✍🏼 About The Author:Author: Jacky Wu is a dbt-starrocks contributor and Senior Enterprise Solution Manager at SJM Resorts. He specializes in enterprise data architecture, DataOps practices, real-time analytics, and works closely with engineering and business teams to deliver scalable, governance-ready data platforms.
The Core Role of dbt in Data Modeling and Governance Automation
Key Capabilities of dbt
At its core, dbt is a framework for building and governing analytics data through code. Raw data processed with dbt is transformed according to the principle of “data models as code,” allowing teams to define transformations, logic, and dependencies in a structured, version-controlled way. Beyond generating curated data models, dbt also produces essential governance artifacts, including data dictionaries, lineage graphs, and automated data quality tests.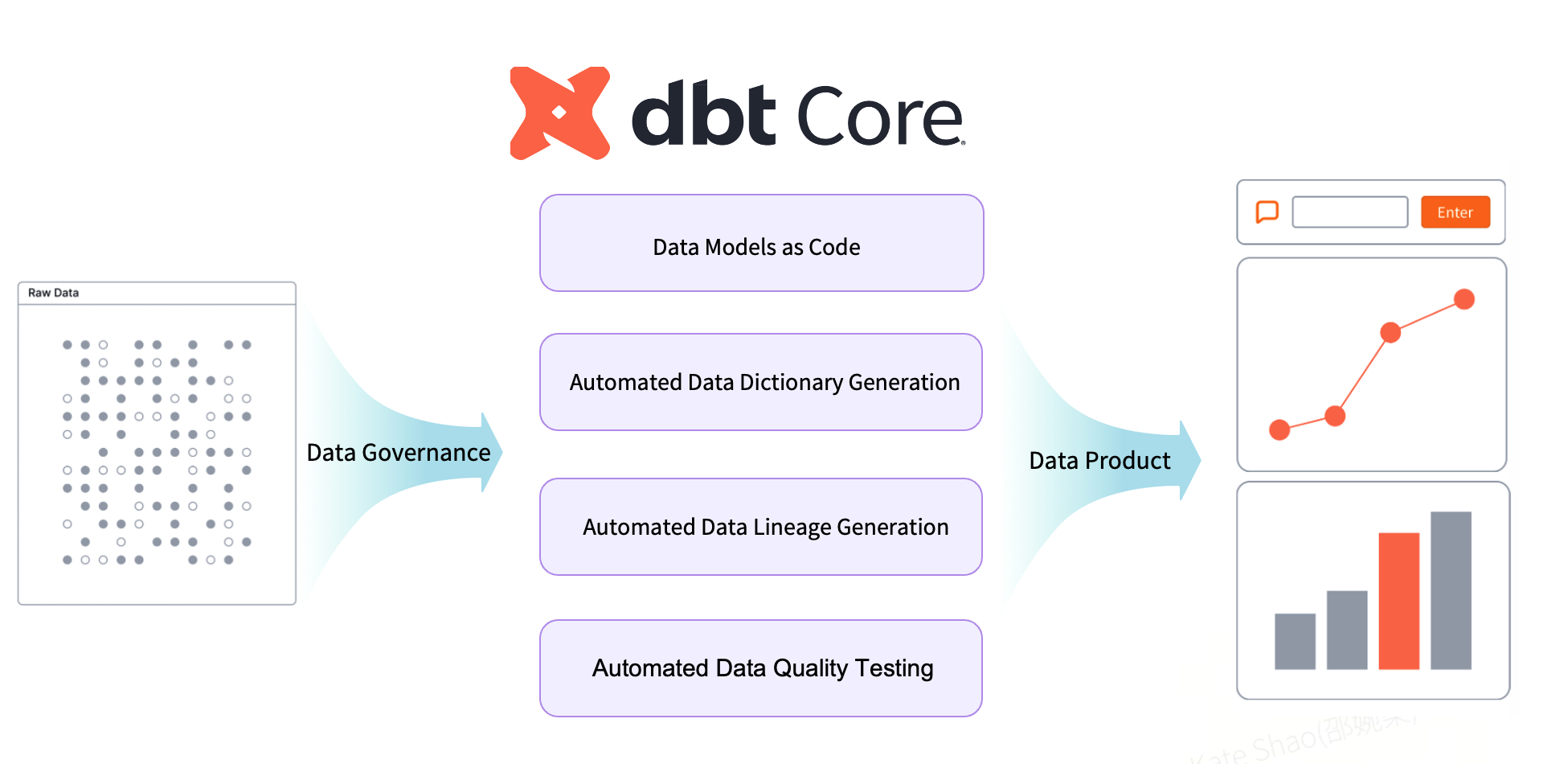
At the methodological level, dbt introduces a core concept that closely aligns with DevOps. Most engineering teams are already familiar with DevOps, which focuses on managing and collaborating on code through standardized, engineering-driven practices. dbt extends this philosophy into the data domain, applying the same engineering rigor to data development and governance.
