✍🏼 Authors:Xu Bai, Cisco Software Engineer, Apache Amoro PPMC memberHongkun Xu, Cisco Senior Software Engineer
About Cisco
Cisco Webex is a professional video conferencing software whose business scope covers core functions such as voice and video calls, online meetings, meeting devices, and instant messaging.
In the Webex team’s real-world data analysis use cases, the most common application scenarios include:
-
Troubleshooting: Analyzing meeting metrics (e.g., join latency, call quality) to locate and resolve performance issues.
-
Data Analytics: Data scientists or analysts use OLAP technology to run analytical queries and extract data.
-
Dashboard Visualization: Displaying results in dashboards and reports for real-time monitoring and insights.
Challenges
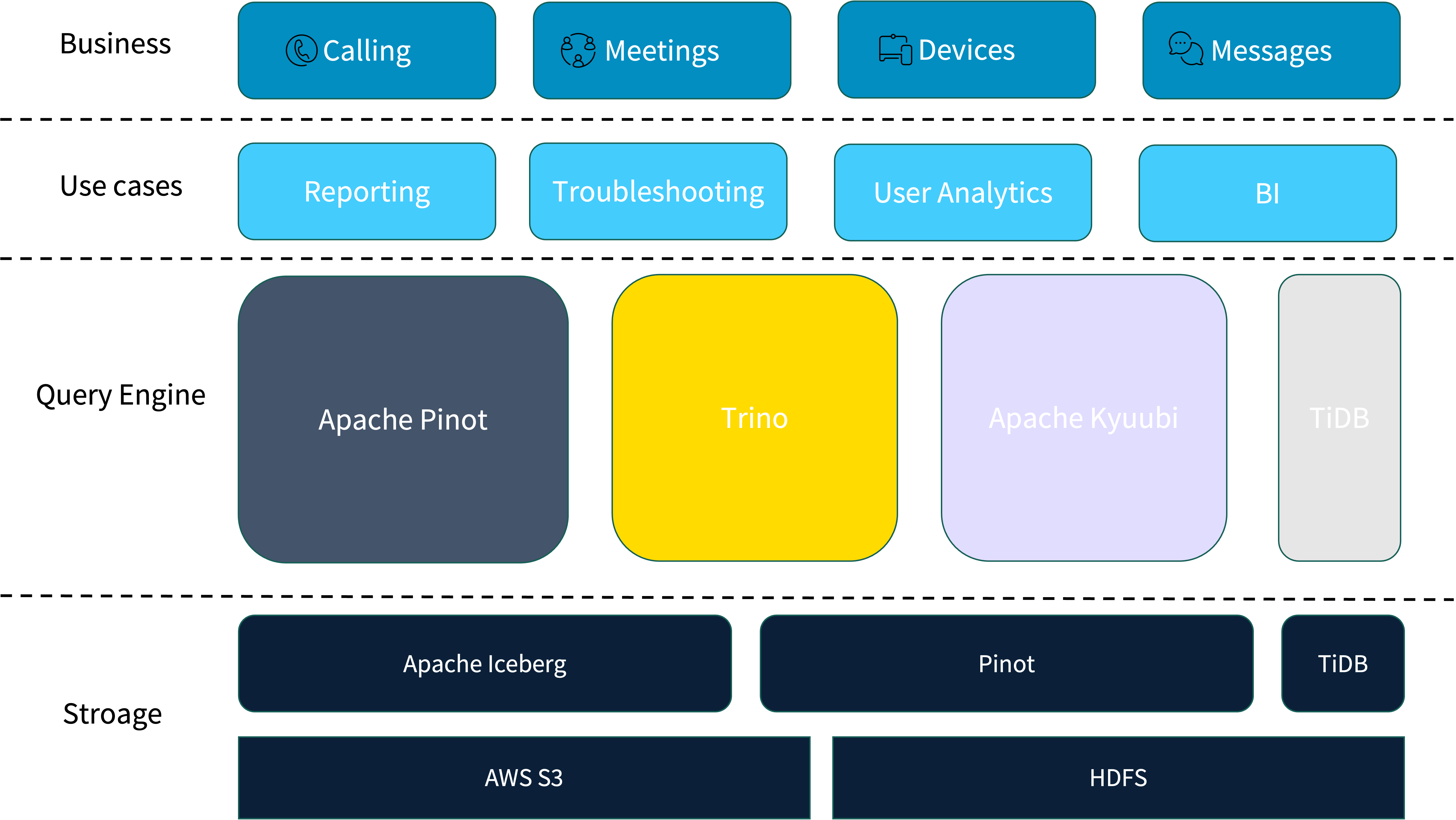
Cisco Webex's previous OLAP architecture relied on a fragmented multi-engine stack. Apache Pinot handled low-latency real-time queries but lacked subquery and multi-table join support.
