Traditional databases are designed to have computing workloads run on local nodes to minimize data movement and reduce query latency. As data volumes and demands for real-time analysis grow, this storage-compute coupled architecture becomes unsatisfactory. Issues like wasteful compute resources in traffic valleys, complex data distribution and deployment, and costly maintenance are eating up profits, which is unbearable in a business world where "cost" and "efficiency" are everything. A storage and compute decoupled architecture that is able to scale compute independently is very much needed.
This article starts with two common business scenarios and explains how StarRocks's storage-compute separation architecture helps cut costs and enhance efficiency. It then goes deep into how this architecture fulfills this goal and presents benchmark comparisons.
Cost Reduction With Hot-Warm Data
Separation of storage and compute can reduce storage expenses when customers have both hot and cold data to query and store.
Scenario: Log analytics
|
Scenario description
|
Requirements
|
|
Substantial amounts of tracing data and application logs are generated every day.
Need to analyze both real-time log data (such as live traffic and user behavior) and offline logs, such as historical data, to generate valuable business insights.
|
|
Cost reduction in a real-world use case
Customer A has a website generating 1 TB of incremental log data every day and the log data is retained for 2 years. However, only log data generated within the most recent 7 days are queried for most of the time.
In storage-compute coupled architecture, if each server has 20-TB storage capacity, 16 vCores, 64 GB memory, three data replicas, and a 50% compression ratio, a total of (700 TB * 3 * 0.5)/20 TB ≈ 52 servers will be needed to store 700 TB data. However, 80% of the analytics workloads are used to analyze only log data generated within the most recent 7 days, which means (7 TB * 3 * 0.5)/20 TB ≈ 0.52 servers will be enough to handle most data queries. Over 95% of the server costs are wasted on storing cold data which is rarely queried.
After storage-compute separation is adopted, the hardware cost can be cut by 78%.
Efficiency Improvement
StarRocks's storage-compute separation architecture is designed to scale in response to varying levels of traffic. This scalability enhances computational efficiency, resulting in improved query performance.
Scenario: SaaS e-commerce platform that generates reports
|
Scenario description
|
Painpoint
|
Data query characteristics
|
|
Enterprises use order data to generate real-time, daily, monthly, and annual reports, to gain insights into sales trends and seasonal changes. This helps optimize inventory and sales strategies.
QPS peaks when users frequently query data to generate reports.
|
Coupled storage and compute architecture is sized based on the highest expected load to ensure a satisfactory user experience during peak hours, while wasting resources during off-peak hours.
|
|
Efficiency improvement in a real-world use case
A SaaS e-commerce platform generates sales reports from different time dimensions for various users, with the daily QPS against sales reports peaking at around 100. The platform provider deploys a cluster of 3 servers, each provisioning 32 vCores and 128 GB memory for each user. As such, P99 latency remains below 3 seconds for queries against daily and weekly sales reports, while cluster utilization stays at around 30%.
However, at the end of each month, users need to analyze their sales data for the entire month, and the QPS peaks at a higher value. As a result, cluster utilization surges to 100%, and P99 latency exceeds 10 seconds or even longer.
To ensure equivalent query performance at the end of each month, the platform provider needs to scale the cluster to approximately (30/7) * (10/3) * (1/3) ≈ 4.76 times its original size. That means a total of 3 * 4.76 ≈ 14 nodes.
Because the QPS peaks during the end of month reporting, with separate storage and compute the number of nodes deployed varies based on computing requirements, and is only high during the last week of the month. They only need to deploy 14 nodes during the last week of the month, and 3 nodes during other weeks. This reduces overall nodes to (3/4 * 3) + (1/4 * 14) = 5.75 nodes, but at the same time increases the overall computational efficiency by 14/5.75 ≈ 2.43 times.
Deep Dive
As a massively parallel processing (MPP) database, StarRocks has long used the storage-compute coupled architecture, where backends (BEs) are responsible for both storage and computing. This architecture can achieve blazing-fast analytics because all data is stored in local nodes, without network transmission overhead.
