Introduction
Trip.com is a leading global travel agency and online travel service provider. The company offers a wide range of travel products and services, including hotel reservations, airline tickets, car rentals, tours and activities, and visa services. Trip.com has over 300 million registered users and over 1.2 million hotels in more than 200 countries, with more than 5 billion USD in annual revenue.
Challenges
Artnova is a unified reporting platform within trip.com, which provides reporting across the entire company. Users use the system to monitor the pulse of the business and also create reports as needed to help with decision making. The raw data that feeds into Artnova is stored in Apache Hive.
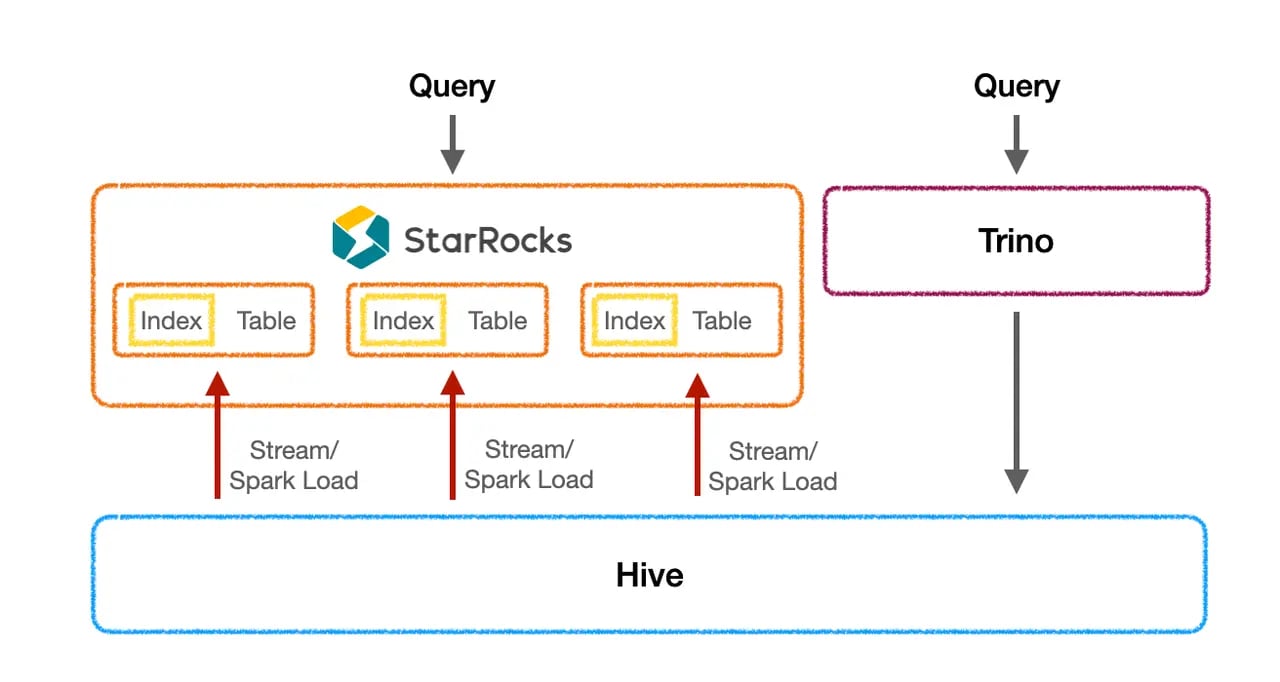 Trip.com's initial architecture
Trip.com's initial architecture
Trip.com faced several challenges with Apache Hive:
-
Slow query performance: Trip.com's growing data volume outpaced Hive's query performance, leading to delays in reporting and analysis. Users' complex SQL queries, often involving multi-table associations, subqueries, aggregations, and processing hundreds of rows, compounded the issue. Additionally, the base tables being queried were often massive, exceeding 100GB or even TB in size.
-
High concurrency with complex queries: Users are accustomed to hourly scheduled reports to run the business. For instance, 8:00 and 9:00 AM are peak periods for reporting. During these times, the system simultaneously handles over a thousand complex SQL queries, placing significant strain on the entire cluster. Furthermore, a single dashboard often comprises more than ten or even dozens of reports. When a user opens the dashboard, it triggers the execution of dozens of complex SQL queries simultaneously. Effectively reducing SQL latency and ensuring rapid response times to eliminate user wait periods remains a significant challenge.
-
Better support for a wider range of data types: Trip.com would like to store data in JSON and other data types.