Data Models as Code
In practice, teams typically work across multiple feature branches, with automated tests triggered during the merge process. Once changes are validated in a staging environment, CI/CD pipelines are used to promote them into production. This workflow allows data models to be versioned, reviewed, and managed with the same discipline and rigor as application code.To make this model effective in real-world analytics systems, it needs to be paired with an execution engine that can support both high-performance queries and frequent model changes. This is where the analytical database layer becomes critical.
StarRocks as the Analytical Execution Layer
StarRocks is a high-performance analytical database designed for modern, real-time analytics workloads. It follows a lakehouse-oriented architecture, enabling unified analytics across both real-time and batch data without maintaining separate systems for streaming and offline processing.
StarRocks supports high-concurrency, low-latency queries directly on fresh data, making it well suited for dashboards, operational analytics, and data-driven applications. At the same time, it integrates naturally with data lakes and ELT pipelines, allowing teams to build scalable analytics platforms without sacrificing performance or consistency.
In this architecture, StarRocks serves as the analytical execution layer where raw data is continuously ingested and stored, while dbt operates on top of it to define transformations, models, and governance logic. Together, they form a clean separation of responsibilities: StarRocks focuses on efficient data storage and query execution, while dbt manages modeling, version control, and testing.
Within this setup, dbt integrates seamlessly with ELT workflows, improving the efficiency, reliability, and overall controllability of data modeling and governance. In day-to-day development, when issues are identified in a specific data model, teams can quickly roll back changes at the branch level. With Git as the system of record, every change goes through code review and is deployed via automated CI/CD pipelines.
As a result, SQL models, materialized views, and other data objects are promoted to production through standard pull request (PR) workflows, ensuring consistency, traceability, and operational safety across the entire lifecycle.
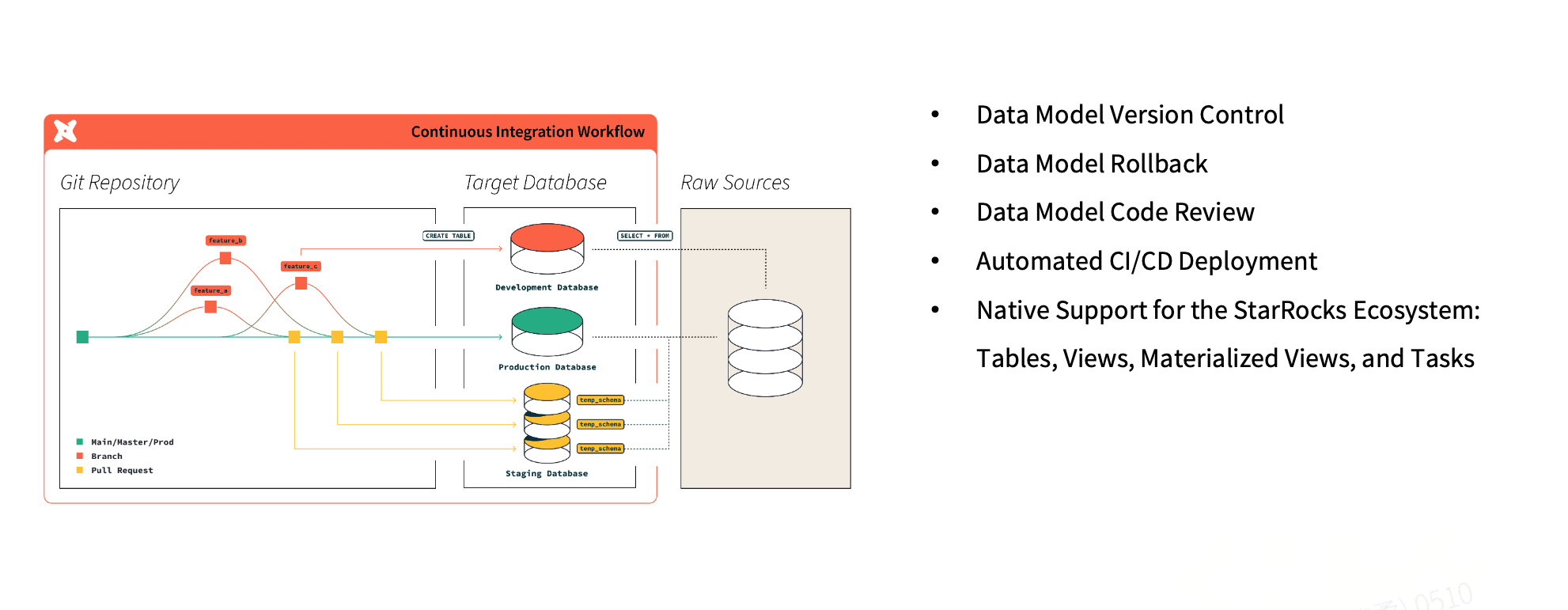
dbt also integrates seamlessly with the native StarRocks ecosystem, enabling version control across multiple types of data objects, including tables, views, materialized views (MVs), and tasks. In dbt, a model is essentially a SQL template. A typical pattern is to first create a staging model for customer data, then reuse it as a dependency for downstream custom business models. dbt automatically resolves dependencies between models and manages execution order, eliminating the need for external scheduling tools—running dbt alone is sufficient to orchestrate the entire pipeline.
