Analytics has been the center of attention when it comes to data platforms in nearly every industry. With technology in the data infrastructure space having grown tremendously in recent years, alongside an increase in real-time analytics use cases, users have started looking for OLAP database solutions able to refresh their dashboards, monitoring systems, and more in real time.
One of the more popular use cases is the real-time analysis of data generated by applications, such as web page access events and online transactions. These events need to be streamed into a database for analysts and stakeholders to better understand user behavior, identify security risks, and more.
To efficiently handle these events, message queue systems like AWS SQS, Apache Kafka, and RabbitMQ were created to serve as pipelines that link applications to databases. For processing data from these message queue systems, a real-time database that can support high concurrent stream or mini-batch data ingestion is essential. For most use cases, StarRocks serves as an ideal solution.
Tutorial Overview
In this tutorial, we will look at a simple web page access use case to showcase how StarRocks can be used to consume real-time stream data in the Kafka message queue system. By the end of this walkthrough, you'll be able to:
-
Deploy StarRocks and Kafka with a docker-compose YAML template in a single instance.
-
Generate synthetic data with a Python script.
-
Set up a routine load job that loads data into StarRocks in real time.
Architecture Framework
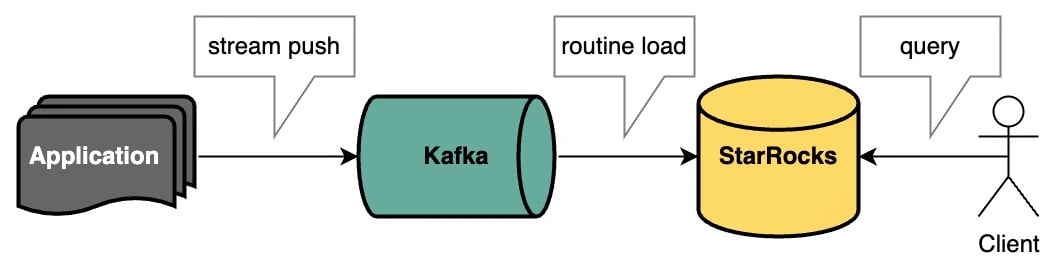
The following is the architectural framework for this use case. The Application will function as a web server that frequently generates web page access logs and pushes them to the Kafka stream. Subsequently, StarRocks will employ the routine load method to extract data from Kafka and prepare it for the final client SQL query.
Preparing Environments
Deploy
In this tutorial, we will use a docker-compose YAML template to deploy everything we need in a single instance.
Download the YAML file
wget https://raw.githubusercontent.com/starrocks/demo/master/loadJsonFromKafka/stack-docker-compose.yml
Start the deployment
docker compose -f stack-docker-compose.yml up -d
docker compose up -d <service-name>. For example:# StarRocks only
docker compose -f stack-docker-compose.yml up starrocks-fe starrocks-be -d
# Kafka only
docker compose -f stack-docker-compose.yml up zookeeper kafka -d
Create a topic in Kafka
Create a topic quickstart in Kafka.
docker exec broker kafka-topics --bootstrap-server 127.0.0.1:9092 --create --topic quickstart
Create a table in StarRocks
Connect to StarRocks
mysql -uroot -h 127.0.0.1 -P 9030
Create database and tables.
Here we use aggregated table and bitmap data types to accelerate COUNT DISTINCT calculations
CREATE DATABASE DEMO;
USE DEMO;
CREATE TABLE `visits` (
`uid` int NULL COMMENT "",
`site` varchar(50) NULL COMMENT "",
`vdate` DATE NULL COMMENT "",
`vhour` smallint NULL COMMENT "",
`vminute` smallint NULL COMMENT "",
`vtime` bigint(20) NULL COMMENT "",
`uv` BITMAP BITMAP_UNION
) ENGINE=OLAP
AGGREGATE KEY(`uid`, `site`, `vdate`, `vhour`, `vminute`, `vtime` )
DISTRIBUTED BY HASH(`site`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
Data Ingestion
Data generation and ingest into Kafka
For demonstration purposes, we will use synthetic data. You can get the data generation python2 script from https://github.com/starrocks/demo/blob/master/loadJsonFromKafka/gen.py.
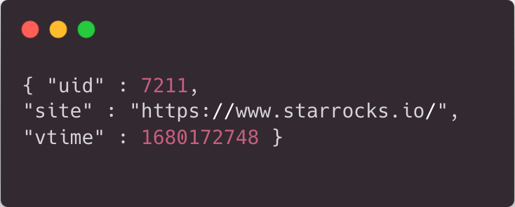
With this dataset, we will simulate a user behavior analysis scenario for a webpage access use case. A snippet of the generated dataset is shown below.
Install the necessary dependencies before running the scripts
wget https://raw.githubusercontent.com/starrocks/demo/master/loadJsonFromKafka/requirements.txt
# Install this to your python2 env
pip install -r requirements.txt
Run python script to generate data and push it into Kafka topic quickstart
wget https://raw.githubusercontent.com/starrocks/demo/master/loadJsonFromKafka/gen.py
# This script is written in python2
# The parameter here controls the number of rows of data generated
python gen.py 9999
StarRocks Routine Load
Here we use routine load to pull data from Kafka into StarRocks.
Remember to modify <host-ip> to the IP address of the host machine.
USE DEMO;
CREATE ROUTINE LOAD DEMO.quickstart ON visits
COLUMNS(uid, site, vtime, vdate=from_unixtime(vtime, '%Y%m%d'), vhour=from_unixtime(vtime, '%H'), vminute=from_unixtime(vtime, '%i'), uv=to_bitmap(uid))
PROPERTIES
(
"desired_concurrent_number"="1",
"format" ="json",
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
)
FROM KAFKA
(
"kafka_broker_list" ="10.5.0.5:9094",
"kafka_topic" = "quickstart",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
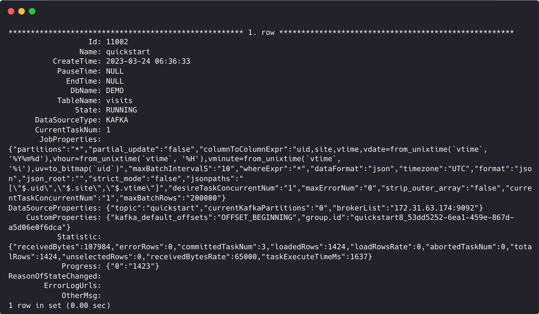
Then you can use show routine load to see the load job.
Query Your Data From StarRocks
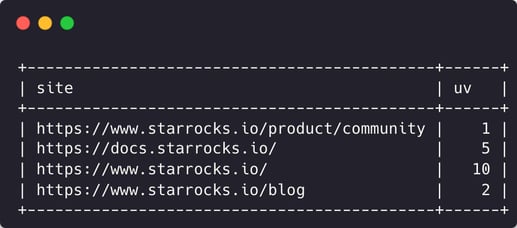
Now you can determine which web page is accessed more frequently:
USE DEMO;
select site, count(distinct uv) uv from visits group by site;
Get Started with StarRocks Now
In this tutorial, we used StarRocks' routine load to periodically pull data from a Kafka topic in real time for downstream analysis. Now you're ready to try it for yourself.
Download StarRocks for free here and be sure to join our Slack community.
If you want to learn more about StarRocks' Routine Load's best practices, please visit the official documentation site here.
