DiDi Chuxing Technology Co., Ltd., commonly known as DiDi, is a Chinese multinational ride-sharing company headquartered in Beijing. It is one of the world's largest ride-hailing companies, serving 550 million users across over 400 cities.
Architectural Challenges for Real-Time Risk Features
Financial risk control features help institutions identify and mitigate risks, such as a user’s “last credit application submission time.” These features often require large-scale real-time processing, typically handled using Lambda and Kappa architectures: Kappa for recent (≤7 days) features, Lambda for longer-term data.
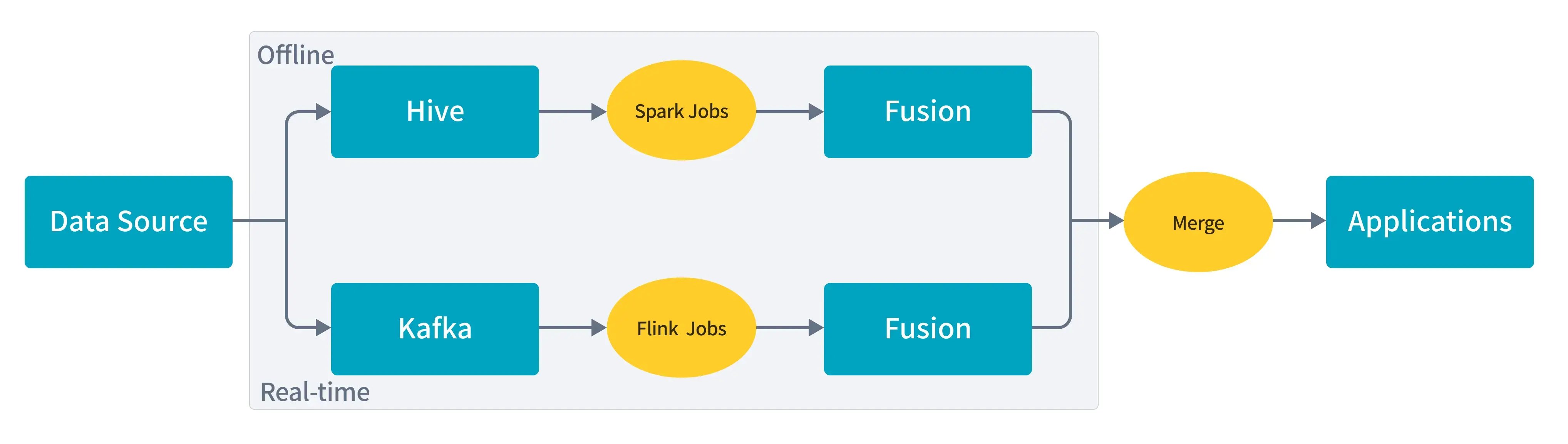
(Lambda Architecture for Real-Time Features)
In Lambda, raw data flows through both real-time and batch pipelines, with results merged at query time—adding complexity due to duplicated logic and storage.
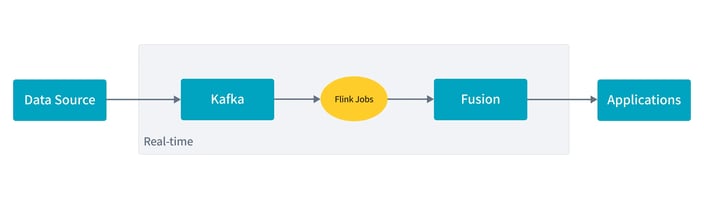
(Kappa Architecture for Real-time Features)
Kappa simplifies this by removing the batch layer and using a single streaming pipeline, reducing development costs. However, its limited storage and slow reprocessing make it unsuitable for historical data.
In practice, real-time and offline features are often developed separately, worsening inefficiencies and coordination overhead. To solve this, a unified, low-cost stream-batch architecture that improves development efficiency across real-time and offline scenarios is needed.
Evaluation
DiDi explored unified stream-batch processing via two main paths: unified computing and unified storage.
Unified Computing
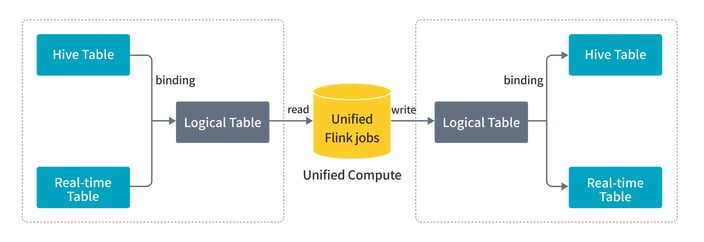
With unified computing, the plan was to have DiDi's platform use Flink to unify stream and batch logic under one SQL, enabling both periodic and real-time jobs. However, stream and batch would still run separately—streaming on Flink with a custom windowing system, and batch on Spark. Due to high migration costs, this approach couldn't fully address the company's challenges.