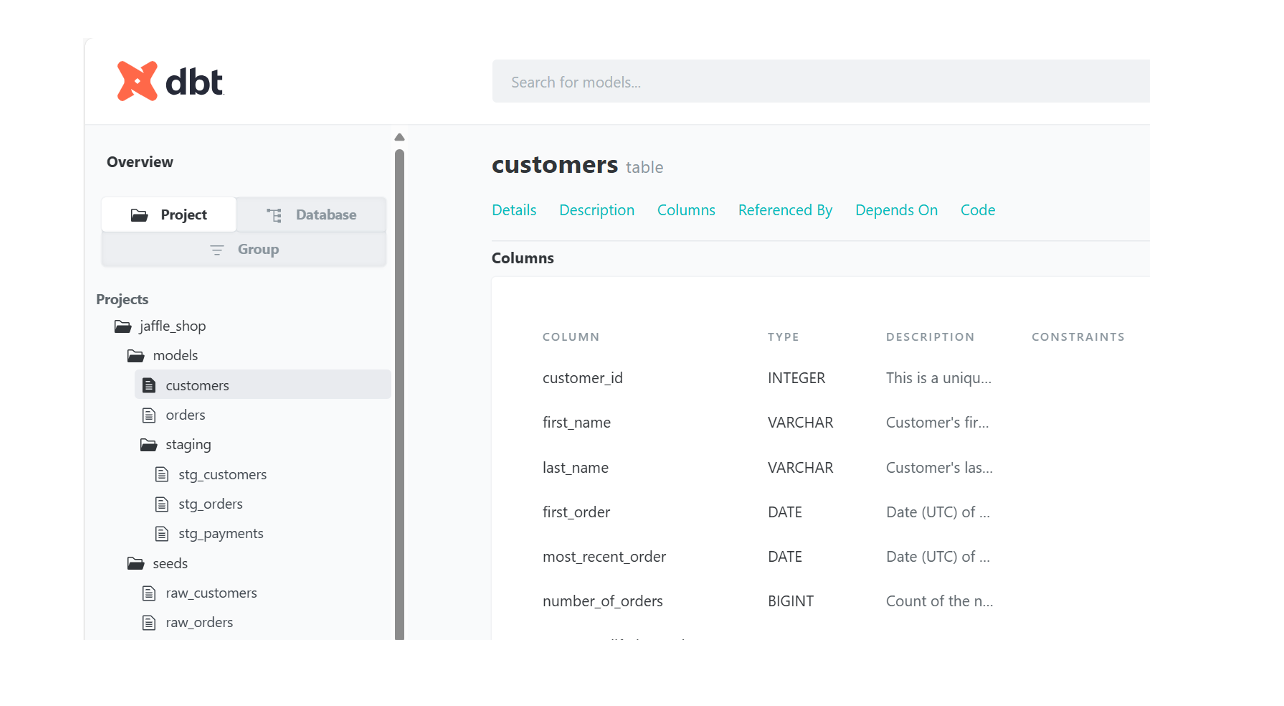
Automated Data Dictionary Generation
From a documentation and asset management perspective, dbt can automatically generate data dictionaries and other documentation artifacts. Through dbt-generated HTML documentation, teams can easily explore field definitions, business meanings, underlying SQL logic, and upstream/downstream dependencies. The documentation interface can also be customized with enterprise branding, including logos and visual styles.
Automated Data Lineage
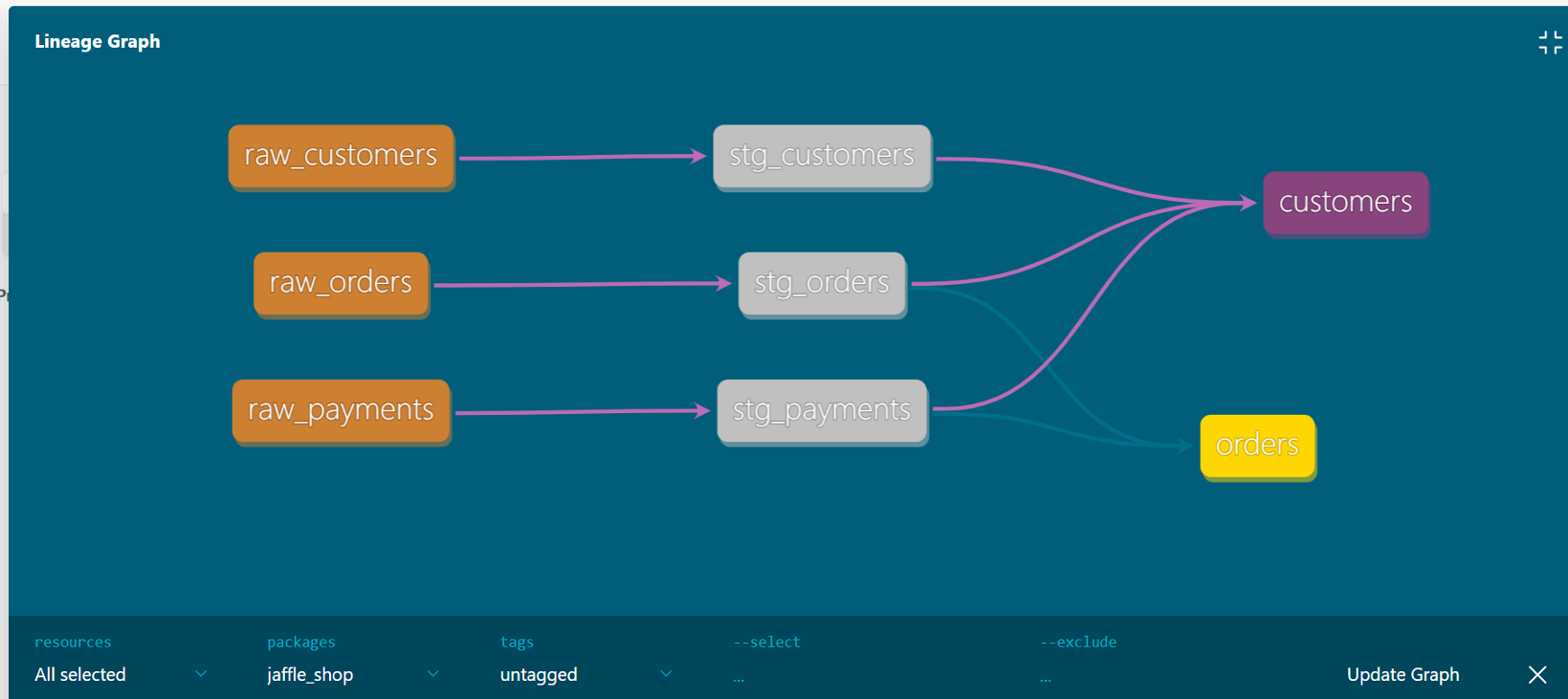
Data lineage is a foundational component of any data governance framework. Large enterprises often manage thousands of tables and a vast portfolio of data products. In industries such as hospitality, where organizations operate across hotels, restaurants, and other business lines, it is common to build a unified Customer 360 view to consolidate data assets across domains.
In these environments, even small changes to upstream raw data can have far-reaching effects. A core challenge is quickly identifying which downstream models, reports, or