Xiaohongshu runs a lifestyle-sharing platform. Users can record every day of their lives in short videos and pictures and share them on Xiaohongshu. Since 2017, we have experienced explosive growth in business and registered users. This presents an opportunity for us to optimize our data analytics and application systems, such as business intelligence, dashboards, user behavior analytics, and policy-based algorithms. Our big data team introduces various OLAP analysis engines including StarRocks, which helps us develop an advanced and integrated data analysis platform and empowers us to simplify data processing and handle highly concurrent requests.
Journey of Improving OLAP Engines
Stage 1: Before 2017, our data volume was not large and we used AWS Redshift for data storage and computing. At that time, our data warehouse system was not fully established, and most data requirements were implemented in a short and fast way. The entire process of ETL, data modeling, and dashboard creation is completed by Redshift alone.
However, as our business complexity and data amount increase, this pattern soon encountered a bottleneck. The main problems were as follows:
- Redshift can not achieve auto-scaling without compromising online SQL query performance. That means auto-scaling may cause data redistribution and compromise the performance and availability of clusters.
- Parallel ETL operations may severely undermine the availability of clusters. When multiple ETL tasks run in parallel on Redshift, these tasks may preempt resources, which reduces data analysis efficiency and causes queries to time out. Even worse, the entire cluster might become unavailable due to overload.
- The lack of a storage-compute separation architecture results in bottlenecks in storage capacity, which cannot accommodate the increasing amount of business data.
Stage 2: During this period, we developed a data warehouse framework on top of Apache Hadoop® and Apache Hive™ and ran ETL tasks entirely on Apache Hadoop clusters. We use Presto as the OLAP analysis tool, which is a distributed system that runs on Apache Hadoop. Presto uses the Apache Hive metastore service to access data in a Apache Hive data warehouse through pluggable Apache Hive connectors.
Stage 3: As real-time business and data applications keep advancing, a growing demand for high-performance databases emerges. We used ClickHouse to build a robust and high-speed data analysis platform to support real-time queries.
Stage 4: Our big data team has decided to redesign and rebuild the entire architecture of real-time data warehousing. They also plan to build a unified data service platform that can be accessed from various internal and B2B applications. This platform has high requirements on low-latency, high-concurrency, and complex queries. StarRocks becomes our best choice in achieving this goal.
Current Data Analysis Architecture
Our data analysis architecture consists of four layers: data collection, data storage and processing, data analysis, and data application.
Data Collection Layer
- Website event tracking data that is pulled by Apache Flume™ from server logs and app logs is distributed to Amazon S3 and Apache Kafka®.
- Data changes in MySQL binary logs are captured by Canal, an open-source middleware developed by Alibaba Group.
Data Storage and Processing Layer
- Offline data processing: We use Apache Hive and Apache Spark™'s high scalability and batch processing capability to perform ETL operations and data modeling in offline data warehouses. We also use scheduling tools to pull offline tables into ClickHous or StarRocks.
- Online data processing: Apache Flink® helps build a streaming ETL pipeline where data can be enriched, joined, and aggregated in real time. Data from ETL pipelines can be synchronized through Apache Flink connectors to ClickHouse or StarRocks.
Data Analysis Layer
This layer provides data storage and database services to store offline and real-time data and allows users to query data. The database services used at this layer mainly include TiDB, Apache HBase®, ClickHouse, and StarRocks. StarRocks and ClickHouse provide high-speed and effective OLAP queries, which ensures high-performance for data applications, such as dashboards, ad hoc queries, API, and various data products (for example, traffic analysis and user profiling).
Data Application Layer
The layers above lay a good foundation for diversified and user-friendly data applications. Various reports and dashboards at the data application layer enable managers and operations staff to obtain data more easily and intuitively. This meets the requirements for high-concurrency, low-latency queries. What's more, complex ad-hoc queries on enormous datasets are of great help to data analysts.