Unified Storage
This model stores all data in a unified data lake, enabling flexible access via Hive, Spark, or Flink. While useful for offline workloads, it lacks true real-time performance. Writes are micro-batched, latency is too high, and concurrency is low—making it unsuitable for real-time risk control features requiring sub-second latency and high QPS.
To support real-time ingestion, updates, analytics, and high concurrency with low latency, DiDi needed a high-performance OLAP engine.
StarRocks vs. ClickHouse
After evaluating both StarRocks and ClickHouse, DiDi chose StarRocks.
StarRocks offers vectorized execution, MPP architecture, cost-based optimization, intelligent materialized views, and real-time updatable columnar storage. It supports both batch and streaming ingestion, queries over data lake formats, and integrates well with MySQL protocols and BI tools—making it a strong fit for DiDi's real-time risk control needs.
The table below summarizes DiDi's feature comparison for the two engines.
| Evaluation Criteria | StarRocks | ClickHouse |
| Learning Cost | Supports MySQL protocol | SQL syntax covers over 80% of common use cases |
| Join Capabilities | Good (flexible through star schema model and adaptable to dimension changes) | Weaker (relies on wide tables to avoid join operations) |
| High Concurrency QPS | Tens of thousands | Hundreds |
| Data Updates | Supported (simpler, supports various models, primary key model fits our business scenarios) | Supported (provides multiple business engines) |
| SSB Benchmark | In 13 SSB benchmark queries, ClickHouse’s response time is 2.2x that of StarRocks, with worse table performance | |
| Data Ingestion | Supports second-level data ingestion and real-time updates, offering reliable service capabilities | Slower ingestion and updates; more suited for static data analysis |
| Cluster Scalability | Online elastic scaling | Requires manual intervention, higher operational cost |
Validation
To validate StarRocks for real-time features, DiDi followed a minimal-risk trial-and-error approach, verifying feasibility in process, query performance, and data ingestion. They used their largest credit table with both real-time and offline features, holding over 1 billion rows and 20GB+ in size.
Data Import
-
Batch import (11 minutes)
-
Real-time import (1s latency)
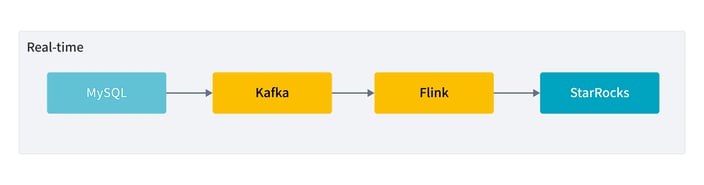
Query Efficiency
StarRocks supports MySQL protocol, so DiDi used MySQL clients for querying.
Benchmark results for different query scenarios are shown in the table below:
| Scenario | Time (ms) |
| Prefix Index Hit | 20-30 |
| Secondary Index Hit | 70-90 |
| No Index Hit | 300-400 |
Concurrency Performance
DiDi used their internal platform’s StarRocks query service to benchmark without additional server-side development.
Configuration: Domestic test cluster (3 FEs + 5 BEs), prefix index query.
| QPS | 100 | 500 | 800 | 1100 | 1500 |
| CPU Utilization | 5% | 20% | 30% | 40% | 60% |
At 1500 QPS, the service load became heavy, forcing them to stop the test before capturing results for secondary and non-indexed queries. Their observed peak QPS over 13 days was 1109. These results confirmed that StarRocks met their performance standards for real-time feature services.
Production Implementation
Architecture Design
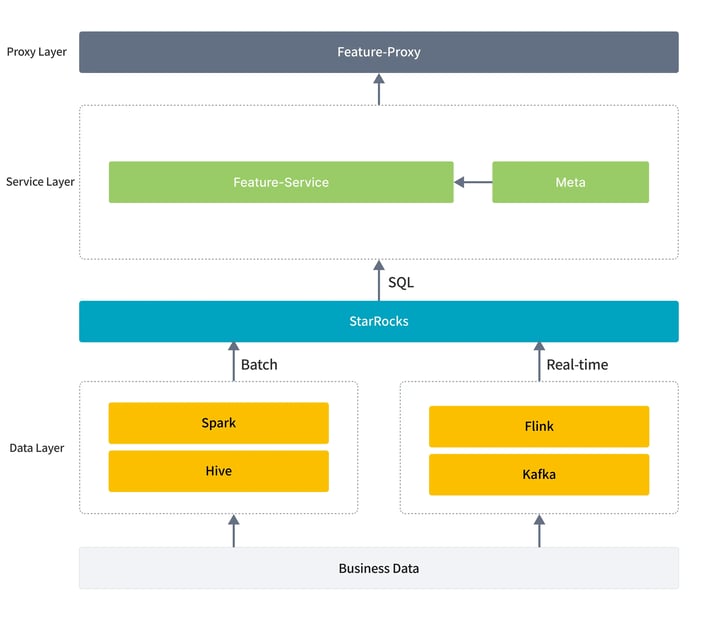
(New architecture based on StarRocks)
DiDi split the data layer into batch (historical data) and stream (real-time updates), both feeding into the same StarRocks table.