Trino compensated by handling complex query logic and data lake access via Apache Iceberg, making federated queries between the two engines a common but inefficient pattern. Additional components included TiDB for aggregated results, Apache Kyuubi running on Spark for workflow orchestration, and a hybrid storage strategy across AWS S3 and private HDFS clusters to meet global compliance requirements.
This OLAP stack revealed several critical issues, with most user feedback centered on Apache Pinot:
-
High operational complexity: Running Trino and Pinot in parallel required separate monitoring systems, increasing maintenance overhead and costs
-
Stability issues: Pinot instances occasionally crashed, requiring dual-replica redundancy and complex failover with dependencies on ZooKeeper for high availability
-
Missing critical features: No multi-table joins or subquery support. Trino federated queries performed poorly without materialized views, causing redundant scans when querying 180 days of data
-
Data quality risks: Erroneous data in real-time Pinot tables required entire time range replays to repair, increasing system load and degrading freshness
-
Fragmented user experience: Multiple query engines meant analysts learned different syntaxes while poorly performing SQL required manual engineer optimization
Key Requirements for The Next OLAP Platform
The team needed a new OLAP engine delivering comprehensive improvements across performance, functionality, cost, and operations:
-
High performance: Handle complex queries (multi-table joins, subqueries) efficiently with materialized view support for common queries
-
Semi-structured data support: Flexibly process frequently changing schemas where different dates may have different fields or dimensions
-
Unified query experience: Single query system to simplify workflows, reduce analyst learning costs, and ease platform maintenance
-
Lower TCO: Move data from Pinot to cost-efficient storage (S3 or HDFS) while leveraging adaptive compression (ZSTD) and compaction for better resource utilization
Solution
