About the author: VBill Payment is a leading third-party payment company. Its ‘payment + finance’ model supports consumer finance, supply chain finance, new retail, and industry-specific payment solutions.
Overview
Business Background and Challenges
We initially adopted a Lambda architecture combining offline databases and Hive with real-time Elasticsearch, HBase, and Kudu. As transaction volumes grew, however, this design exposed multiple performance and maintenance bottlenecks:
- Poor data timeliness: The separation of offline and real-time clusters led to long data processing pipelines. Complex queries required cross-cluster joins, making efficient, real-time responses difficult.
- High cost of data redundancy: Similar data had to be stored and maintained in multiple systems, resulting in redundancy and higher costs for storage resources and synchronization.
- Complex architecture, poor stability: The multi-component stitched system increased coupling and complexity, making operations and maintenance difficult and leaving stability unguaranteed during business peaks.
These issues slowed the growth of key business areas — from cashier products and service platforms to risk control and compliance — prompting us to launch a transformation initiative.
Business Pain Points
- Insufficient query performance: Response times were too long for complex, multidimensional analytical queries.
- Delayed data timeliness: In certain scenarios, the existing architecture could not achieve T+0 updates.
- Poor system stability: The underlying architecture consisted of heterogeneous components, resulting in high deployment and maintenance costs.
- Inconsistent data accuracy: Dispersed data sources and complex processing pipelines resulted in inconsistent metrics.
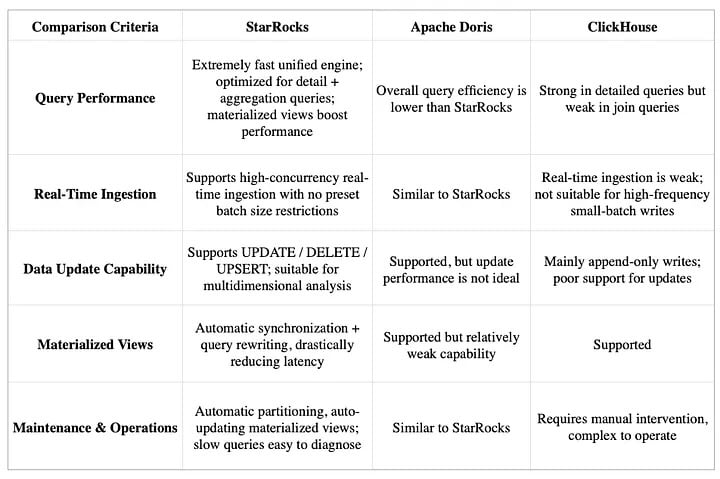
Why StarRocks?
During our research and testing, we compared StarRocks with other mainstream OLAP engines such as Apache Doris and ClickHouse. StarRocks outperformed in several critical areas, offering significant advantages:
Current Application of StarRocks at VBill Payment
To meet the needs of real-time data ingestion, processing, and diverse query scenarios, we built a new real-time architecture based on Porter CDC, StarRocks, and Elasticsearch- replacing the previous stack of OLTP databases, Kudu, HBase, and Hive.
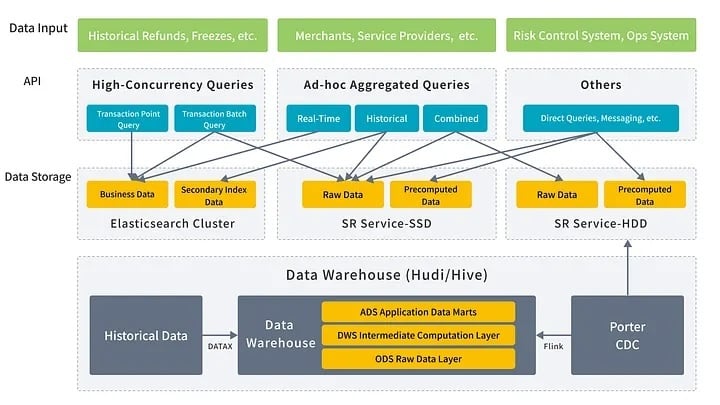
Data Ingestion
In scenarios where transaction data changes frequently, traditional solutions (e.g., ClickHouse, Hive) showed clear shortcomings in handling historical data updates, struggling to meet high concurrency and strong consistency demands. To solve this, we introduced the StarRocks Primary Key table, which demonstrated strong capabilities for large-scale updates, greatly improving efficiency and stability of the ingestion system.
