Tencent Games has managed to unite petabytes of valuable data once siloed across its subsidiaries and products with the help of Apache Iceberg. In this talk, Hongli Chang, backend software development engineer at Tencent Games walks attendees through the technical journey the engineering teams at Tencent Games took to unify their gaming data and how Apache Iceberg + StarRocks was the lakehouse architecture capable of making this monumental feat possible.
Original Architecture
Initially, Tencent’s game logs were stored in a Hadoop File System, while application-layer data was dispersed across traditional databases like MySQL and PostgreSQL. Real-time data was stored in Druid. This storage scheme made data usage difficult and often created bottlenecks in accessing data.
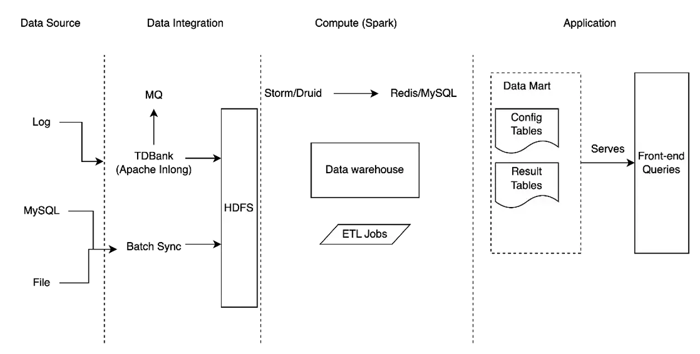
Managing two separate data pipelines for real-time and batch was complex and costly. For querying, all data first had to be pre-processed, including pre-aggregation and denormalization in Hive, before moving to PostgreSQL for reporting and dashboards. This process was complex and a waste of computing and storage resources, locking the data into a rigid single-view format: any schema change required reconfiguring the pipeline and data backfilling.
Challenges
Faced with the growth of trillions of data points daily, the gap between the scale of data and cluster capacity widened. A new system was greatly needed. The new system required:
- Sub-second query latency
- The ability to store and manage petabytes of data
-
Low operational overhead: With simple operation and maintenance
The New Architecture
After researching for different solutions, Tencent found that Iceberg could meet their needs. Iceberg is an open table format for analytics that supports schema evolution, hidden partitioning, time travel, and version rollback. These features enable data warehouse workloads to be unified on a single copy of data in open formats, allowing for easy data governance and simple architectures.
To achieve second-level query and data freshness, Tencent uses StarRocks as the query engine and the real-time ingestion layer. StarRocks is a blazing-fast, massively parallel processing query engine with features such as:
- Fully vectorized engines
- High concurrency support
- Real-time analytics on mutable data
- A simple architecture: consisting of only two types of processes: FE (Front End) and CN (Compute Node)
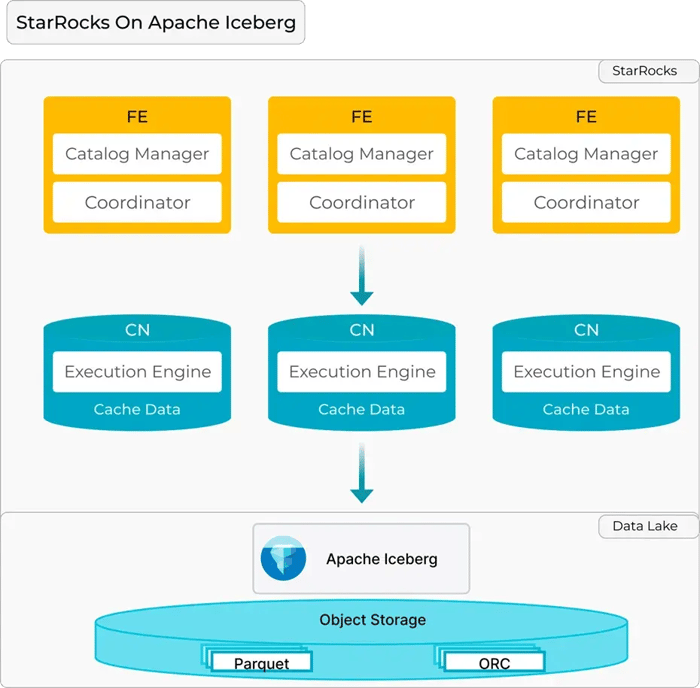
With Apache Iceberg and StarRocks, Tencent Games was able to develop a lakehouse architecture with the following capabilities:
- Simple and scalable architecture for trillions of records of new data per day
- Second-level query latency on petabytes of data
- Second-level data freshness with mutable data persisted in Apache Iceberg
Here are some additional features and optimizations that Tencent Games has built to achieve these impressive results.