.jpg?width=1944&height=866&name=Cisco%20%26%20StarRocks%20Connect%202025%20V2_trans%20version%20(1).jpg)
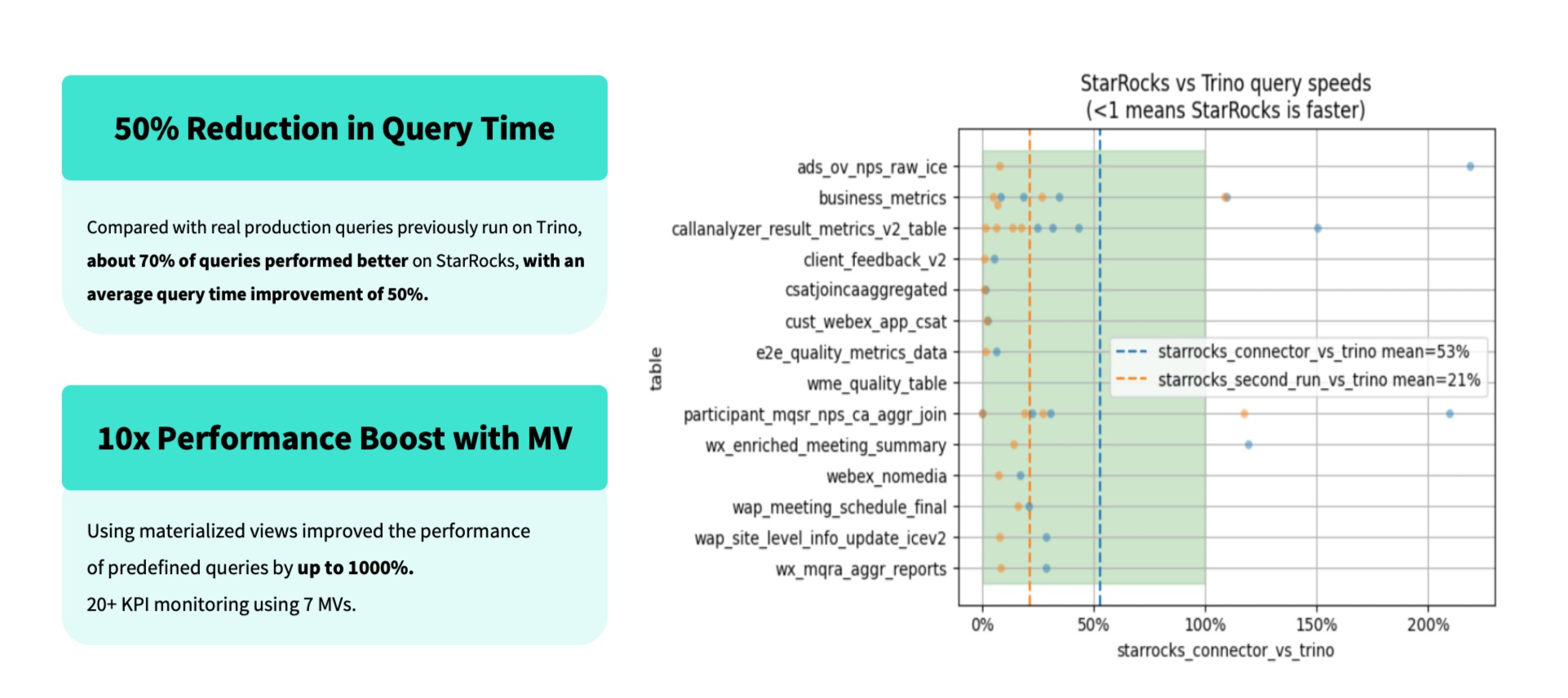
After adopting a disaggregated storage-compute architecture, as outlined above, we focused on evaluating the performance of StarRocks and Trino under real-world business workloads. Based on production queries, we conducted a detailed comparison test.
The results showed that:
-
Under the same business query scenarios, about 70% of queries ran faster on StarRocks than on Trino.
-
Average query latency improved by around 50% compared to Trino.
-
Even in the second query (cache-hit scenarios), StarRocks maintained a 21% performance advantage on average.
-
The team predefined a batch of common SQLs managed via materialized views, enabling reuse across multiple query scenarios and improving overall query performance by over 10×.
We will now outline some of our primary strategies in adopting StarRocks.
HPA Auto Scaling
.jpg?width=1953&height=793&name=Cisco%20%26%20StarRocks%20Connect%202025%20V2_trans%20version%20(2).jpg)
At the resource management layer, we built automatic scaling capabilities based on Kubernetes. Most components now run in a Kubernetes environment, where HPA (Horizontal Pod Autoscaler) dynamically monitors the CPU and memory usage of CN Pods to enable on-demand scaling of compute resources.
When workloads decrease, the system automatically releases compute capacity. To ensure that ongoing tasks are not affected, the platform checks the Pod’s status before shutdown and only reclaims resources after SQL execution is complete, achieving graceful shutdown.
Self-Help Provisioning
.jpg?width=1795&height=905&name=Cisco%20%26%20StarRocks%20Connect%202025%20V2_trans%20version%20(3).jpg)
The unified permission framework integrates Apache Ranger for rules and LDAP for authentication, managed through Cisco's UDP (Unified Data Platform) Auth system. Users now request access with automatic approval by maintainers or workflows, replacing manual Trino authorization while enhancing security and reducing administrative overhead.
