In recent years, as the concept of data-driven decision-making continues to gain popularity, companies are demanding an advanced data analytics architecture capable of handling various new data analytics scenarios. The data architecture should exhibit the characteristics of high speed, high concurrency, real-time, and flexibility.
Among these, accelerating query speed becomes companies’ most fundamental concern. Current data analytics products could only provide unsatisfying performance, especially in scenarios of multi-table join queries, real-time data ingestion, high-concurrent analytical queries.
Because of this, companies have to rely on data preprocessing techniques, such as precomputation and flat tables, to accelerate their data analytics speed. But this solution has some disadvantages. For example, it could not provide flexible and real-time data analytics. Also, it is more time-consuming and costly to construct, develop and maintain this complex data analytics architecture. For example, data engineers have to spend more time prebuilding and maintaining cubes and flat tables.
StarRocks
StarRocks is a new-generation and high-speed MPP database for nearly all data analytics scenarios. We wish to provide easy and rapid data analytics. Users can directly conduct high-speed data analytics in various scenarios without complicated data preprocessing. Query speed (especially multi-tables JOIN queries) far exceeds similar products because of our streamlined architecture, full vectorized engine, newly-designed Cost-Based Optimizer (CBO) and modern materialized views. We also support efficient real-time data analytics. Moreover, StarRocks provides flexible and diverse data modeling, such as flat-tables, star schema, and snowflake schema. Compatible with MySQL protocols and standard SQL syntax, StarRocks can communicate smoothly across the MySQL ecosystem, for example, MySQL clients and common BI tools. It is an integrated data analytics platform that allows for high availability and simple maintenance and doesn’t rely on any other external components.
Streamlined Architecture
StarRocks’s streamlined architecture is mainly composed of two modules, Frontend (FE for short) and Backend (BE for short), and doesn’t depend on any external components, which makes it easy to deploy and maintain. Meanwhile, the entire system eliminates single points of failure through seamless and horizontal scaling of FE and BE, as well as replication of meta-data and data.
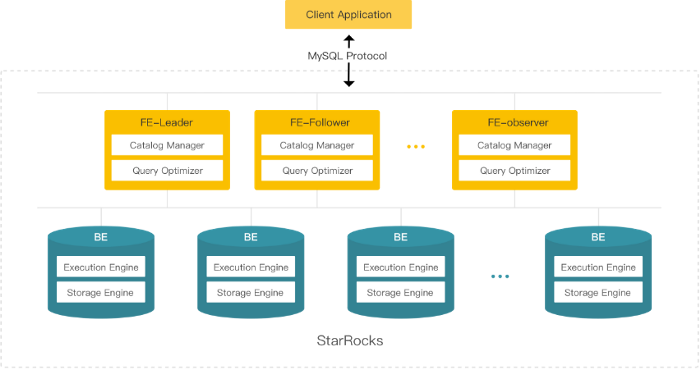
The StarRocks Frontend node is responsible for metadata management, client connections, query planning, query scheduling, and so on. There are two different node roles in FE, Follower and Observer. Followers consist of an elected leader and other followers. Leader election is based on BDBJE(BerkeleyDB Java Edition)which is similar to the Paxos algorithm, so long as more than half of followers have survived in the cluster. Only the leader can write metadata while other followers can only forward write requests to the leader. StarRocks only considers metadata to be successfully written into FE when the majority of followers have successfully fetched and acknowledged each message sent to the leader. Observers don’t participate in the election and are mainly responsible for concurrent query performance of the cluster by replaying the trans-log asynchronously. Each Frontend stores one complete set of metadata in its memory so as to guarantee the consistency of service.
The Backend node supports data storage and SQL execution. Each BE node is symmetric and receives data distributed by FE according to certain strategies. During distribution, data is directly uploaded into BE without passing through FE. Data in BE is stored in certain formats and organized by indexes. When BEs execute a SQL statement, one SQL statement is first divided into various logic execution units, and then broken down into physical execution units according to the data distribution on BEs. Each BE node executes on its own without any data communication and copying between them. In this way, StarRocks is guaranteed with extraordinary query performance.
The external interface of StarRocks is compatible with MySQL protocols and standard SQL syntax. As a result, users can easily query and analyze data in StarRocks through their existing MySQL clients.