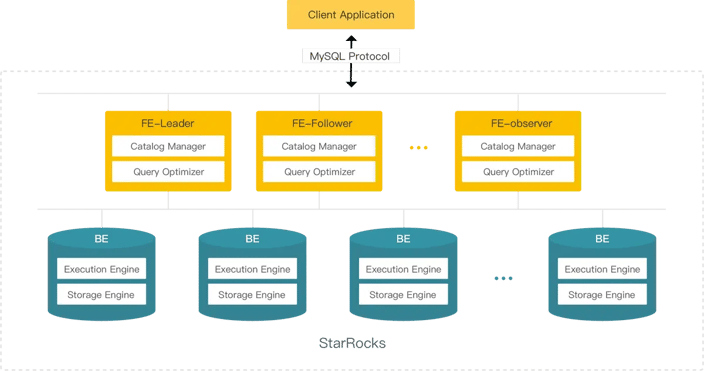
However, this architecture comes with its own limitations:
-
Growing cost: As data volume grows, the demand for storage and compute resources is increasing disproportionately fast, leading to low resource efficiency.
-
Complex architecture: Maintaining data consistency across multiple replicas adds complexity to the system, increasing its risk of failure.
-
Limited elasticity: Scaling operations will cause data rebalancing, resulting in an unsatisfactory user experience.
To solve these issues, StarRocks v3.0 announces the shared-data cluster, which features a storage-compute separation architecture. In the following sections, we will delve into the technical aspects of how StarRocks achieves uncompromised performance while enhancing cost-efficiency and effectiveness on its new storage-compute separation architecture.
In the new architecture, data storage functions are decoupled from BEs. BEs, now called "compute nodes (CNs)", are responsible only for data computing (with some hot data cached locally). Data is stored in low-cost, reliable remote storage systems such as HDFS and Amazon S3. This reduces storage cost, ensures better resource isolation, and high elasticity and scalability.
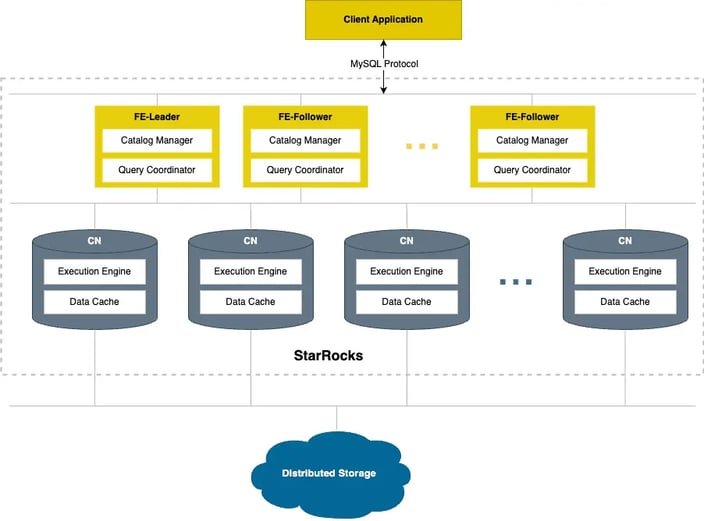
Storage
StarRocks' storage-compute separation architecture is designed to decouple storage from computation, rendering compute nodes stateless for rapid scaling. Additionally, object storage typically offers superior data reliability at lower costs.
Currently, the StarRocks shared-data cluster supports two storage solutions: object storage (for example, AWS S3, Google GCS, Azure Blob Storage, and MinIO) and HDFS deployed in traditional data centers. This technology unifies the storage of data in a specified bucket or HDFS directory.
In a shared-data cluster, the data file format remains consistent with that of a shared-nothing cluster (featuring coupled storage and compute). Data is organized into segment files, and various indexing technologies are reused in cloud-native tables, which are tables used specifically in shared-data clusters.