By leveraging our self-developed Porter tool, we achieved second-level multi-source log ingestion, and combined with Flink for high-throughput, low-latency streaming, we built a highly timely and consistent ingestion pipeline. The system now supports millions of records ingested into StarRocks per minute, stably powering a high-concurrency ODS (raw data) layer.
To further enhance stability and ingestion performance, we optimized around StarRocks with:
Dynamic field updates:
- Porter extracts only changed fields from database logs, reducing database pressure.
- Deep optimization of Flink connectors enabled dynamic column updates.
- CDC logs are merged in advance, reducing Merge-on-Read (MOR) pressure, lowering overall write I/O by ~30%.
Configurable synchronization:
- Extended Flink connectors to support multi-table sync within a single task:
- Enabled configuration-based ingestion, boosting development efficiency.
- Added throttling and monitoring, ensuring data stability and accuracy.
Offline sync acceleration:
- Rebuilt offline ingestion pipeline to address performance bottlenecks in traditional database-based historical ingestion.
- Leveraged StarRocks EXPORT to connect efficiently with the data lake, improving performance by over 10x.
- Used INSERT INTO FILES for a more unified and user-friendly export interface.
Data Query
Based on business scenario characteristics and query patterns, we classified workloads into three categories and applied StarRocks’ differentiated capabilities for precise optimization:
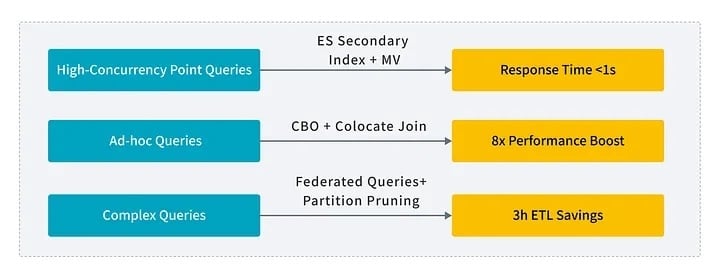
High-Concurrency Detail Queries (use cases: refund history, merchant lookups): We replaced the traditional DB + Impala + Kudu setup with StarRocks to handle large-scale historical data and meet ultra-low-latency, high-concurrency demands. Key optimizations included:
- Migrating to StarRocks for unified real-time query performance.
- Adopting SSD storage for Primary Key tables to ensure stable concurrency.
- Introducing asynchronous materialized views, achieving millisecond responses on 30 TB datasets (20× efficiency gain).
- Integrating Elasticsearch secondary indexes for flexible multi-condition filtering.
Ad-hoc aggregation queries (use cases: risk control rules, dashboards, ad-hoc queries):
- Deployed HDD-based StarRocks clusters for cost-efficient large-scale analytics.
- Applied Aggregate Key table to pre-aggregate metrics at ingestion.
- Used Colocate Join for fact-dimension tables, improving join performance 3x.
- Tuned the CBO optimizer, reducing query plan generation time by 80%.
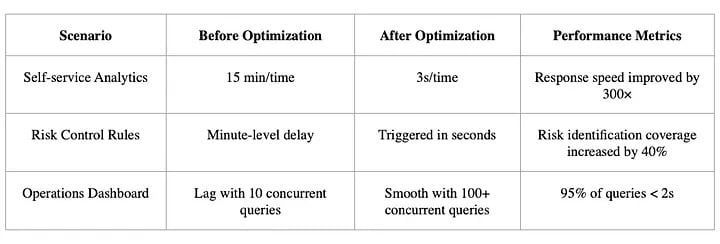
Batch processing optimization (use cases: dimension table computation, periodic reports, complex aggregation):
Such computation tasks typically have high requirements for stability, processing efficiency, and resource utilization. On top of the new architecture, we further enhanced the following core capabilities:
- Replaced Hive-based offline pipelines.