Cloud Native
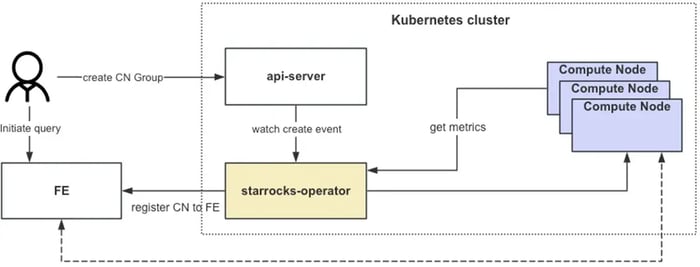
Tencent Games developed a stateless CN (compute node) and a Kubernetes operator. Being stateless, CNs can be dynamically scaled to accommodate the change in workload, which saves significant computing resources for Tencent Games’ dynamic workloads.
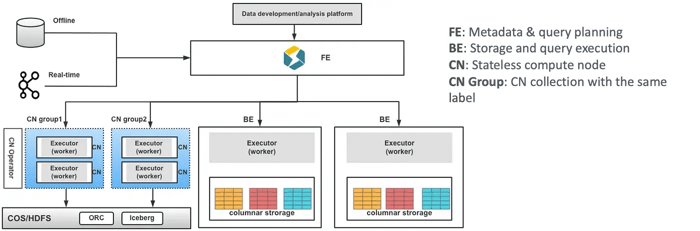
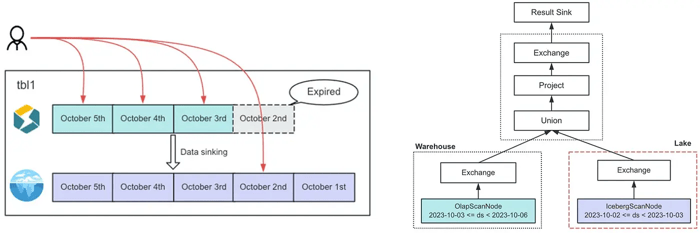
Second-level data freshness with mutable data on Apache Iceberg
All data is stored in Iceberg, and the CN is used to achieve elasticity and resource isolation. Hot data is temporarily stored in the StarRocks BE nodes and periodically sunk to Apache Iceberg for data persistence. Powered by StarRocks’ storage engine (BE nodes), Tencent Games can easily get second-level data freshness with mutable data. A single source of truth data is also preserved with all data persisted in Apache Iceberg.
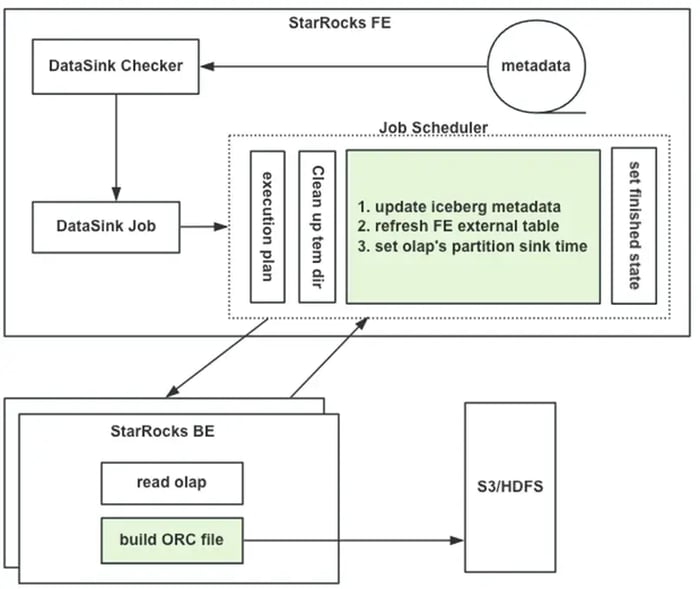
For querying, StarRocks tables are utilized as the single point of access for both data in StarRocks and Iceberg. User’s queries are automatically rewritten by an RBO to query data from both StarRocks and Apache Iceberg seamlessly.
Addressing Challenges
After running the aforementioned lakehouse architecture in production, Tencent Games encountered several challenges:
- Waste of resources: Large query requests during peak periods require significant computing resources, leading to waste during low periods.
- Poor resource isolation: SQL queries for large data in Iceberg consumed significant CPU and memory resources, causing other requests or data imports to fail or slow down.
- Slow execution plan generation: Continuous real-time ingestion generates millions of data files, making the query plan generation process slow. It took more than 65 seconds to generate a plan for a query that scans 2 months of data.
Functional Optimizations
To address these challenges, Tencent Games implemented the following optimizations:
Elastic Scaling
Tencent Games developed a Kubernetes operator for stateless compute nodes (CN). With compute nodes running as containers in Kubernetes, it enables easy deployment, maintenance, and dynamic scaling to reduce resource waste.
Physical Resource Isolation
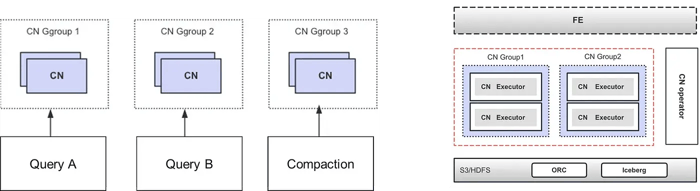
Using Kubernetes, Tencent Games can spawn groups of Compute Nodes (CNs) on demand with identical labels but different specifications — for example, group 1 with 4 cores and 8GB RAM, and group 2 with 24 cores and 64GB RAM. This setup allows for customization in the number of CNs per group and offers independent lifecycle management, where groups can be destroyed post-task. Importantly, this architecture enables physical resource isolation for Tencent Games’ heterogeneous workload.
