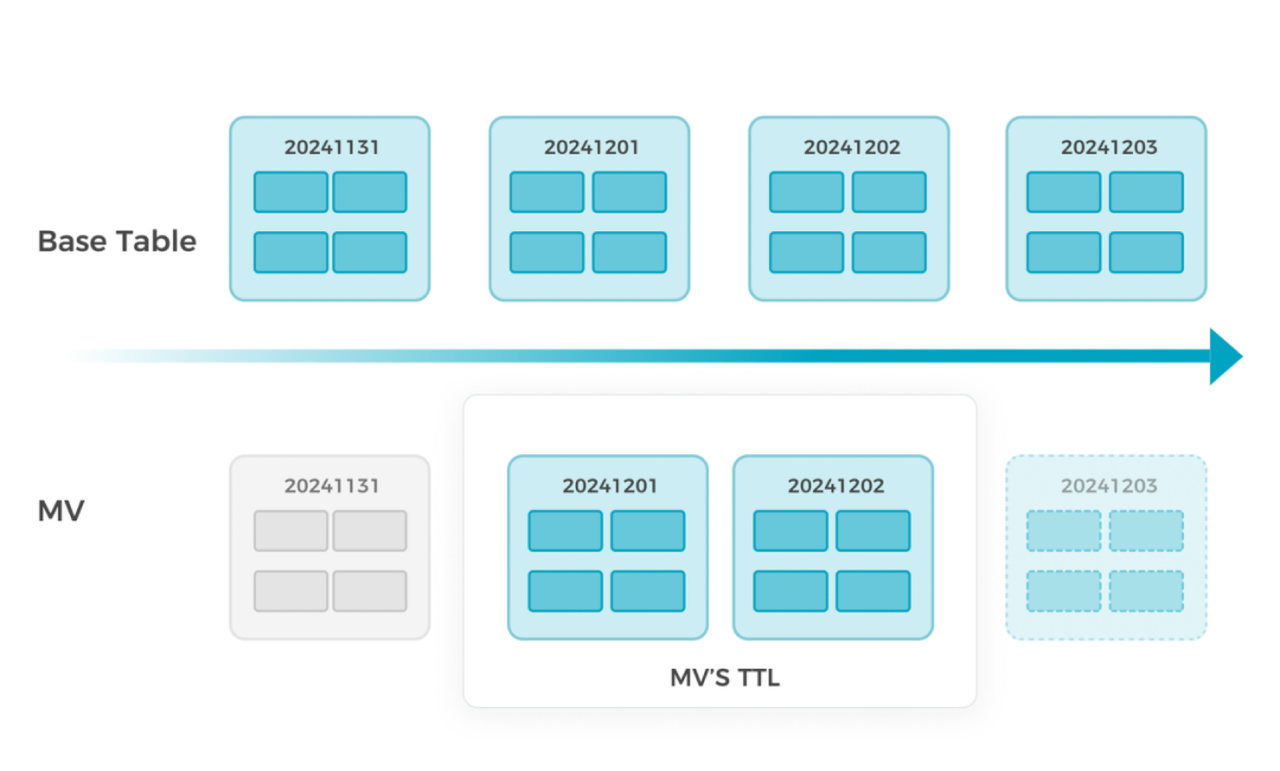
Benefits:
-
Focus materialization on recent hot data (e.g., last 7 days).
-
Cheaper and more frequent statiscs collection, better query performance
-
Reduce storage usage and refresh time
These enhancements let you build MVs that are smaller, faster, and easier to manage—without giving up on flexibility or correctness.
Multi-Statement Transactions for INSERTs
Before StarRocks 3.5, migrating multi-step ETL workflows was tricky—if one step failed, there was no way to roll back intermediate writes. This made error handling brittle and recovery expensive.
StarRocks 3.5 introduces multi-statement transaction support (Beta), allowing a group of
INSERT operations to run atomically using standard BEGIN; ... COMMIT; or ROLLBACK; syntax.
Key benefits:
- All statements succeed or none are applied—no partial writes.
- Rollbacks are clean and fast—no manual cleanup required.
This makes it much easier to build and maintain pipelines. While support is currently limited to
Accelerating Data Lake Analytics with Global Dictionaries
INSERT statements, it sets the foundation for more comprehensive transactional workflows in future releases.Accelerating Data Lake Analytics with Global Dictionaries
Querying Iceberg or Hive tables often involves scanning wide Parquet files with low-cardinality string columns—like
country, category, or gender. These columns are small in value range but still expensive to process, since string comparisons are slower and more memory-intensive than numeric ones.StarRocks 3.5 introduces automatic global dictionaries for external Parquet and ORC tables, bringing the same performance benefits previously available only to internal tables.
Why it matters:
- Reduces CPU and memory usage when scanning repetitive string columns.
- Speeds up filters, joins, and group-bys by replacing strings with integers.
- Works out of the box—no manual setup or tuning required.
|
Query
|
Scenario
|
OFF (ms)
|
ON (ms)
|
Speedup
|
|
q01
|
Count distinct on 1 low-cardinality column (<50)
|
623
|
177
|
3.52×
|
|
q12
|
Group by 1 low-cardinality column (<50)
|
647
|
180
|
3.59×
|
|
q36
|
Group by 2 low-cardinality + 1 high-cardinality int (200–256)
|
16179
|
6687
|
2.42×
|
|
q40
|
Group by 2 low-cardinality + 1 date column (<50)
|
1196
|
533
|
2.24×
|
|
q41
|
Group by 2 low-cardinality + 1 tinyint column (<50)
|
1038
|
407
|
2.55×
|
|
q46
|
Group by 7 low-cardinality columns + function (<50)
|
5654
|
2813
|
2.01×
|
|
q58
|
Decode before order by
|
470
|
178
|
2.64×
|
In a benchmarks on a 100GB Iceberg dataset, enabling this optimization improved query performance by 2.6× on average on workloads involving low-cardinality columns.
This feature helps close the performance gap between internal and external tables, making it easier to run fast, customer-facing queries directly on your data lake.
Enterprise-Ready Security and Authentication
Security and integration with enterprise identity systems are critical for production deployments. StarRocks 3.5 introduces several updates that make it easier to plug into secure environments:
- OAuth 2.0 and JWT support Authenticate users through standard identity providers—ideal for integrating with IAM platforms or token-based workflows.

- Security Integration with LDAP and group-based access StarRocks can now pull user and group information from external directories (LDAP, OS, or files), enabling consistent role-based access control across systems.
- SSL for MySQL protocol Encrypt client connections to meet security and compliance requirements.
These improvements reduce the effort required to manage access securely and make it easier to align StarRocks with existing authentication and authorization policies across the organization.
Conclusion
Conclusion
StarRocks 3.5 delivers a wide range of improvements across ingestion, query performance, partitioning, materialized views, security, and more. For full details, check out the release notes.
We encourage you to upgrade and explore what’s new. Have questions or feedback? Join the community on Slack — we’d love to hear from you.