Comparison of OLAP Databases
Function comparison
| ClickHouse | StarRocks | TiDB | |
| Scenarios | Analysis of log data and data in flat tables | Analysis of real-time data for various data applications | Data analysis in OLTP and OLAP scenarios |
| Limits |
|
|
|
Advantages and disadvantages
| ClickHouse | StarRocks | TiDB | |
| Advantages |
|
|
|
| Disadvantages |
|
|
|
StarRocks Powers Advertising Analytics for Xiaohongshu
Scenario Description
Core advertising data in Xiaohongshu consists of two parts. One part is advertising exposures, click-through rate (CTR), and actual purchasing. The other part is attribution data, such as order conversion rate (OCR) and post engagement rate (metrics like followers, comments, and likes).
Xiaohongshu needs to use these two types of data to perform real-time and multidimensional business analytics.
Previous Solution
Previously, to analyze advertising data, we rely on Apache Flink to write massive unstructured data into separate OLTP and OLAP databases, such as MySQL, Redis, HDFS, and ClickHouse. Apache Flink played a vital role in complex data processing, such as the following:
- Perform JOIN operations on data streams, such as news feed ads and ads from algorithm-based recommendations.
- Detect and prevent commercial cheating.
- Write aggregate data in different scenarios to different databases.
This solution has the following drawbacks:
- It is difficult to aggregate complex and disorganized data.
- ClickHouse is not suitable for high concurrency scenarios and the storage capacity cannot scale on demand, which presents a challenge for the future.
- Complex Apache Flink jobs cannot ensure high availability.
Solution Offered by StarRocks
We hope to optimize our advertising analytics by building a well-organized OLAP system, which is capable of providing the following features:
- High throughput
- Support for multidimensional queries
- TP99 latency less than 100 ms
- Materialized views
- Capable to handle over 10,000 QPS
- Capable to extract data from MySQL binary logs in real time and offer data encapsulation
- Support for multiple-table join
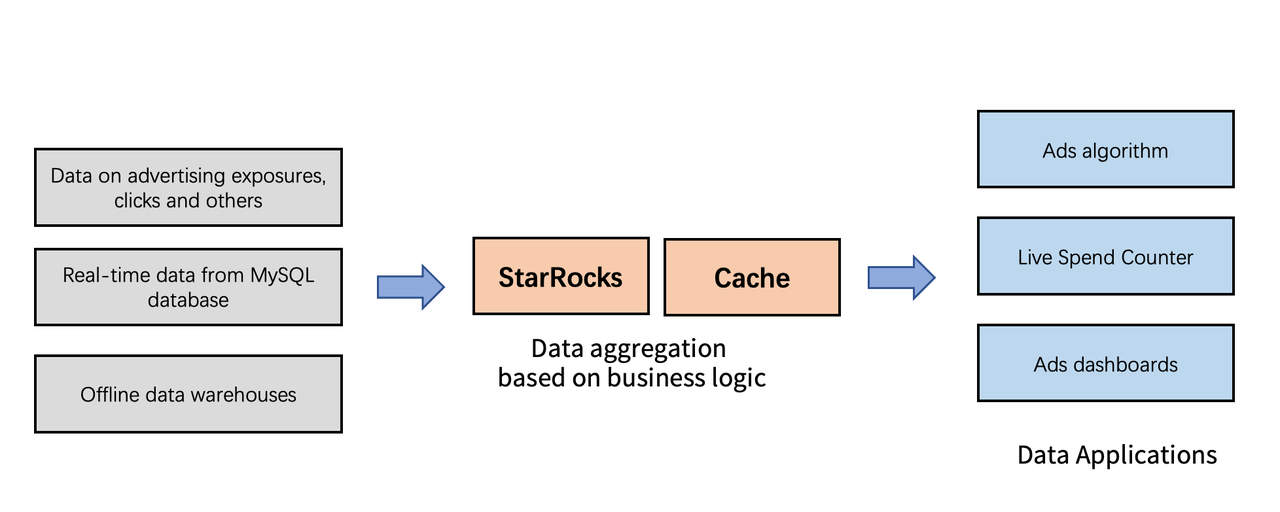
After conducting lots of research, we believe StarRocks is the best choice. StarRocks is built on high-performance engines, which serve as integrated data analysis platforms for ads algorithms, Live Spend Counter, and ads dashboards. StarRocks has the following advantages:
- Well-designed data processing architecture. Apache Flink focuses on data cleaning. The business logic implementation is moved from Apache Flink into StarRocks.