- Applied dynamic partition pruning + predicate pushdown, cutting scan volumes by 73%.
- Optimized compaction strategy for faster version merges.
- Implemented multi-tenant resource isolation with StarRocks for better stability under concurrency.
- Built an end-to-end monitoring system with Grafana for sub-5s alerts.
- Optimized BE parameters for lifecycle and compaction, reducing load and ensuring timely completion.
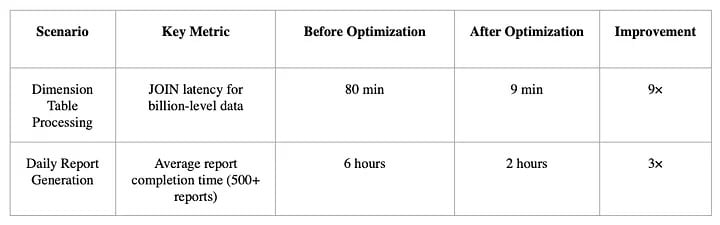
Through these optimizations, we not only replaced Hive + traditional DB batch pipelines but also built a unified, high-performance offline computing platform.
Key Benefits After Introducing StarRocks
With StarRocks as the core analytical engine, VBill Payment reshaped our big data service architecture, achieving significant improvements:
Real-time query breakthroughs
- Supported transaction data growth from 3 billion to 30 billion records while maintaining millisecond response times.
- Query response time improved 3x, with P95 < 1s and P98 < 3s.
- Stability and responsiveness ensured even under high concurrency.
Improved analytical efficiency, accelerated decision-making
- Historical multidimensional and cross-domain analysis reduced from hours to minutes, improving efficiency 10x.
- RPT report generation time shortened by 3+ hours, shifting from “waiting for data” to “real-time access.”
Simplified architecture, reduced costs
- Replaced multiple heterogeneous systems (Kudu, HBase, ClickHouse) with StarRocks.
- Reduced cross-system debugging; failure recovery time cut to <5 minutes.
- Reduced redundant storage by 20%, improving stability and efficiency.
Second-level data ingestion
- Upgraded to a Flink + StarRocks ingestion pipeline with high throughput, low latency, and strong stability.
- P99 end-to-end latency kept under 1 second.
- Transitioned from offline-first to real-time-first ingestion.
Future Plans
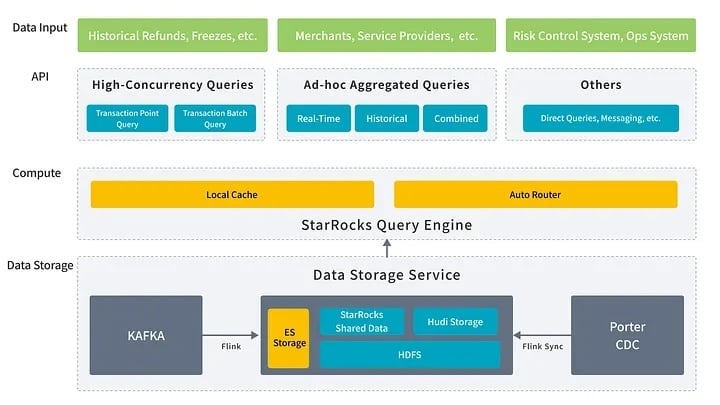
Building on this foundation, we will continue to advance our real-time data warehouse system, creating a unified data service interface that enables end-to-end automation and standardized management from data ingestion and processing to analytics. Ultimately, our goal is to realize a fully integrated architecture of “unified lakehouse, unified queries, and unified services,” delivering first-class digital infrastructure for the data-driven economy.