data products may be impacted. Data lineage addresses this need by enabling precise impact analysis, giving teams clear visibility into dependencies and helping them assess the scope and risk of upstream changes or data quality issues.
Automated Data Quality Testing
Beyond data lineage, automated data testing is a core pillar of dbt best practices. Teams can define a wide range of automated tests for their data models, such as scheduled daily validations to ensure that datasets continue to meet expected conditions. When anomalies are detected, alerts can be triggered immediately, enabling faster detection and resolution of data issues.
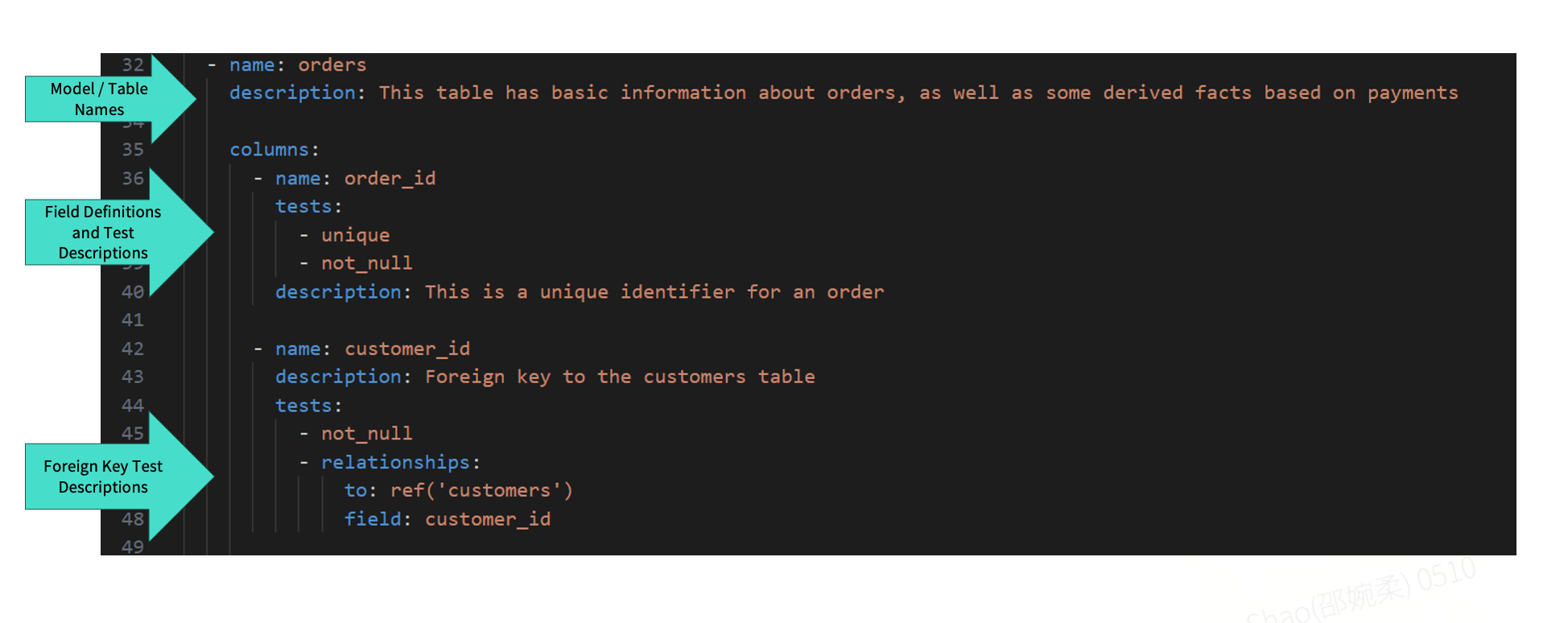
From an implementation standpoint, dbt model configurations are typically defined in YAML files. Each model includes metadata such as its name and description, which capture the model's purpose and business context, followed by field-level definitions. dbt provides a comprehensive set of built-in tests, such as unique and not_null to enforce common data quality constraints, including uniqueness and null checks.