- Unified and consistent advertising statistics through standardized data ingestion and transformation platform.
- High QPS. The dual-active architecture can better support high-QPS workloads.
Database Design
Data Model
StarRocks provides three data models: duplicate key model, aggregate key model, and primary key model. These models are suitable for different advertising analytics scenarios.
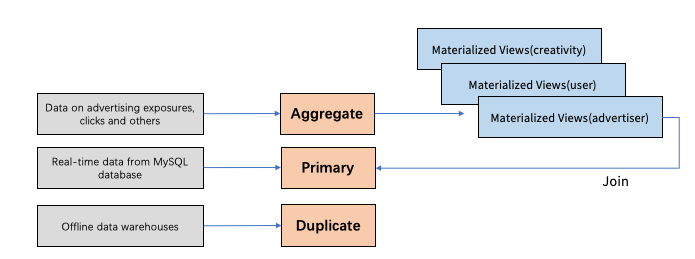
- Data on advertising exposures and clicks are written to the aggregate key model. This model helps pre-aggregate data of multiple dimensions and generates metrics on demand during the query process. Dimensions are data attributes with non-quantitative values, such as advertisers, ad types, ideas, ad units, search keywords, regions, and user attributes.
- The primary key model is responsible for updating real-time ads data extracted from MySQL databases.
- The duplicate key model can process data from offline data warehouses.
Partitioning and Bucketing
StarRocks partitioning and bucketing split ads data into a more manageable size and improve query efficiency and performance.
For example, if recent data is queried most frequently, we can use a DATE or DATETIME column as the partitioning column. If we want to find information about some advertisers, we can specify advertiser ID as the leading column for the sort key. Hash buckets in StarRocks break data down into ranges based on the hash value of one or more columns, such as advertiser ID.
Materialized Views
Materialized views provided by StarRocks can be constructed in real time or in batches, added and deleted on demand, and used in a transparent way. We create materialized views at various granularities, such as advertisers, user attributes, advertising units, and ideas. These materialized views significantly accelerate queries.
Data Ingestion
Real-time data is ingested to StarRocks in the following two ways:
- For data that is processed by ETL jobs, Apache Flink is used to convert the processing logic of such data and write the data to StarRocks by using the StarRocks connector for Apache Flink.
- For data that is stored in real-time data warehouses, StarRocks Routine Load directly schedules one batch of such data to StarRocks every 10 seconds.
Offline data ingestion to StarRocks:
StarRocks encapsulates a data importing template into the scheduling platform of Xiaohongshu based on native Broker Load. This template can be used to import data from offline data warehouses into StarRocks in a visualized way.
Data Query
StarRocks is a massively parallel processing (MPP) database that distributes data into partitions by range and hash partitioning. It is suitable for highly concurrent queries for advertisers.
The stress testing results show that each frontend node of StarRocks can handle 2,000 QPS. The entire cluster can handle more than 10,000 QPS, and the TP99 latency is less than 100 ms.
Maintenance
StarRocks provides high availability and scalability, which makes it ideal for our ads data center. Its architecture consists of distributed frontends and backends and supports data replication, which ensures high reliability in case of node failures. It also supports auto-scaling without downtime, which is vital to our business.
Conclusion
Since 2021, we have been using five StarRocks clusters to support our advertising analytics system. Two of them have already been providing stable online data analytics services, while other clusters are put into trial operation. StarRocks helps us develop an integrated data analysis platform and simplifies real-time data processing to meet the requirements for high concurrency and low latency. Our company is looking forward to deploying StarRocks in more business scenarios. We appreciate the substantial support from StarRocks and sincerely wish StarRocks a prosperous future.
Apache®, Apache Spark™, Apache Flink®, Apache Kafka®, Apache Hadoop®, Apache Hive™, Apache ZooKeeper™, Apache HBase®, Apache Flume™ and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