To unify the query layer, dialect conversion for Trino and Pinot automatically translates around 90% of queries, eliminating the need for analysts to learn multiple SQL syntaxes while ensuring consistent results across all architecture models.
StarRocks' Features That Proved Useful in Pinot Migration
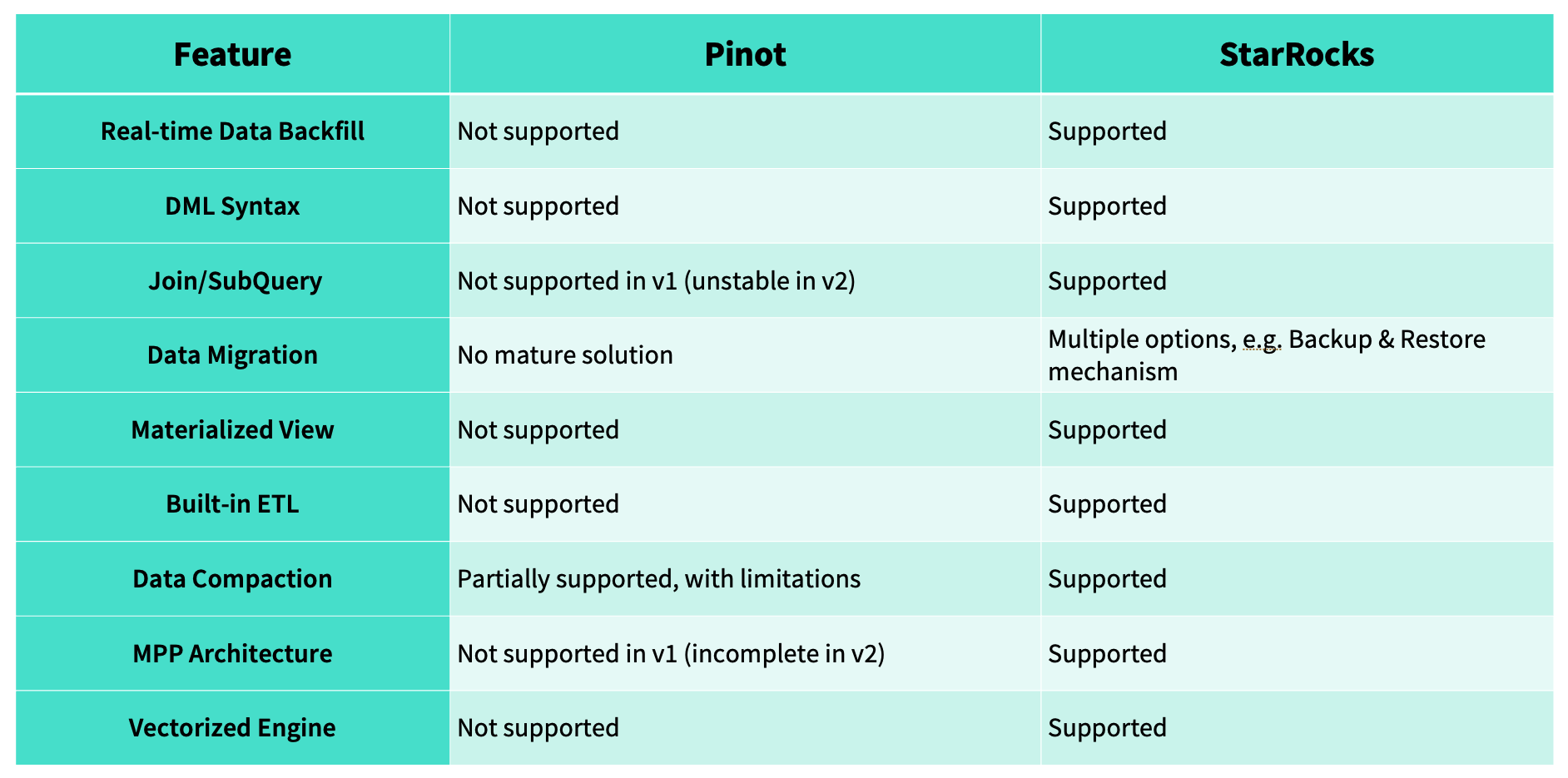
The Pinot to StarRocks upgrade addressed multiple structural limitations:
-
Partitioning: Pinot stores multi-day data in single segments, making precise backfills impossible. StarRocks' native daily partition management allows quick reloads of only affected partitions
-
DML operations: Pinot lacks INSERT, DELETE, UPDATE support, forcing full reloads. StarRocks supports standard DML for flexible corrections
-
Joins and subqueries: Pinot's unstable join support required inefficient Trino federated queries. StarRocks provides native support with operators pushed to storage
-
Data migration: Pinot lacked robust migration tools. StarRocks provides mature Backup & Restore and Cross-cluster Data Migration Tool for automated synchronization
-
Materialized views: Pinot relies on external aggregation jobs. StarRocks supports efficient incremental refreshes at 15-minute or hourly intervals
-
Built-in ETL: StarRocks handles transformations like INSERT INTO SELECT natively, simplifying workflows
-
Data compaction: Pinot's upsert tables can't compact duplicates, causing bloat. StarRocks automatically merges and retains only latest data
-
MPP and vectorization: StarRocks' native MPP architecture and vectorized engine query billions of rows in approximately one second
SQL Dialect Transformer
.png?width=2194&height=752&name=image%20(16).png)