In most OLAP databases, foreign key constraints are not enforced at the database level. To address this gap, dbt offers ref-based and relationship testing capabilities, allowing teams to validate that models are correctly referenced by downstream tables or models. These tests are also centrally managed through YAML configuration files.
In practice, some teams further enhance this workflow by using AI-assisted tools to automatically generate and batch-maintain YAML configurations, significantly reducing manual effort while improving consistency.
How DataOps Workflows Improve Agility and Control in Data Projects
Key Components of DataOps
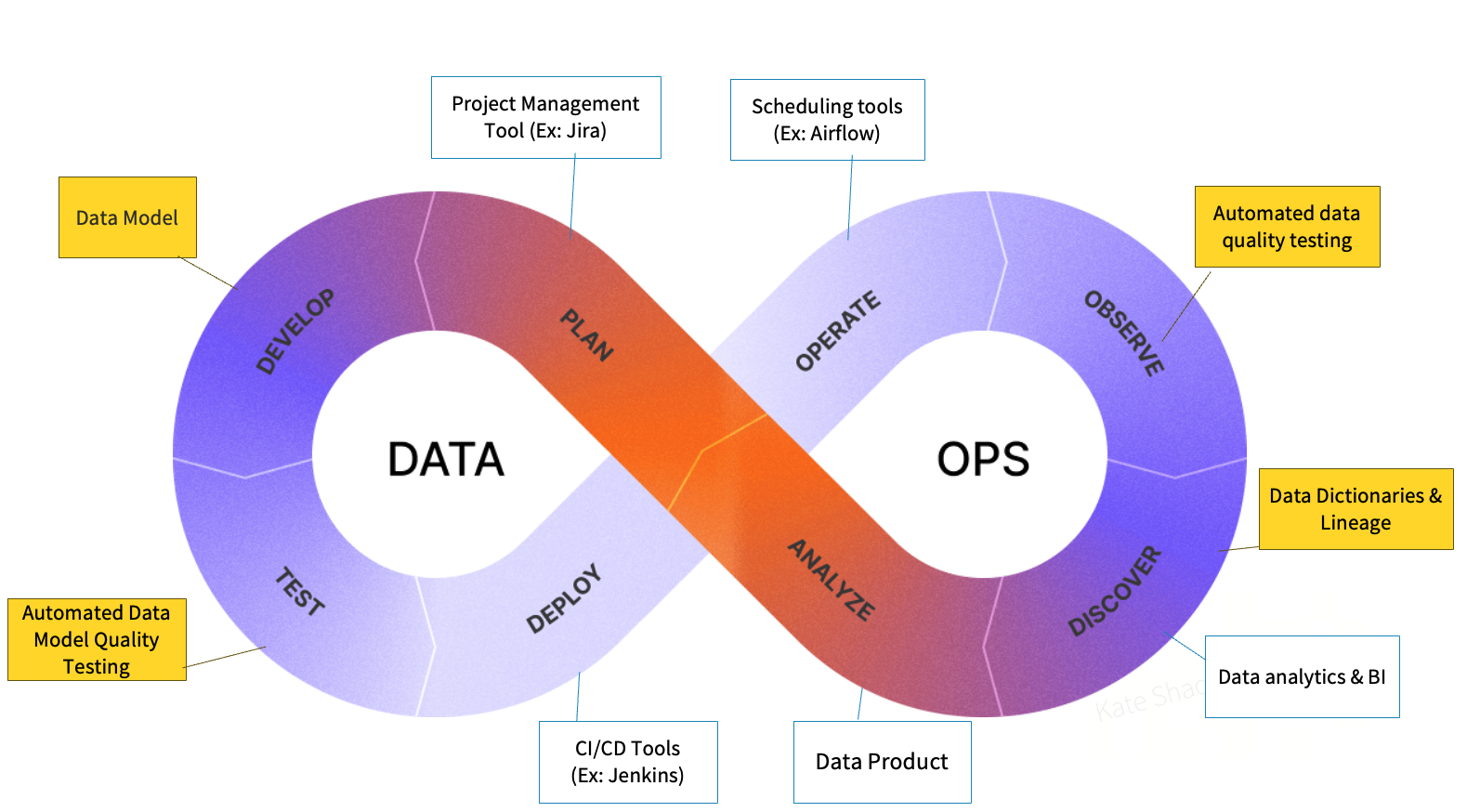
Building on the principles of DevOps, DataOps extends the same engineering mindset into the data domain. In application development, DevOps has become the standard approach for managing code development, integration, and deployment. DataOps applies these proven practices to the full data lifecycle, from development, testing, deployment, and ongoing operations to improve both speed and reliability.