Caching
StarRocks shared-data clusters decouple data storage and computation, allowing each to scale independently, thereby reducing costs and enhancing elasticity. However, this architecture can affect system performance.
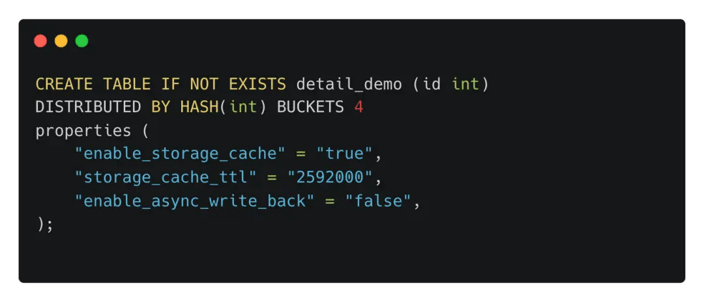
To mitigate the impact, we implement local disk caching for frequently accessed data (hot data). Users can choose to enable hot data caching and specify the cache time-to-live (TTL) when creating cloud-native tables. This ensures that hot data remains cached on the local disk for the specified TTL, accelerating queries.
Users can control data caching when creating cloud-native tables with parameters including:
-
enable_storage_cache: Whether to enable local disk cache. -
storage_cache_ttl: The cache's lifetime, after which the data is automatically expired and evicted from the cache. -
enable_async_write_back: Whether to enable asynchronous write-back.
-
When local disk cache is enabled, data is written simultaneously to the local disks of compute nodes and the storage system. It only returns success when both write operations are successful. Additionally, the
storage_cache_ttlparameter controls the lifespan of data cached on disk. -
When asynchronous write-back is enabled, success is returned immediately after the data is written to the local disk, leaving background tasks to write data to the object storage. This mode is suitable for business scenarios that prioritize high throughput and low latency but may come with a certain level of data reliability risk.
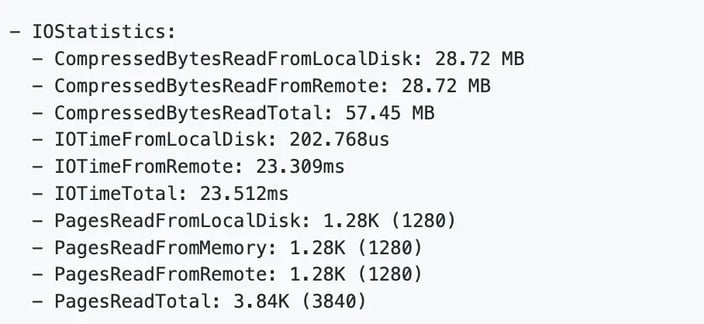
The above indicates that the query analyzed required data from object storage (PagesReadFromRemote), local disk cache (PagesReadFromLocalDisk), and the memory of the compute node (PagesReadFromMemory).
In real-world scenarios, some queries involve a substantial amount of historical data with very low access frequency. Caching such cold data could potentially push out hot data, causing performance fluctuations. To address this issue, in upcoming releases we will allow users to specify strategies when creating tables to avoid caching cold data and prevent the eviction of hot data during access to cold data.
For cold data from the object storage, StarRocks has been optimized to prefetch data from the object storage based on the application's access patterns. This effectively reduces the frequency of object storage access, enhancing query performance. We have verified the effectiveness of this optimization in practical performance tests, with details available in the "Performance Assessment" chapter.
StarRocks' storage-compute separation architecture establishes a multi-tiered data access system encompassing memory, local disk, and remote storage to better meet various business needs. By keeping hot data close to compute units, StarRocks achieves truly high-performance computation and cost-effective storage. Moreover, access to cold data has been optimized with specific strategies, effectively eliminating performance limits for queries.