Data Management
StarRocks divides one table into various tablets, each of which is replicated and then evenly distributed among BE nodes. There are two types of division, partitioning and bucketing. Partitioning (or sharding) helps a table to decompose into multiple partitions, for example, according to time (a day, a week, etc). In bucketing, partitions can be subdivided as tablets into buckets based on the hash function of one or more columns. The sizes of buckets could be determined by users themselves. The distribution information of tablet replicas is well managed in StarRocks.
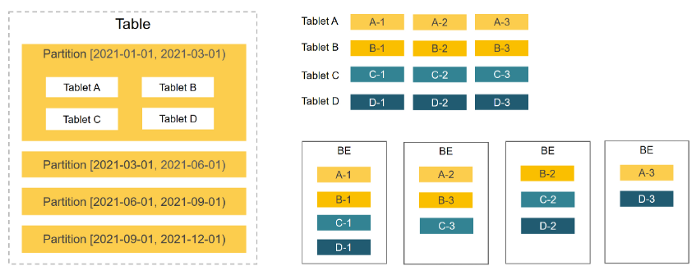
These kinds of divisions allow StarRocks to conduct parallel processing on all tablets when executing SQL statements, and thus fully utilize the computing power provided by multiple machines and cores. It is noteworthy that tables of different sizes could generate different numbers of tablets, which makes sure that different-sized tables occupy appropriate resources in large-scale clusters. Also, these types of divisions bring the advantage of high concurrency since concurrent requests are handled by various physical nodes.
The location of tablets is not fixed on specific physical nodes. So, when the number of BE nodes fluctuates, such as during scaling up and down, tablets in StarRocks move automatically without affecting the online service. More specifically, as nodes increase in number, some tablets are automatically balanced to new nodes in the background, so that data can be allocated more evenly within the cluster. As nodes decrease, tablets on nodes going offline are balanced to other surviving nodes to prevent replicas from missing. So DBAs can benefit largely from this kind of user-friendly autoscaling and are spared from manual redistribution of data.
Storage replication in StarRocks sets the quantity to 3 as default. Replicating tablets helps to ensure improved resilience and availability of databases. So in this case, StarRocks can handle read and write requests as usual without being affected by the failure of an individual node. What’s more, adding replicas helps to enhance concurrent query performance.
MPP
StarRocks adopts massively parallel processing (MPP) as its distributed execution framework. In this framework, a query request is split into numerous logic and physical execution units and runs simultaneously on multiple nodes. Each node enjoys exclusive resources (CPU, memory). MPP can make efficient use of resources during each query and enhance query performance through horizontal scaling.
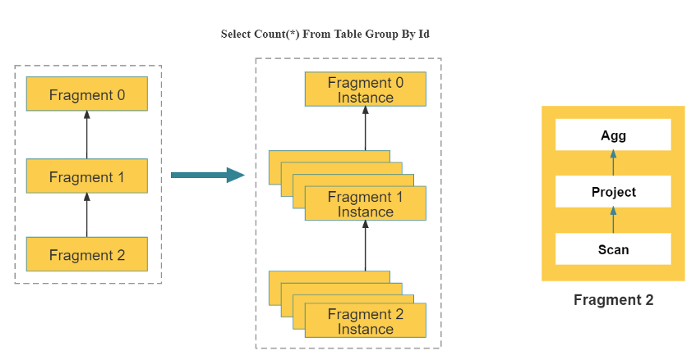
As shown in the diagram above, StarRocks splits a query into multiple logical execution units (also called Query Fragment). Each logical execution unit contains one or more operators, for example, Scan, Filter and Aggregate operators in the above diagram. One logical execution unit runs on one or more physical execution units, depending on the computation resources each logical execution unit requires. The physical execution unit is the smallest scheduling unit and each is responsible for only part of the data involved in a query. It is scheduled to and implemented on certain computing nodes. Because of the varying degrees of complexity in logical execution units, each logical execution unit uses different numbers of physical execution units, which will increase resource utilization and improve query speed.