In a typical DataOps architecture, the areas covered by dbt are often clearly highlighted. These include data modeling, automated data quality testing, data lineage analysis, and documentation-driven validation—all of which are native capabilities of dbt. For stages beyond dbt's scope, teams typically integrate other well-established tools to complete the workflow. Project management platforms such as Jira is used to track model changes and defects; scheduling tools manage periodic model execution and data checks (hourly or daily); CI/CD tools like Jenkins handle automated integration and deployment; and downstream analytics and BI tools support data consumption, visualization, and decision-making.
Version Control Standards: Conventional Commits

At the version control layer, experienced teams typically adopt a standardized commit convention. One widely used approach is Conventional Commits, which defines a structured format for commit messages. Its core idea is to clearly distinguish between different types of changes, such as feature enhancements and bug fixes, so that versioning and release management can be automated.
For example, when a change introduces new functionality, such as adding a new dimension to an order model, the minor version is incremented (e.g., from 2.0 to 2.1). These changes are generally backward compatible. In contrast, bug fixes only trigger a patch version increment (e.g., from 2.1.0 to 2.1.1).
Conventional Commits also make it possible to generate release notes automatically. In the past, release managers often had to manually confirm changes with developers and compile release notes by hand—a process that was both time-consuming and error-prone. With Conventional Commits in place, this workflow can be fully automated.
When commit messages follow the defined convention (for example, using the fix prefix), they can be automatically parsed and aggregated into structured release notes. Developers focus on writing clear, standardized commit messages, while the tooling handles release note generation. As part of the CI/CD pipeline, release notes are created and updated automatically with each release, requiring no additional manual effort from the team.
A CI/CD Automation Example in DataOps
In a DataOps framework, the CI/CD workflow typically starts with a Pull Request (PR). Every change is introduced through a PR, which triggers a standardized validation and deployment pipeline.
The pipeline begins with automated code quality checks, commonly referred to as linting. Similar to style and syntax validation in application development, linting tools automatically analyze SQL models and related configurations to ensure they conform to predefined standards. Once these checks pass, the changes are deployed to a staging environment.
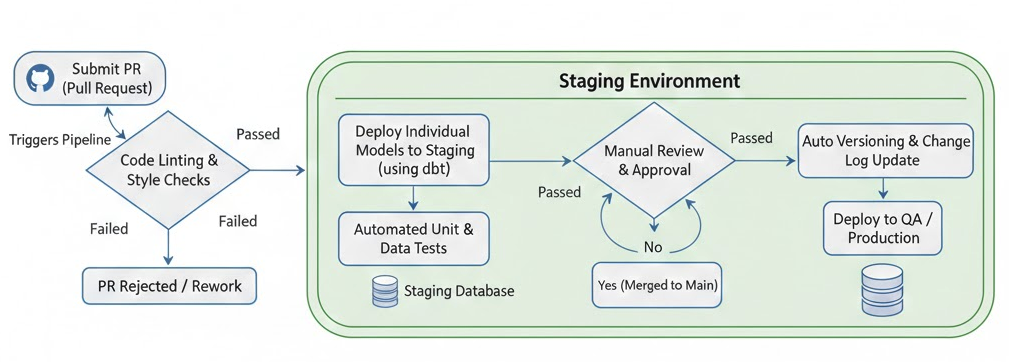
Using dbt as an example, individual models can be deployed to specific environments. This makes it possible to deploy a single model to staging and run targeted unit tests and data quality checks. After the automated tests pass, the workflow moves to a manual review stage, where reviewers examine the PR to validate the logic and assess its potential impact.
Once the changes are approved and merged into the main branch, the system automatically packages a new version, updates the change history, and promotes the release to QA or production environments. This end-to-end process ensures that data changes are delivered with both speed and control—key characteristics of a mature DataOps practice.