StarRocks vs. Trino comparison testing
While numerous online reports lauded the excellent performance of StarRocks and Trino using TPC-DS and SSB standard datasets for benchmarking, Trip.com remained skeptical. To gain firsthand insights, they opted to directly test both projects against their own production data.
The goal of the testing was to see if StarRocks or Trino had the best performance for direct queries on the data lake.
Trip.com's data lake requirements:
Direct Apache Hive Querying:
-
Trip.com must have direct access to data within Apache Hive using an official, high-performance method.
-
No data ingestion or migration is necessary. The internal database query engine should be able to remotely connect to the data lake.
Open Table Format Support:
-
The database query engine must support Apache Hive and other open table formats, including Apache Iceberg, Apache Hudi, and Delta Lake on S3.
Cloud Infrastructure:
-
Both the database and the data lake should leverage common, readily available cloud infrastructure.
Trip.com's reporting platform data structure: datasets and reports
Trip.com's reporting platform utilizes a diverse data structure consisting of datasets and reports. Datasets exhibit a range of schemas, including single flat tables, snowflake schemas, and star schemas, along with a spectrum of SQL statements ranging from simple to complex. Reports, built upon these datasets, execute aggregated business-specific SQL queries. Multiple reports can be derived from a single dataset to address various business needs.
For this testing, a total of 4,000 reports were selected, encompassing 10 commonly used datasets and 15 business scenarios. These reports covered over 4,000 common queries, representing a diverse mix of single-table, multi-table joins, large-table, and small-table operations.
StarRocks vs. Trino Testing Results
In clusters with identical configurations, StarRocks delivered significantly faster query execution times compared to Trino. Without the DataCache enabled, StarRocks achieved a 2.2x performance improvement. Notably, enabling the DataCache further enhanced StarRocks' performance, achieving an impressive 7.4x improvement over Trino on average.
Specifically, implementing the StarRocks DataCache resulted in a dramatic reduction in average query time, from approximately 20 seconds to a mere 1.5 seconds, representing a remarkable 10-fold performance gain.
| Query | Trino418 | StarRocks 3.1 | |
| Data Cache Not Enabled | Data Cache Enabled | ||
| 1 | 29.28 | 11.35 | 3.84 |
| 2 | 6.20 | 0.85 | 0.01 |
| 3 | 10.93 | 6.23 | 0.77 |
| 4 | 25.45 | 8.27 | 4.48 |
| 5 | 9.33 | 22.65 | 1.17 |
| 6 | 7.59 | 11.90 | 2.08 |
| 7 | 14.98 | 11.97 | 2.01 |
| 8 | 0.20 | 0.18 | 0.14 |
| 9 | 56.41 | 7.99 | 6.75 |
| 10 | 6.83 | 2.40 | 1.84 |
| 11 | 8.11 | 0.84 | 0.00 |
| 12 | 29.55 | 10.50 | 2.38 |
| 13 | 2.47 | 2.75 | 2.17 |
| 14 | 12.73 | 0.59 | 0.01 |
| 15 | 16.14 | 6.91 | 4.15 |
| Sum | 236.21 | 105.37 | 31.79 |
| Ratio (Trino/StarRocks) |
2.24 | 7.43 | |
Table 1: StarRocks vs. Trino benchmarks
Why was StarRocks faster for data lake queries?
While StarRocks' inherent advantages, such as its vectorization engine, pipeline execution engine, query cost based optimizer, Global Runtime Filter, and others, equip it for handling complex query scenarios, querying a data lake presents unique challenges compared to querying internal tables. Firstly, data storage is remote, necessitating separate nodes for calculation and storage, incurring network overhead. Secondly, StarRocks does not directly manage metadata, making it difficult to fully control statistical information like internal tables have. This, in turn, can hinder the optimization of query planning and scheduling. Fortunately, StarRocks offers specific functionalities designed for data lake queries, primarily categorized into two major areas:
Query acceleration and IO optimization
One of the major areas of improvement working with a data lake was optimizing and reducing the amount of I/O to remote storage. They can be grouped into the following categories:
-
IO merging: adaptive IO merging according to the query situation, thereby reducing the number of I/Os;
-
Delayed materialization: First, filter the columns with predicate filtering, locate the target row, and then read other columns that need to be accessed to reduce the total amount of I/O;
-
Optimization of readers for various file types
-
Optimizing Apache Hive Metadata
-
Apache Hive Metadata caching
-
Developing an update mechanism of Apache Hive metadata and statistical information.
