StarRocks 3.3 has been released, and users will quickly discover that it has undergone comprehensive optimizations and innovations in stability, performance, cache design, materialized views, storage optimization, and lakehouse ecosystem integration. This article will introduce these new features and improvements to StarRocks 3.3.
Maturity and Stability
StarRocks 3.3 will serve as the next long-term support version, meaning it will be maintained and supported over an extended period. From StarRocks 3.3 onwards, features will be categorized into different maturity levels:
-
Experimental: Experimental features may have potential user interface changes and could be discontinued. Features that have not yet reached full coverage standards are also included here. These features need to be manually activated by users and do not impact other functionalities.
-
Preview: The user interface is generally stable, but some configurations might need to be fine-tuned. Suitable for use in non-core scenarios.
-
GA (General Availability): The user interface and functionality are clearly defined. Although some features may be added, existing functionalities are unlikely to change, ensuring they are production-ready.
Furthermore, we've added more comprehensive definitions for product capabilities in 3.3 documentation for key features like data lake analytics, shared data architecture, and materialized views.
Data Cache Improvements
A well-designed caching framework is crucial when querying data stored in remote storage, such as cloud object storage. Whether it's external tables like Hive, Iceberg, Hudi, or StarRocks' managed shared data internal tables, the cache hit rate directly affects performance. The challenge lies in maintaining a high cache hit rate consistently. To achieve this, StarRocks 3.3.x added the following features and improvements to its data cache.
-
Cache Warmup: The cache warmup command allows selected data to be pre-loaded into the cache, reducing latency for future initial queries.
-
Cache priority: This feature, to be introduced in version 3.3.1, allows users to set different cache priorities for different data, ensuring that the most critical data is prioritized for caching.
-
Memory optimization and observability: Cache memory optimization and observability improvements make cache management and monitoring more efficient and transparent.
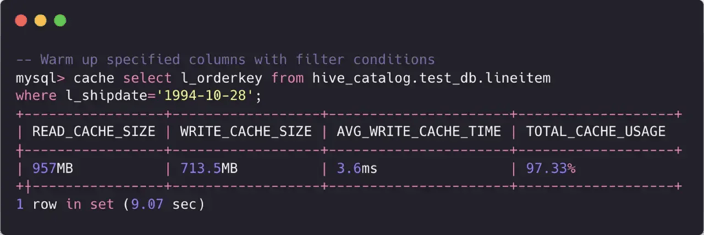
StarRocks' Cache Warmup
For shared data clusters, StarRocks 3.3 added support to use AWS Express One Zone as storage, significantly enhancing read and write performance, and paving the way for future global caching possibilities.
Cold queries
Additionally, performance for cold queries has also seen significant enhancements. This is primarily achieved through the optimized parallel scanning of tablets and automatic merging of small I/Os, ensuring that query performance remains strong even without cache support.
Data Lake Ecosystem
-
Hive External Catalog: In version 3.3, StarRocks supports write capabilities for ORC and Text files. In testing, a single sink operator's writing with StarRocks performed twice that of Trino.
-
-
Restructured the Iceberg metadata query module, enhancing distributed metadata reading to boost performance in parsing Avro format files and avoiding bottlenecks inherent in the native SDK.
-
Manifest caching now reduces repetitive I/O for small metadata, significantly enhancing Iceberg metadata access performance.
-
Added support for V2 table equality deletes.
-
Added support for Iceberg View.
-
-
Paimon External Catalog: StarRocks 3.3 now fully supports the Paimon ecosystem, including support for the latest delete vectors, integration of Paimon system tables, and the optimization of scan range scheduling.
-
[Experimental] ClickHouse and Kudu External Catalog: The community has contributed dedicated migration tools to facilitate user migration from ClickHouse to StarRocks, making the data migration process smoother and more efficient. Furthermore, StarRocks also supports Catalog functionality for ClickHouse and Kudu, allowing users to more conveniently manage and query data between these databases and StarRocks.
Performance Improvements
-
Improved data scanning performance by taking full advantage of Page Index for parquet files, minimizing page reads, thus reducing the data scanned volume.
Materialized Views
The traditional ETL process is complicated. Not only do you need to set up the transformation pipelines, but you also have to rewrite the SQL to point to the pre-computed table to benefit from it.
StarRocks materialized view's query rewrite capabilities eliminate the need for users to modify their SQL queries to gain performance benefits, enabling data transformations to be added on demand.
In version 3.3, further important optimizations have been made:
-
Enhanced capabilities for external table materialized views: Iceberg external table materialized views support partition-level incremental refreshes and can be created on tables with Hidden Partition partitioning. Paimon external table materialized views have completed rewrite capabilities and support partition-level incremental refresh.
-
More comprehensive transparent rewrite capabilities: StarRocks 3.3 supports materialized view rewrites based on text and views. Besides the standard SJPG rewrite capabilities, view-based MV rewriting can redirect queries targeting views to equivalent materialized views. Text-based rewriting capabilities allow the text matching of some non-standard SQL segments, addressing the difficulty of transparently rewriting complex queries. If used correctly, both of them are ways to bypass the SJPG query rewrite constraint.