Technical Breakthroughs with StarRocks for Real-Time and Batch Analytics
Traditional Siloed ETL Architectures in Lake–Warehouse Separation
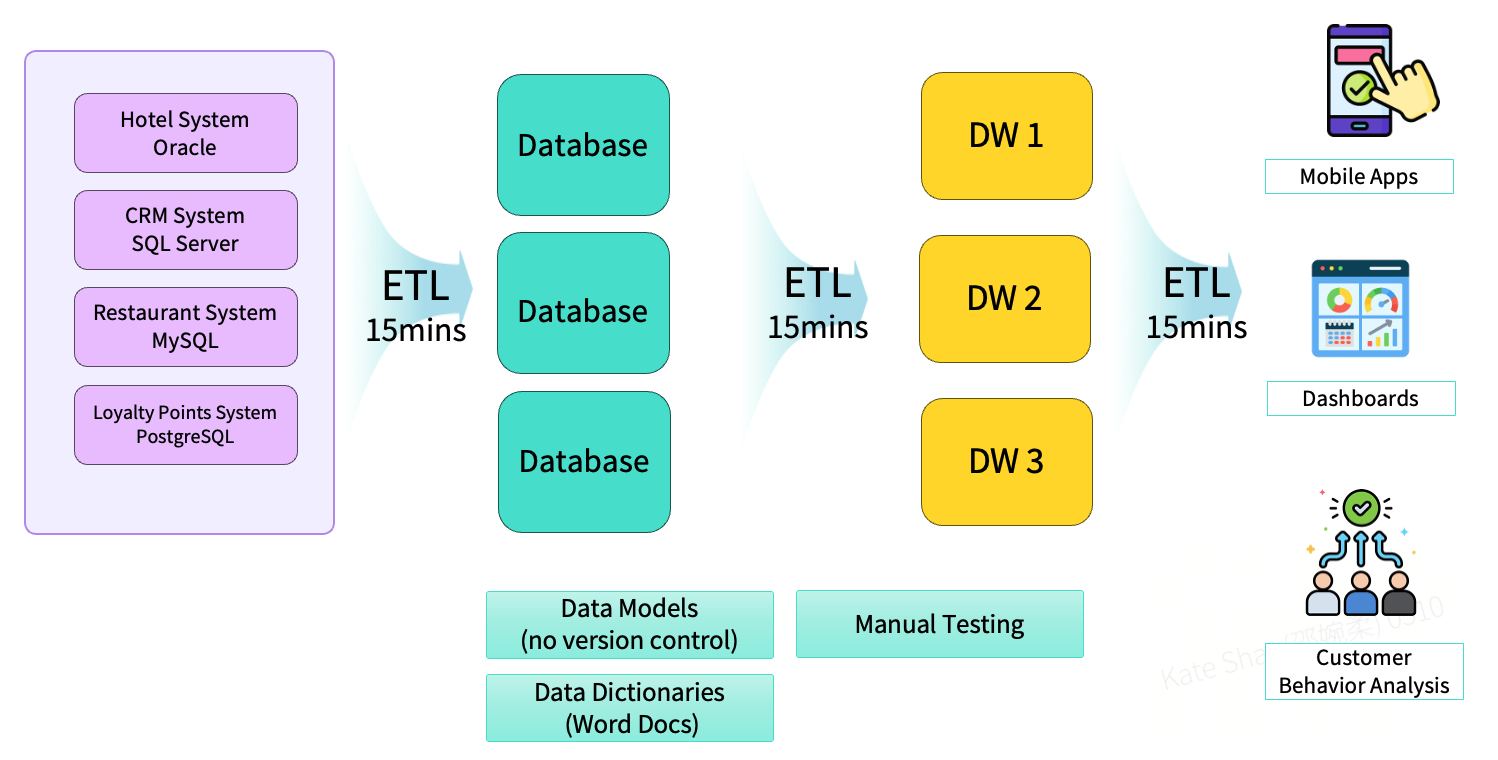
In early-stage implementations, many teams relied on siloed ETL architectures. Using a hospitality industry scenario as an example, the initial setup typically consisted of multiple independent operational databases at the source layer. ETL jobs ran on fixed schedules (for example, every 15 minutes) to extract data from these systems and load it into multiple data warehouses. In parallel, separate data pipelines were built to support mobile applications, reporting systems, and other analytical workloads.
This architecture came with several fundamental limitations. Data models lacked version control, making the system fragile and easy to break as changes accumulated. Testing was largely manual, which made it difficult to establish a consistent and repeatable quality assurance process. Documentation was also highly fragmented, often maintained as standalone Word files across different teams, resulting in poor consistency, limited traceability, and high maintenance overhead.
