Zepp Health is a cloud-based health service provider that has world-leading smart wearable technologies. Zepp Health's vision is to create smart products that promote a healthy lifestyle.
At Zepp Health, a huge amount of event tracking data is generated every day. Previous Apache HBase® computation and analytics system is inefficient and inflexible in dealing with queries against data at such a large scale. During event tracking data analysis, users often query metrics in a single dimension or a combination of multiple dimensions. The dimension can be time, event name, city, or device attribute. The metric can be the number of users and the number of times an event is tracked.
In face of such massive event tracking data, how to flexibly and efficiently compute dimensions and metrics is an issue worth exploring. Building an event tracking analytics platform on top of an efficient OLAP engine has become an important part of business development.
Original Solution and Pain Points
In the original solution, to analyze event tracking data, engineers need to collect metric statistics, use Apache Spark™ or Apache Hive™ to pre-calculate metrics such as page views (PVs) and unique views (UVs), and then write the pre-calculated data to Apache HBase for point queries.
This solution has the following three drawbacks:
- Data in Apache HBase is stored as key-value pairs, which can only be used for point queries. Complex analytics is impossible.
- Bitmap-related technologies cannot be used. Engineers have to compute the required metrics in advance, which is not flexible and not suitable for set operations.
- The data processing link is long and hard to maintain. Model abstraction is not supported. All these complicate business upgrade.
Why We Choose StarRocks?
To address the problems and challenges at the data storage layer, we are looking for a high-performance, simple, and easy-to-maintain database product to replace the existing Apache Spark + Apache HBase architecture. In addition, we hope to go beyond point queries of Apache HBase® and use real-time multi-table joins to cultivate more business possibilities.
There are a variety of OLAP database products on the market, including Apache Impala®, Apache Druid®, ClickHouse, and StarRocks. After comprehensive and thorough comparison, we find that StarRocks stands out among many products thanks to its outstanding read/write performance. In addition, the active and inclusive community ecology offered superior development and user experience. So we choose StarRocks as the OLAP engine to replace Apache HBase.
| Product | Advantage | Disadvantage | O&M cost | Performance |
| ClickHouse |
|
|
High | High |
| StarRocks |
|
|
Low | High |
| Apache Impala |
|
|
Medium | Low |
| Apache Druid |
|
|
High | Medium |
StarRocks is a blazing-fast enterprise-grade massively parallel processing (MPP) database designed for all analytical scenarios. It offers a mix of innovative features, including online horizontal scaling, finance-grade high availability, compatibility with MySQL protocol and MySQL ecology, fully vectorized engine, and query federation on various data sources. StarRocks provides a unified solution for OLAP services in all scenarios. It is suitable for various scenarios that have demanding requirements for performance, real-time analytics, concurrency, and flexibility.
Reconstruction Using StarRocks
Architecture Design
Description of the overall architecture:
- Event tracking data flows from API Gateway to Apache Kafka®, and is cleansed, filtered, and transformed using Apache Hudi on Apache Flink®. The OLAP preprocessing layer is built upon streaming data lake.
- The data warehouse detail (DWD) layer is built based on Apache Hudi's Upsert or Append write mode. Using either write mode depends on data characteristics, desired write performance, and cost considerations.
- Data is processed offline at scheduled time and is then transferred to the Data Warehouse Summary (DWS) layer.
- DWS data is imported to StarRocks offline at scheduled time for cost optimization.
- Data in StarRocks is queried using a unified query & analytics platform.
Data Processing
The detailed process is as follows:
- Transform original data and insert data into Apache Hudi using the Upsert or Append mode based on data characteristics (Business data that is not sensitive to duplication is directly written to Apache Hudi in Append mode).
- Use a broker load to write data into the aggregate key model with Bitmap fields to generate Bitmap data.
- Perform customized set operations on Bitmap data based on business requirements (data such as PV and UV are generated in this step).
- Users run self-service queries to query metrics on the query & analytics platform.
