A New Choice of Column DBMS
Apache Hadoop® was developed 13 years ago. Its suppliers have been enthusiastic about offering open-source plug-ins, as well as technical solutions. This, on one hand, has resolved the problems of users, while it has also led to the high cost of maintenance, thus Apache Hadoop gradually lost its share of the market. Users are calling for a simple and scalable database at a low cost, therefore the column DDBs got increased attention.
Brief Intro to ClickHouse
ClickHouse is an open-source database by the owner of Yandex, Russia's largest search engine. It has an enhanced performance compared to many commercial MPP databases, such as Vertica, InfiniDB. ClickHouse has gained increased popularity among companies besides Yandex, for the ordinary analytical business which is more structured and has fewer data changes, they can be put into flat tables and into ClickHouse thereafter.
The competitive edges of ClickHouse to traditional big data solutions
- Rich with configurations, rely on Apache ZooKeeper™ only
- Its cluster could be linearly expanded by adding servers
High fault tolerance, asynchronous multi-master replication between different shards
Excellent mono-meter performance, it adopts vector calculation, supports optimization methods such as sampling and approximate calculation
It provides powerful support to many different data models.
Brief Intro to StarRocks
StarRocks is a full-scenario MPP enterprise-level database with extreme performance on speed. StarRocks has horizontal online scalability and financial-level high availability. It is compatible with MySQL protocol and provides important features such as a comprehensive vectorized engine and federated query of many data sources. StarRocks is committed to providing users with a comprehensive solution in the full-scene OLAP business, which is suitable for various application scenarios with high requirements for performance, timeliness, concurrency and flexibility.
The competitive edges of StarRocks to traditional big data solutions:
- Does not depend on, but can be compatible with big data ecology by query federation.
- Provide a variety of models to support different dimensions of data modeling
- Supports online elastic expansion and contraction, and can automatically load balance
- Support high concurrent analysis queries
- Support real-time data analysis. Support data import in seconds
- Compatible with MySQL 5.7 protocol and MySQL ecology
StarRocks & ClickHouse: Function Comparison
StarRocks and ClickHouse have a lot in common: both can provide superior performance, both independent from the Apache Hadoop ecosystem,both provide a master-master replication mechanism with high availability.
There are also differences in functions, performance, and application scenarios. ClickHouse is more suitable for scenarios with flat tables. If the data of TP passes through the CDC tool, the tables could be flattened in Apache Flink® and written into ClickHouse in the form of flat tables. StarRocks is more capable in terms of joins, and star or snowflake shcemas can be built to deal with dimensional data changes.
Flat Table or Star Schema?
ClickHouse: Avoid joining operations by making flat tables
Different from the TP business that focuses on point query, in the AP business, the associated operation of the fact table and the dimension table is inevitable. The biggest difference between ClickHouse and StarRocks lies in the handling of joins.
Although ClickHouse provides the semantics of join, its ability to associate flat tables is relatively weak. Complex associated queries often result in out of memory. Generally, we can consider flattening the fact table and the dimension table into a flat table during the ETL process to avoid complex queries.
At present, many businesses use flat tables to solve the problem of multi-factor analysis, which shows that flat tables do have their own unique benefits, such as:
- In the ETL process, the fields of the flat table are handled well, and the analyst can do their work without concerning the underlying logic
- Flat tables can contain more business data and are more understandable
- Flat tables are convenient for single-table query, offering better service by avoiding data mingling
Meanwhile, the flat table also makes it less flexible:
- The data in the flat table may cause the redundancy of wrong data, due to its one-to-many mechanism in the join process
- The structure of the flat table is difficult to maintain, and the flat table needs to be re-run when the dimension changes.
- The flat table needs to be pre-defined, and may not be able to fit the temporary changes.
StarRocks: Adapt to dimensional changes via Star Schema
It is fair to say that the flat table is made at the expense of flexibility, to speed up query by puting the join process adhead. But in scenarios with high flexibility requirements, such as frequent changes in the state of orders, or self-service BI analysis for business personnel, flat tables often cannot meet their needs. Thus we also need to use a more flexible schema like star or snowflake. In terms of supporting the star/snowflake schema, StarRocks works better than ClickHouse.