The StarRocks ELT Framework
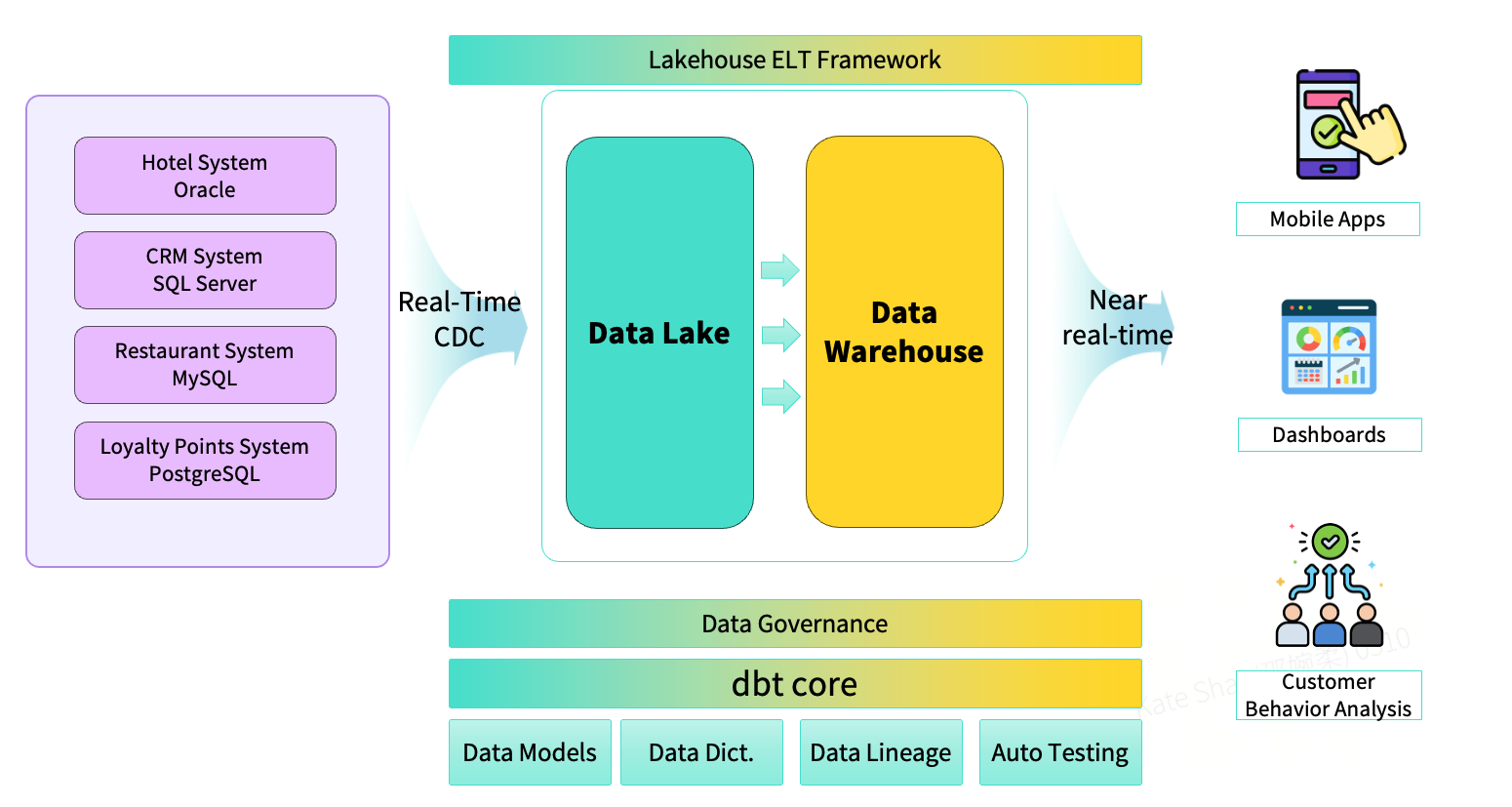
With the introduction of StarRocks as an integrated platform, the overall architecture was redesigned into a unified lakehouse model that supports both real-time and batch processing. Using real-time CDC, data from multiple operational systems is continuously ingested into the data lake. On top of the lakehouse, an ELT-based framework enables rapid construction of application-facing data products.
At the same time, data governance capabilities are implemented end-to-end across the pipeline. Version control is established around data models, data dictionaries are centrally maintained, and data lineage views are generated through tooling, providing full visibility into dependencies and impact.
Results from StarRocks + dbt + DataOps in Practice
In the re-architected system, near-real-time data simultaneously supports mobile applications, reporting dashboards, and behavioral analytics workloads. On top of this foundation, a unified “three-in-one” DataOps framework delivers several immediate and measurable benefits:
- Faster iteration and recovery. Data models built with dbt can be updated and rolled back quickly, significantly improving development velocity and incident recovery time.
- More efficient delivery through standardized pipelines. DataOps manages business requirements and data product delivery through well-defined pipelines, introducing Agile-style practices that standardize project management workflows and automated release cycles. This substantially shortens the end-to-end lead time from requirement definition to production.
- Strong consistency between models and documentation. Model definitions and their corresponding YAML files are version-controlled together in Git, creating a single source of truth. Any model change requires the related documentation to be updated; otherwise, the release pipeline will fail validation.
- Higher analytical accuracy and reliability. For enterprises operating dozens of hotel systems, data lineage analysis makes it possible to understand where a system sits within the overall data pipeline and to assess downstream impact before upgrades. In parallel, automated data testing performs continuous health checks on models, validating data correctness and alignment with expectations on a daily basis。
Want to explore what StarRocks can do for your analytics workloads? Join the StarRocks Slack to connect with the community.