Our first step was building the SQL Dialect Transformer to migrate existing queries without manual changes. Since business teams saw little value in refactoring SQL—and Pinot already performed well—we created the Pinot Dialect Transformer to automatically convert Pinot SQL into StarRocks-compatible syntax.
Inspired by Trino Dialect, it adjusts function names, parameters, and syntax differences during parsing. Tests show it automatically converts over 70% of queries, greatly reducing manual effort while remaining easily extensible for new functions and syntax.
Rack-Based Resource Isolation
.png?width=2232&height=912&name=image%20(17).png)
Since StarRocks doesn’t yet support tenants, we implemented resource isolation using Rack policies. Within a 30-node cluster, different machine groups serve different services (e.g., Device, Meeting, Calling), ensuring heavy queries from one workload don’t affect others.
Initially, StarRocks couldn’t automatically assign replicas within the same rack label (e.g.,
rack:device), requiring multiple sub-racks (device1, device2, etc.). We worked with the community to add an optional scheduling parameter for rack-level replica control, and optimized rebalance logic and scheduling to better respect rack topology and availability.Flat JSON Optimization and Best Practices
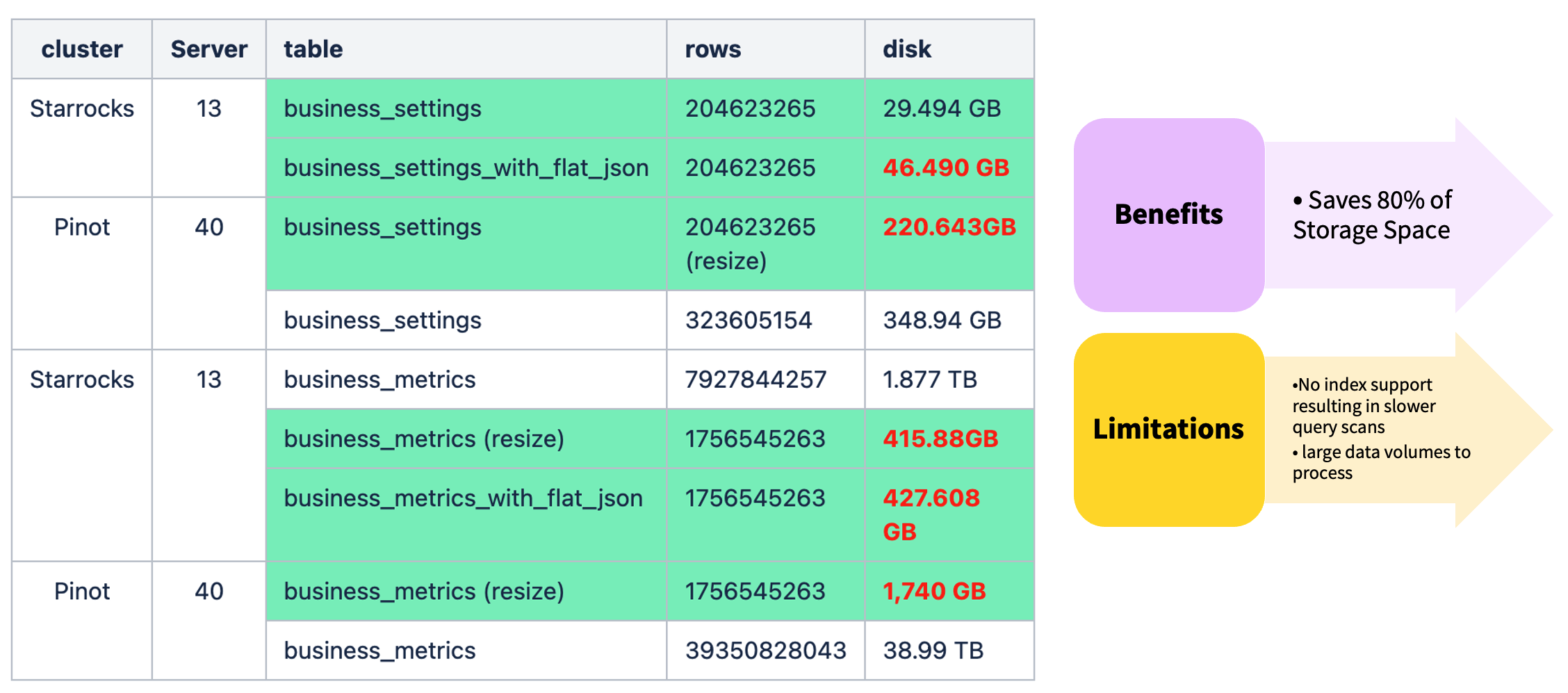
After migrating to StarRocks, we explored Flat JSON to handle large volumes of semi-structured data. Expanding JSON fields into materialized subcolumns reduced disk usage by about 80%, though the lack of index support still caused some query overhead.
We also optimized bucket and sort key design to isolate heterogeneous data across tablets and segments, improving data locality. Testing showed this reduced query latency by up to 80% compared to the original implementation.
Results
The migration to StarRocks delivered measurable performance improvements and operational simplification. To summarize as follows we achieved the following:
Query Performance
-
70% of queries ran faster on StarRocks than Trino
-
Average query latency improved by 50% compared to Trino
-
Cache-hit scenarios maintained 21% better performance
-
Materialized views improved common query performance by over 10x
-
Flat JSON optimization with proper bucket and sort key design reduced query latency by up to 80% while cutting disk usage by approximately 80%
-
Vectorized execution engine handled billions of rows in approximately one second
Operational Simplification
-
Automatic SQL dialect conversion handled 90% of Trino queries and over 70% of Pinot queries without manual rewrites
-
Single unified query interface eliminated the need to learn multiple SQL syntaxes
-
HPA-based auto-scaling on Kubernetes enabled graceful compute resource management
-
Self-service permission provisioning through UDP Auth reduced administrative overhead
The unified architecture eliminated the complexity of running parallel query systems (Trino and Pinot), reducing operational burden while improving performance. Business analysts now work with a single, consistent interface for troubleshooting, analytics, and dashboard visualization across Webex's global services.
What's Next for Cisco
Our next phase of optimization focuses on three areas:
-
Query Insight enhancements: Visualize operator-level execution times and provide intelligent tuning suggestions
-
Semi-structured data performance: Continue Flat JSON optimization and advance Variant Shredding to close the gap with Pinot
-
Text search capabilities: Expand inverted index support for primary key and storage-compute separation architectures while exploring new engines like Tantivy or built-in StarRocks text search
Want to discover more real-world StarRocks analytics use cases? Join StarRocks’ Slack channel to learn more.