Multi-versioned data
StarRocks' storage-compute separation architecture adopts the data multi-versioning technology. Each loading task generates a unique data version in StarRocks, and once created, these versions remain unaltered. Data version compaction only produces new data versions.
In a shared-data cluster, each data version contains tablet meta files and tablet data files, which are both written to object storage. Tablet meta files record all data file indexes for that data version. Tablet data files are organized according to the segment file format. When a compute unit needs to access a tablet, it first loads the corresponding tablet meta files from the storage based on the version information and subsequently accesses the corresponding data files based on the index.
Multi-versioned data lays the foundation for advanced features like Time Travel in the future.
Compaction
Compaction is the most important background task running in StarRocks, responsible for merging multiple historical data versions into a larger version to improve query performance. In a shared-nothing cluster (storage-compute coupled), BE nodes schedule compaction tasks based on their own loads.
While in a shared-data cluster, FE nodes take over the scheduling of compaction tasks. Thanks to its data-sharing capabilities, FE nodes can dispatch compaction tasks to any compute units, and in the future, they may even schedule compaction tasks to dedicated clusters, ensuring zero impact of compaction tasks on business. Additionally, the resource pool for running compaction tasks can be dynamically scaled. This means compaction is no longer a troublesome issue for users, and a balance between performance and cost can be achieved.
Performance Assessment
Storage-compute separation significantly reduces costs while delivering exceptional elasticity. However, users still have performance concerns due to the query latency from object storage. To respond to this concern, we introduced several performance optimization techniques to handle various scenarios. The following test results demonstrate that the performance of storage-compute separation is comparable to coupled storage and compute. The test mainly covers data loading and hot/cold data querying.
Data loading
We use Clickbench to evaluate the performance of the stream loading of the storage-compute separation architecture. The test uses a hardware configuration of one FE and three BEs/CNs. The test data is in CSV format, with a total size of 160 GB and individual file size of 1 GB.