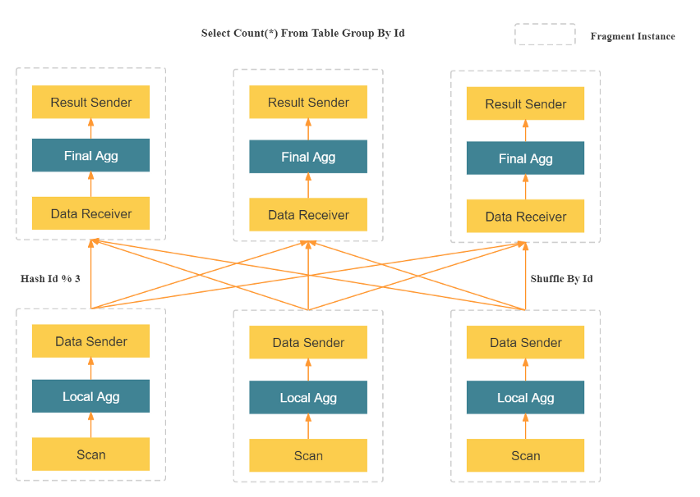
Unlike the scatter-gather pattern used by many other data analytics products in their distributed computing framework, MPP can utilize more resources to process query requests. In the scatter-gather pattern, aggregate operators run only on gather nodes during the final phase of computation. However, by using MPP, data is shuffled to multiple nodes which will run aggregate operators together. This leads to distinct improvement of performance for StarRocks over other products using the scatter-gather pattern when it comes to complex computations (e.g. Group By High-Cardinality column, join on large tables and so on).
Native Vectorized Execution Engine
Native vectorized execution engine allows StarRocks to fully utilize the processing power of the CPU. More specifically, native vectorized execution supports column-oriented data management and processing. As a result, this kind of engine allows StarRocks to store data, organize in-memory data and run SQL operators by columns. In this way, column-oriented data management makes effective use of CPU cache, and column-oriented computation creates fewer virtual functions and selection statements, which will improve the efficiency of pipelining in the CPU.
On the other hand, the native vectorized engine makes full use of SIMD instructions in the CPU. This allows StarRocks to function with fewer instructions. It is confirmed by standard benchmark testing that StarRocks’ native vectorized engine can improve the overall performance by 3 to 10 times when implementing operators.
What’s more, the vectorized engine provides StarRocks with the technology of Operation on Encoded Data when implementing operators. Thus, StarRocks can implement operators on encoded strings without decoding, such as join operator, aggregate operator and expression operator. This can greatly reduce the complexity of SQL computation during execution and increase query speed by more than 2 times.
Cost-Based Optimization
In multi-table join query, in addition to execution engine, optimized execution plans can also play an essential role in improving the query performance. Because the difference between the cost of the best plan and a random choice could be in orders of magnitude. The more tables multi-table join uses, the more execution plans CBO will generate. As a result, it is an NP-hard problem for CBO to choose the optimal execution plan. Only an excellent CBO can select the relatively optimal query plan to achieve the ultimate performance in multi-table analysis.
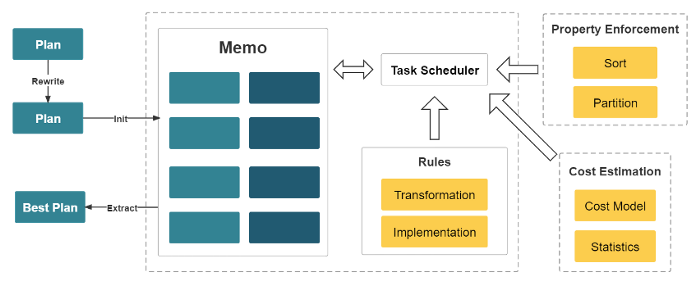
StarRocks has designed and implemented a brand-new Cost Based Optimizer (CBO) from scratch. This kind of optimizer is similar to Cascades. It is customized according to StarRock’s full vectorized engine and has made several improvements and innovations. The optimizer helps to reuse CTE, rewrite subqueries, perform lateral join, support join reorder, select distributed execution plan for multi-join queries, build dictionaries to convert low cardinality string columns into integer columns. At present, the CBO is able to optimize a set of 99 queries in the TPC-DS test.
This new CBO allows StarRocks to fully exploit the advantages of native vectorized engines so that StarRocks has excellent performances in multi-table join queries, especially the complex ones, compared with other similar OLAP databases.
Column-oriented Storage Engine that Supports Real-time Data Updates
StarRocks adopts columnar storage engines where data is stored in column format. In this way, data of the same type are stored consecutively. On the one hand, StarRocks can obtain higher compression ratios and reduce storage costs when using more efficient encoding techniques. On the other hand, column-oriented storage speeds up database query performance by reducing I/O. Also, in most OLAP scenarios, queries will only involve a few columns. Compared with row-oriented databases, column-oriented databases allow queries to read those relevant columns, and thus significantly reduce disk IOPS.