-
Data Cache
When StarRocks queries Hive tables, it pulls the remote data to the BE nodes for computation. This stage incurs network overhead and places a certain amount of pressure on HDFS. Furthermore, HDFS jitter can negatively impact final response times. To address this, StarRocks' Data Cache can asynchronously cache the original data to the BE nodes.
Subsequent queries can read that cached data instead of reading directly from the BE nodes, eliminating the need to fetch data from HDFS again. Additionally, the community is developing optimizations for asynchronous cache filling, cache expiration, and cache warming to ensure the process itself is speedy and fresh while not impacting query performance.
Additional StarRocks performance testing
The use of Materialized Views was not done as part of the evaluation. As an "art of the possible", materialized views were set up to see what additional query performance gains were possible.
Materialized Views
While the performance of direct queries on StarRocks outperforms Trino significantly, certain challenging datasets persist. These datasets often exhibit large data volumes, complex queries, and low latency requirements for business-critical queries. In such scenarios, pre-processing the data and importing the processed results into StarRocks for further acceleration proves to be the optimal solution. This approach, however, necessitates the maintenance of additional data processing and import logic, and requires users to modify their query SQL to target the StarRocks internal table.
Materialized Views have the following characteristics:
-
Partition-level refreshes: Materialized Views have the ability to manage their own refresh logic. Notably, partitioned Materialized Views can automatically perform incremental refreshes whenever partitions change, significantly increasing data freshness while reducing CPU load and long data refresh windows. For example, a table that originally took one hour to load in Spark can be loaded in just five minutes using Materialized Views.
-
Transparent query acceleration: Materialized views support transparent query rewriting, enabling users to leverage them for query acceleration without modifying their SQL statements. This transparency makes the process seamless and user-friendly.
To address a low-latency scenario with a large data volume, we conducted an additional test case in our comparison testing. This scenario required aggregation calculations on a massive dataset of 1.6 billion rows. Importing such a large amount of data directly into an internal table was impractical. Furthermore, the cold query performance using the Apache Hive catalog feature directly was 1-2 minutes, which did not meet the business requirements.
Consequently, we created a Materialized View based on the query. This Materialized View reduced the data size to approximately 10GB, enabling a complete refresh within 15 minutes. Queries against the Materialized View saw a dramatic performance increase, with query times dropping to below 2.5 seconds, representing an improvement of 3-40 times.
Solution
With the comparison testing completed, StarRocks was put into production with the following architecture.
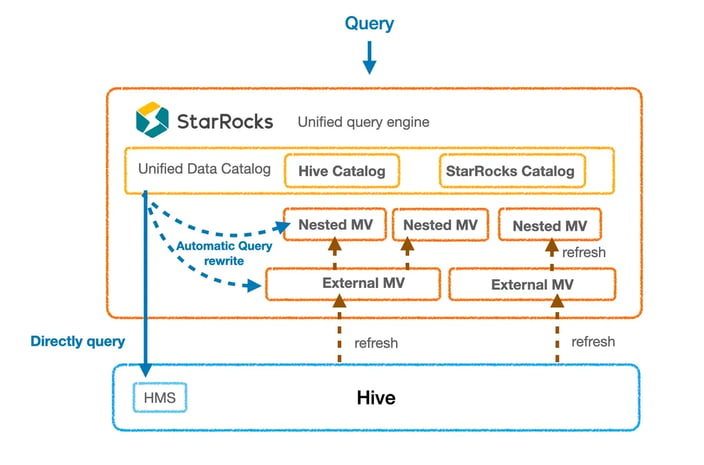
Trip.com's upgraded StarRocks-based architecture
The comprehensive solution employing StarRocks using the Apache Hive Catalog feature, Data Cache and Materialized Views has yielded significant performance improvements. Reports migrated to use StarRocks with Apache Hive have experienced an average speed-up of 10 times, which is equivalent to the performance boost achieved with native StarRocks internal tables. Currently, over 50,000 queries have been transitioned from Trino to the StarRocks and Apache Hive solution, leading to a marked improvement in user experience.
Results
Trip.com has seen significant benefits since deploying StarRocks:
-
Faster query performance: StarRocks has been able to reduce query times by up to 10x. This has improved reporting and analysis productivity.
-
Wider data type support: StarRocks is able to store and query all of Trip.com's data, including JSON and Parquet. This has simplified data management and analysis.
-
Improved scalability: StarRocks has been able to scale to meet Trip.com's growing data volume and query workload. This has eliminated performance bottlenecks and outages.