The test focused on measuring the execution time and throughput of data loading when different numbers of clients are used for concurrent queries.
| Concurrency | Execution time (s) | Throughput (MB/s) | ||
| Shared-nothing | Shared-data | Shared-nothing | Shared-data | |
| 1 | 1007 | 1024 | 162 | 160 |
| 4 | 377 | 379 | 434 | 432 |
| 16 | 363 | 183 | 451 | 895 |
The results show that the shared-data cluster has the same loading execution time and throughput as shared-nothing. As query concurrency increases, the execution time and write throughput of shared-data continues to improve until it reaches the network bandwidth limit.
Data query
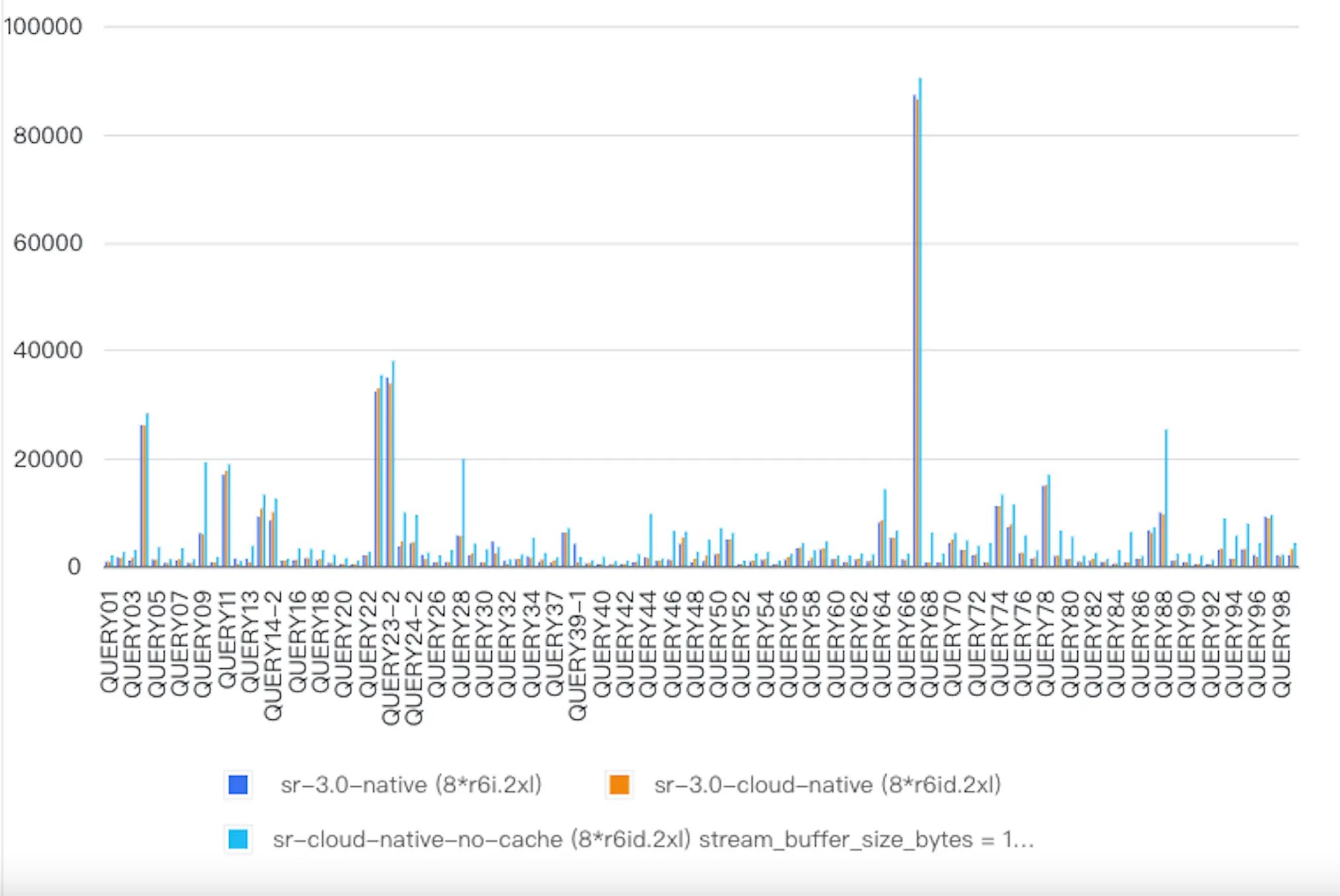
We built two clusters (shared-data and shared-nothing) of the same configurations. We evaluated the performance of the two clusters against the TPC-DS 1TB dataset. The following table and diagram show the performance comparison result.
"StarRocks native" represents shared-nothing clusters."StarRocks cloud-native" represents the shared-data clusters where all queries hit the cache."StarRocks cloud-native-no-cache" represents share-data clusters with no cache enabled.
When all the cache is hit, "StarRocks cloud-native" has an overall performance parallel to "StarRocks native" (428s VS 423s). Even in extreme cases where all the queries are run to query cold data, the query performance degradation is within a reasonable range (668s VS 428s) after optimization measures such as prefetch are used.
| Architecture | Query latency (s) |
| StarRocks native | 423.618 |
| StarRocks cloud-native | 428.167 |
| StarRocks cloud-native-no-cache | 667.887 |
Summary and Outlook
Starting from v3.0, StarRocks has been upgraded to a brand-new storage-compute separation architecture. With this new architecture, users can continue to enjoy the powerful analytical capabilities of StarRocks, and the low cost and extreme elasticity brought by storage-compute separation. What's even more important is that these capabilities are open and shared, allowing every StarRocks user to benefit from the outstanding performance of StarRocks.
We will continue to fully utilize the data sharing capabilities of storage-compute separation to achieve more flexible data sharing, elastic resource scaling, and resource isolation. We plan to construct multiple compute clusters to isolate workloads. Additionally, we will further enhance the real-time analytics and processing capabilities of StarRocks.