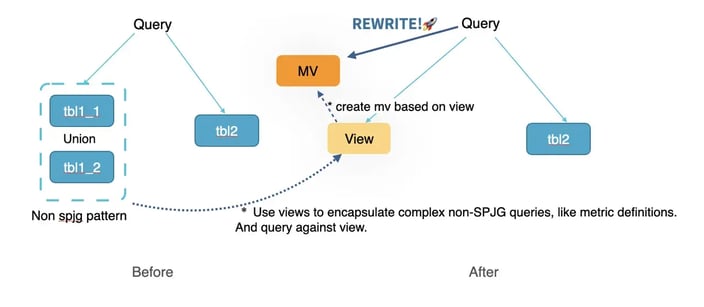
StarRocks rewrite improvements in 3.3
-
Multi-table partition refresh: Previously, StarRocks materialized view only supported single table incremental refresh. Version 3.3 introduces a multi-fact table alignment strategy, reducing the overhead of materialized view refreshes in multi-fact table association scenarios.
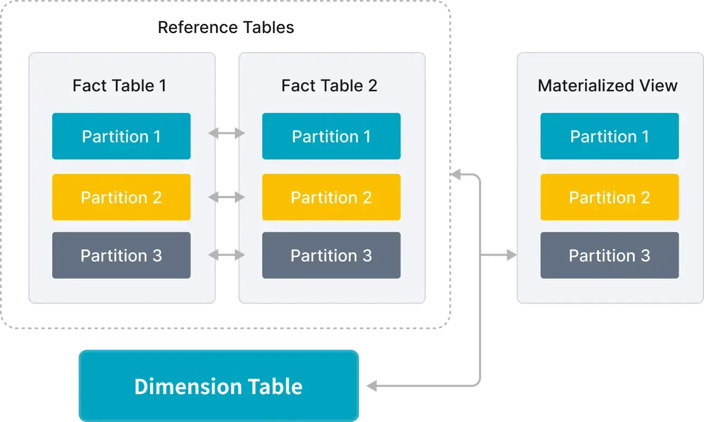
Multi-table partitioning updates
- Control consistency when querying MV: Previously, materialized view rewrites mainly redirected queries targeting base tables to materialized views. By enabling the transparent_mv_rewrite_mode, users can choose to redirect queries targeting MVs to base tables. This mode allows for configuring behavior when MV and base table data are inconsistent, balancing data timeliness and query performance, suitable for layered modeling scenarios.
- Enhanced materialized view scheduling capabilities: The addition of the enable_query_rewrite attribute allows for disabling query rewrites, reducing planning overhead. By controlling the number of candidate materialized views and introducing more efficient filtering algorithms, a materialized view plan cache (MV plan cache) is made possible. Global FIFO scheduling optimizes the cascading refresh strategy for nested materialized views.
Query and Storage
StarRocks 3.3 has also made optimizations for large queries, data compression, and memory usage in data lake scenarios.
Large Queries
-
Operator spill-to-disk GA: effectively optimizes the memory usage by spilling intermediate results to disk
-
Support for Colocate Group Execution significantly reduces memory usage for join and aggregation operators by executing queries on colocated tables in stages, thus significantly enhancing the stability of large queries.
Scenario specific enhancements
Specific scenario performance enhancements in StarRocks 3.3 include:
-
Inverted index and Ngram index significantly improve the efficiency of full-text search;
-
FlatJson has seen performance improvements by several orders of magnitude, automatically accelerating JSON queries to bring their performance close to that of structured data while maintaining flexibility.
-
Bitmap optimizations
-
Enhanced the performance and memory usage of Bitmap series functions
-
Added the ability to export Bitmap to Hive, along with the corresponding Hive Bitmap UDF.
-
-
StarRocks 3.3 added histogram statistics in external table statistics to address data skew issues, generating more accurate execution plans while optimizing Shuffle Join operations during data skew.
ARM first-class support
StarRocks has significantly optimized ARM architecture, making it a first-class citizen alongside x86 architecture. In tests on AWS Graviton instances, StarRocks on ARM performance showed remarkable improvements:
| Data Set | X86(s) / ARM-OPT(s) |
| SSB100GB | 1.11 |
| SSB FLAT 100GB | 1.14 |
| TPCH 100GB | 1.13 |
| TPCDS 100GB | 1.35 |
-
11% faster than x86 in the SSB 100G test
-
39% faster in the ClickBench test
-
13% faster in the TPC-H 100G test
-
35% faster in the TPC-DS 100G test.
Primary Key Table
For primary key tables, StarRocks 3.3 has implemented several optimizations:
-
Primary Index Compute-Storage Separation Support for Remote Storage: Primary key index disk drops support dropping to remote storage, enhancing data flexibility and scalability.
-
Support for Size-Tiered Compaction Strategy for Primary Key Tables: This strategy reduces the write I/O and memory overhead during compaction and is suitable for shared data and shared-nothing clusters.
-
Optimized primary key table persistent index read I/O: Supports reading persistent indexes in smaller granularity pages and improves the persistent index Bloom Filter. This optimization is also applicable in both compute-storage integrated and separated clusters.
Try StarRocks 3.3 Today
The StarRocks 3.3 release marks significant improvements in performance, flexibility, and ease of use. Download it now and start experiencing all of these enhancements for yourself. For more detailed information, visit the official release notes: StarRocks 3.3 Release Notes.
Be sure to join us on StarRocks' Slack if you have questions about 3.3 or want to learn more about what's next for StarRocks.