Caching Immutable Meta Files
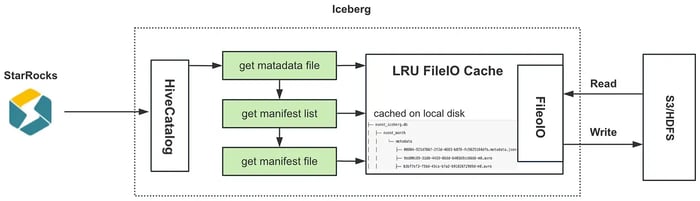
Tencent Games also added an LRU FileIO cache within a customized Hive Catalog to more efficiently access immutable metafiles including metadata files, manifest lists, and individual manifest files. This optimization significantly reduces I/O overhead, speeding up metadata access.
Optimizing Iceberg’s Execution Plan
When there are too many data files, reading column statistics for all of them is a very resource-intensive task, especially during query planning. Tencent Games pre-calculates and caches column statistics of data files in StarRocks tables, which can be read in parallel by CN and BE nodes to further accelerate the execution plan generation process.
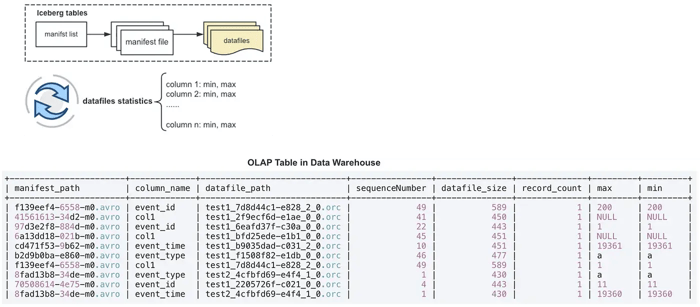
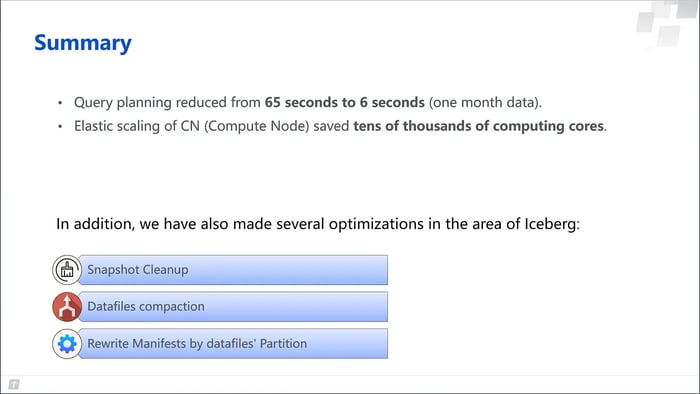
Results
These optimizations brought significant benefits — a query plan that used to take 65 seconds to generate now only takes 6; the stateless CNs also saved tens of thousands of computing cores. Additional Apache Iceberg optimizations such as snapshot cleanup and data file compaction further improved the performance and manageability of the lakehouse architecture.
Q&A

Q: What is the technology for sub-second response times for complex queries?
A: Hongli: Use StarRocks as a warehouse and as a cache for the lake caching hot data. For lake queries use elastic computing resources.
Q: What workloads are you putting onto StarRocks versus Spark versus Trino, and why? Any performance comparison to share between StarRocks, Spark, and Trino?
A: Hongli: Because a warehouse is needed for cache, there is no comparison with Spark. Comparing StarRocks and Trino on data lake in our scenario, there is a 10x improvement. That’s quite impressive. Adding the new flexible compute nodes (CN) makes StarRocks more flexible than Trino.
Q: Are you using Velox open source for C++ SIMD vectorized engine?
A: Hongli: We did it ourselves. (StarRocks SIMD vectorized engine is implemented from scratch)
Q: Are statistics per partition?
A: Hongli: Each data file.
Q: Pre-calculated cached data are put in your own set of metadata?
A: Hongli: We put the statistical information of data files into a table (StarRocks tables) in a warehouse.
Q: Did you have trouble keeping the column statistics materialization up to date for optimizing query planning?
A: Hongli: It went relatively smoothly. Real-time data still needs to be calculated.
Q: What is the maintenance cost comparing Trino and StarRocks?
A: Hongli: StarRocks has only two components. The elastic nodes are deployed on Kubernetes, and maintenance is also very easy.
Q: Are most of the features mentioned here available to open-source StarRocks or just internally available in Tencent?
A: Hongli: The functions we developed have also been contributed to the community, such as elastic node CN. The feature of data syncing into the (Iceberg) lake is still being contributed.
Join Us on Slack
If you’re interested in the StarRocks project, have questions, or simply seek to discover solutions or best practices, join our StarRocks community on Slack. It’s a great place to connect with project experts and peers from your industry. You can also visit the StarRocks forum for more information.