They enhanced their service layer to support StarRocks SQL queries, enabling feature queries via unified logic, which is transparent to upstream applications.
After the initial validation, they implemented support for querying features from StarRocks in the service layer and provisioned a dedicated StarRocks cluster consisting of 3 FE nodes and 5 BE nodes.
Table Design
Mirror Tables Data is classified as either log-based or business-data-based.
| Features | Log Data | Business Data |
| Data Structure | Unstructured, Semi-Structured | Structured |
| Storage Method | Time-based Incremental Storage | Business-Based Full Storage |
| Update and Delete | None | Yes |
| Source | Logs or Event Logs | Business Database |
StarRocks, as a structured database with primary key support, is ideal for business table mirroring, allowing unified stream-batch processing with minimal logic transformation. However, this approach isn’t optimal for unstructured log data.
Despite this, since 86% of features are sourced from business data, mirror tables still offer significant value.
Bucket Field Design
To optimize query performance, StarRocks employs techniques like partitioning, bucketing, vectorized execution, and a primary key model that updates via delete-and-insert. For risk control features, DiDi designed tailored tables to meet high-concurrency point lookup needs, where queries typically use consistent parameters such as uid or bizId.
Unlike traditional indexes that aim for quick lookups, bucketing in big data helps filter out irrelevant data early. DiDi uses high-cardinality fields like uid or bizId as hash bucket keys to avoid data skew. With N buckets, roughly (N−1)/N of data can be skipped per query, significantly boosting efficiency.
However, too many buckets increase metadata overhead and impact data I/O. Following version 2.3 guidance (100MB–1GB per bucket), DiDi conservatively set the bucket count to allow for growth. They also use only a single field as the bucket key to ensure flexibility and maintain fast point lookups.
Service Performance
Functional Testing DiDi configured 34 features with matching logic to validate performance.
|
Query count
|
P99 latency
|
P95 latency
|
Average latency
|
|
779178
|
75ms
|
55ms
|
39ms
|
Load Testing Results showed excellent performance for bucketed indexes and joined tables, but weaker performance for secondary/non-indexed queries.
To ensure consistent performance, DiDi bound bucket keys to feature tables in the feature management UI, making selection mandatory.
|
Scenario
|
Bucketed index
|
Secondary index
|
No index
|
Index-based join
|
|
Peak QPS
|
2300
|
18
|
10
|
1300
|
Update Timeliness DiDi created a feature using SELECT NOW() - MAX(update_time) to measure StarRocks update freshness.
|
Query count
|
% queries ≤ 1s latency
|
% queries ≤ 2s latency
|
% queries ≤ 5s latency
|
% queries ≤ 10s latency
|
Maximum latency (s)
|
|
52744
|
36.79%
|
92.53%
|
99.96%
|
100%
|
8
|
Benefits
Efficiency Gains
|
Requirements
|
Real-time and offline readiness latency
|
StarRocks readiness latency
|
Feature data volume
|
|
Requirement 1
|
7 days(offline)+1 day(real-time)+1 hr (test)
|
1 day (development)+ 1 hr (test)
|
10
|
|
Requirement 2
|
7 days(offline)+1 day(real-time)+1 hr (test)
|
1 day (development)+ 1 hr (test)
|
10
|
The above table shows the actual scheduling latency for two real-time and offline requirements. Using StarRocks feature configuration can improve efficiency by over 80%.
Under the traditional development model, the offline part of real-time and offline features usually has to wait for resource scheduling, with waiting times ranging from 2 to 7 days. As a result, the average delivery cycle for requirements is about 5 days. By adopting StarRocks development, which eliminates the dependency on offline scheduling, the development cycle was significantly shortened.
Capability Improvements
Higher Data Accuracy
-
Unified logic eliminates discrepancies between real-time and offline features.
-
Joins, deletes, and complex functions (math, string, aggregation, conditionals) are now supported.
-
MySQL support reduces the learning curve.
-
Business mirror tables reduce cognitive load.
-
Ad-hoc query support enables faster iteration and error handling.
Higher Resource Efficiency
-
Resources are used only during queries, avoiding waste from unused or duplicate features.
Future Plans
StarRocks’ MySQL compatibility and ad-hoc query support allow business teams to independently configure and validate features, boosting efficiency and responsiveness.
Currently, DiDi only operates one StarRocks cluster, so fault tolerance is limited. They plan to add backup clusters or implement tiered feature management to improve stability.
Their current implementation mainly addresses stream-batch unification for business-table-sourced data. For log-based sources (which are often unstructured and high-volume), they still rely on the Lambda architecture, and will continue to explore better alternatives.