Performance
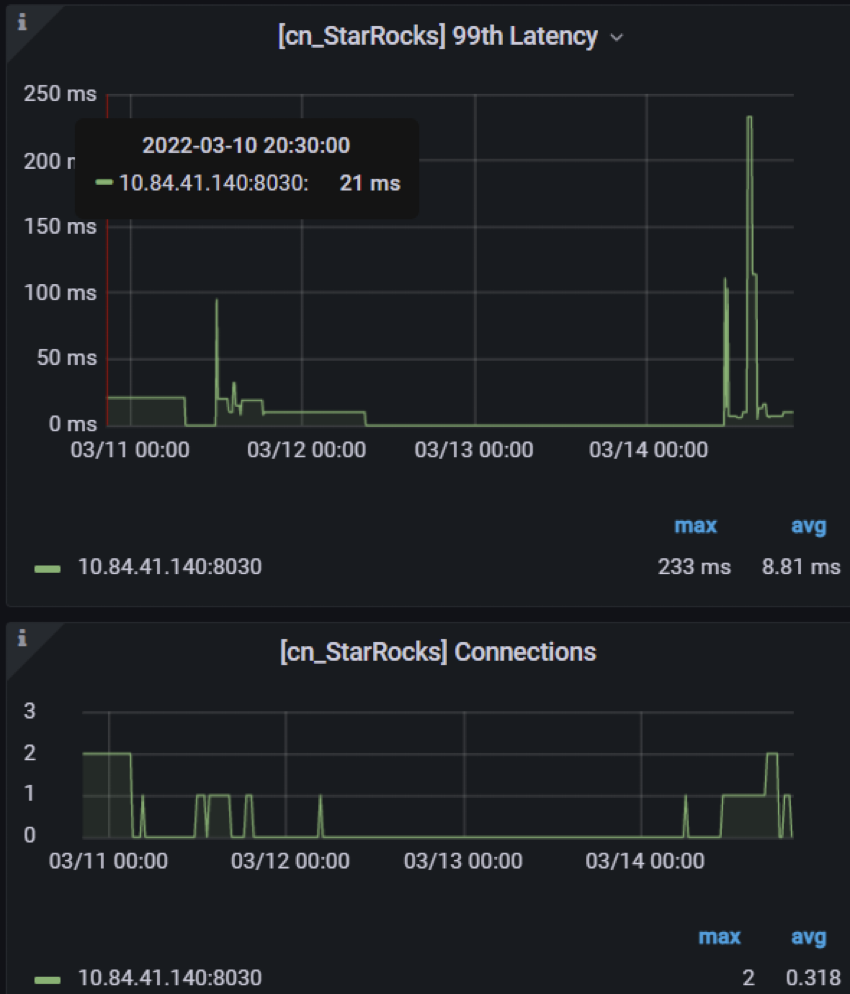
StarRocks' monitoring platform shows that the average query latency is about 100 ms, and the P99 latency is about 250 ms, which fits our business needs well.
Reconstruction Results
- Efficient
The system can quickly respond to users' query needs. The latency of large queries is reduced from minutes to seconds.
- Flexible
Users can analyze metrics in a combination of dimensions and time periods. There is no need to pre-compute redundant metrics.
- Low storage cost
StarRocks has an efficient storage structure, which reduces the cost of storing the same volume of data by 20%.
- Simple
StarRocks is easy to O&M, which reduces the maintenance labor cost compared to ClickHouse.
- Easy to use
Users can perform self-service queries. The data retrieving experience is improved. The latency of point queries against some metrics has been reduced from minutes to seconds, and even to milliseconds for some metrics.
Community Co-building
An open and thriving community is also an important reason why we choose StarRocks. An open community helps users quickly learn product features and ensures timely problem resolution. We at Zepp Health are also actively engaged in community building. We hope that by giving back to the community, we can grow and thrive together with the community. We contributed the following feature improvements, which have been merged into the main branch of the StarRocks community:
- Fixed bugs that occur when users create materialized views in StarRocks.
- Extended StarRocks' support for more object storage types during data import.
- Enriched parameter configurations in some data import scenarios.
Summary and Outlook
When we reconstruct the Zepp Health big data OLAP platform, we have close communication with the StarRocks community in business implementation and problem tracking and resolution. The platform is impossible without the support from the StarRocks community.
The Open & Collaborate community spirit not only drives efficient resolution of tricky problems but also enhances the technical skills of all community participants.
StarRocks is an excellent OLAP product. Zepp Health is willing to use and grow with StarRocks. In the future, we will continue to engage in community building and make our share of contribution. We have the following improvement plans:
- Currently, to generate Bitmap data, engineers must incrementally import detailed data into the aggregate key model. Parquet files of Bitmap fields cannot be directly imported into StarRocks, which is not efficient in heterogeneous storage scenarios. Zepp Health's big data team is collaborating with the StarRocks community to work out a solution. For details, see https://github.com/StarRocks/starrocks/issues/3279.
- Connect more workloads to the OLAP platform and leverage StarRocks in more smart wearable health scenarios.
Apache®, Apache Spark™, Apache Flink®, Apache Hadoop®, Apache Hive™, Apache Druid®, Apache Hudi, Apache Impala®, Apache HBase®, and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