StarRocks provides quasi-real-time data service, ingesting data at second-level latency. During data ingestion, StarRocks’s storage engine guarantees the atomicity, consistency, isolation, and durability (ACID) properties of each transaction. For example, atomicity means that the transaction of ingesting a batch of data is all-or-nothing. That is, the ingestion must either fully happen, or not happen at all. Isolation means that concurrent transactions in StarRocks do not affect each other. StarRocks adopts snapshot isolation to ensure that all reads made in a transaction by other users and systems will see a consistent snapshot of the database.
StarRocks provides efficient ways to update data, such as upsert mode and append mode. Upsert mode can be realized by using several methods, among which the method called “Delete and insert” is the most efficient one. The method “Delete and insert” uses the primary index and secondary indexes, avoids sort and merge operations, in order to quickly filter large amounts of data. Thus, it is possible to guarantee extremely fast query performance in databases with large numbers of updates.
Intelligent Materialized Views
Intelligent materialized views provided by StarRocks help to speed up queries. StarRocks provides real-time materialized views. Compared with non-real-time materialized views that need to be refreshed manually in other databases, StarRocks’s real-time materialized views are automatically updated with changes made to the base tables. Also, StarRocks automatically selects suitable materialized views to accelerate queries. When StarRocks conducts query planning, it will rewrite queries to fetch results from appropriate materialized views in order to increase the speed of queries.
StarRocks’s materialized views can be created and deleted flexibly on demand. Users don’t need to build materialized views at once when base tables are created. Instead, StarRocks allows users to determine whether it is worthwhile and cost-effective to create materialized views after bases tables are created. Also, StarRocks will automatically optimize materialized views in the background.
Use Cases
StarRocks can provide satisfying performance in various data analytics scenarios, including multi-dimensional screening and analysis, real-time data analytics, ad hoc analysis. StarRocks also supports thousands of concurrent users. As a result, StarRocks is widely used by companies in business intelligence, real-time data warehouse, user profiling, dashboards, order analysis, operation, and monitoring analysis, anti-fraud, and risk control. At present, over 100 medium-sized and large enterprises in various industries have used StarRocks in their online production environment, including Airbnb, Jingdong, Tencent, Trip.com and other well-known companies. There are thousands of StarRocks servers running stably in the production environment.
WeChat, an instant messaging software for smart terminals launched by Tencent, is the mobile application with the largest number of users in China, with daily users exceeding one billion. WeChat’s multi-dimensional monitoring platform originally used Apache Druid® as its underlying data analytics system, but it encountered problems such as complicated system architecture, complex operation and maintenance. Also, Apache Druid doesn’t support standard SQL syntax, custom partitions and only offers poor performance when querying against high-cardinality columns. However, after deploying StarRocks, WeChat’s multi-dimensional monitoring platform can not only create custom partition, but also access duplicate and aggregate data, build powerful materialized views, and support high-concurrent queries. Currently, StarRocks can import data at a maximum speed of 70,000,000 pieces per minute, with a daily import of around 60 billion pieces. With the help of StarRocks, the average query time of the monitoring platform has been reduced from 1200ms to about 500ms, and the slow query time has been reduced from 20s to 6s.
Trip.com is a one-stop travel platform globally, integrating a comprehensive suite of travel products and services and differentiated travel content. The company’s e-commerce platform is the largest hotel distribution channel in China. Trip.com originally used ClickHouse to support its intelligent data platform, but it suffered from ClickHouse’s inability to support standard SQL and high concurrent queries, making the entire data system complex and difficult to operate and maintain. After adopting StarRocks, the intelligent data platform can use standard SQL queries, support high concurrency and horizontal scaling, making it easy to operate. At present, 70% of real-time data scenarios on the Trip.com’s data intelligence platform have utilized StarRocks. The query response time is around 200ms on average, and the number of slow queries over 500ms greatly decreases, while costs of manpower and hardware are greatly reduced.
Conclusion
StarRocks is a new-generation and high-speed MPP database for nearly all data analytics scenarios. By using core technologies such as native vectorized execution engine, CBO, and MPP execution framework, StarRocks can achieve blazingly fast analysis in a variety of data analytics scenarios, especially, the complex ones that involve multi-table join. Moreover, StarRocks offers user-friendly operation and management, and smooth connection to upstream and downstream systems. With StarRocks, business data analytics will be more agile and generate much more profit for your companies.
Apache®, Apache Druid® and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