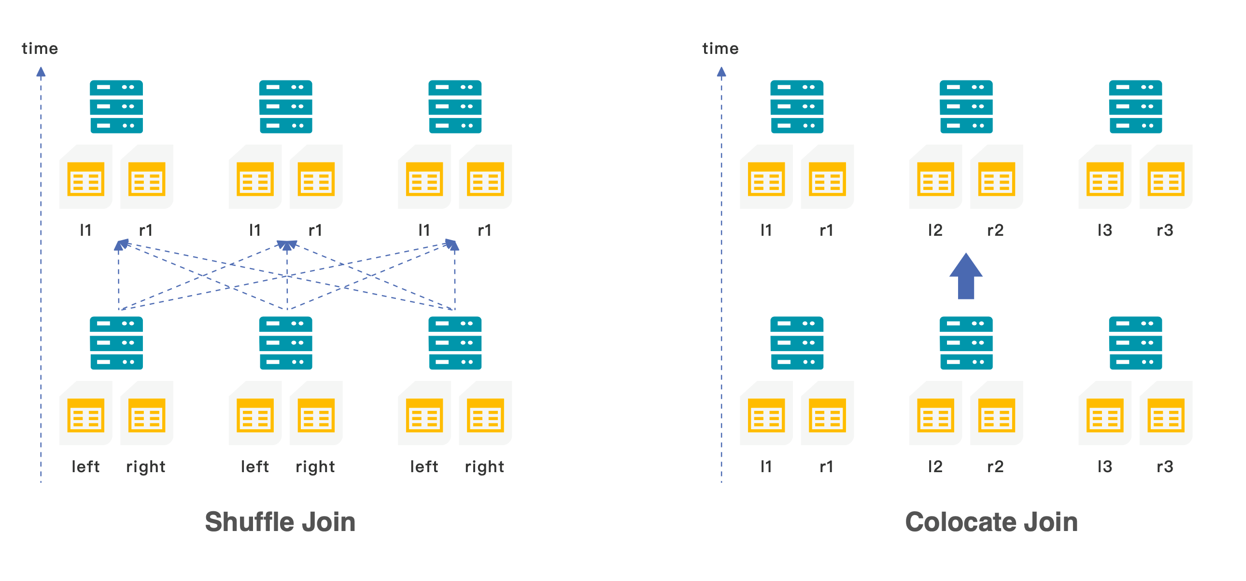
Three different types of joins are provided in StarRocks:
Boardcast join is applied to associate a small table with a large table, and the small table will be loaded into the memory of different nodes by broadcasting
When a flat table is associated with another, shuffle join can be used, and the data with the same value in the two tables will be shuffled to the same machine
In order to avoid the network and I/O overhead caused by shuffle, the data that needs to be associated can be stored in the same colocation group up creation, by using colocation join
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
At present, most of the calculation engines of MPP architecture use the rule-based optimizer (RBO). In order to better choose the type of join, StarRocks provides a cost-based optimizer (CBO). When developing business SQL, users do not need to consider the sequence of driving tables and driven tables, nor do they need to consider which type to use. CBO will automatically query and update based on the collected indicators to optimize the sequence and type of connections.
High concurrency
ClickHouse's support for high concurrency
It's necessary to introduce more analysts for data surveys from different dimensions to deeper explore the value of data. More users also bring higher QPS requirements. For industries such as the Internet and finance, ten-thousand scale of employees are common, concurrent volume to be several thousand at rush hours is also not a news. With Internet and scenarios becoming the trend, business becomes user-centric, and the focus of analysis has also changed from the original macro analysis to the fine-grained analysis of the user dimension. In the traditional MPP database, all nodes must participate in calculations, so the concurrency capability of a cluster is almost the same as that of a node. If one must increase the amount of concurrency, one can consider increasing the number of copies, but at the same time, it also increases RPC interaction, which affects the performance and physical costs.
In ClickHouse, we do not recommend high-concurrency business queries in most cases. For a three-replica cluster, QPS is usually controlled below 100. ClickHouse is not friendly to high-concurrency businesses. Even a query takes up half of the CPU. Generally speaking, there is no effective way to directly increase the concurrency of ClickHouse. One can only consider increasing the concurrency of queries by writing the result set to MySQL.
StarRocks' support for high concurrency
Compared with ClickHouse, StarRocks can support thousands of users to perform analysis and query at the same time. In some scenarios, the concurrency capacity can reach 10,000. In the data storage layer, StarRocks adopts a strategy of first partitioning, then bucketing to make data more visible. The prefix index can be used to filter and search data quickly, reduce disk I/O operations, and improve query performance.
When creating a table, partition and bucketing should cover the query statement as much as possible, so that the function of partition and bucketing can be fully leveraged, and the amount of data scanning can be reduced as much as possible. In addition, StarRocks also provides the pre-aggregation capability of the MOLAP library. For some complicated analytical queries, user can pre-aggregate by creating materialized views. The original base tables with billions of data can be transformed into tables with hundreds or thousands of rows through the pre-aggregation RollUp operation. The query latency will be significantly reduced. Concurrency will also be significantly improved.
High-frequency changes of data
Data update in ClickHouse
In OLAP databases, mutable data is usually unpopular. The same is true for ClickHouse. Earlier versions did not support UPDATE and DELETE. After version 1.15, Clickhouse provides MUTATION operations (through ALTER TABLE statements) to update and delete data, but this is a "heavier" move, which is different from the UPDATE and DELETE move in the standard SQL grammar. It is performed asynchronously, which is more useful for infrequent updates or deletions of batch data. In addition to the MUTATION , Clickhouse can also update and delete data through CollapsingMergeTree, VersionedCollapsingMergeTree, and ReplyMergeTree combined with specific business data structures. These three methods are used to insert the latest data through the INSERT statement, and the new data will be "offset" or "replaced". Old data, but "offset" or "replacement" occurs when the data file is merged in the background, that is, before the merge, the new data and the old data will exist at the same time.
For different business scenarios, ClickHouse provides different business engines to make data changes.
For offline business, you can consider two options: incremental and full:
In the incremental synchronization solution, the MergeTree engine is applied, and the upstream data is synchronized to Apache Hive™ with Apache Spark™ first, and the incremental data of Apache Hive will be consumed by Apache Spark, written to ClickHouse. Since the incremental data is synchronized, the effect on lower streams is little. But users need to ensure that the dimensional data is basically unchanged.
In the full synchronization solution, the MergeTree engine is used to synchronize upstream data to Apache Hive through Apache Spark, the tables in ClickHouse are truncated, and the data from Apache Hive in recent days consumed by Apache Spark is synchronously written to ClickHouse. Because it is a full data import, it will have an adverse effect on lower streams, but the problem of factor changes don't need to be considered.
For real-time services, two engines, VersionedCollapsingMergeTree and ReplacingMergeTree, can be used:
Using the VersionCollapsingMergeTree engine, first synchronize online data to ClickHouse through Apache Spark, and then use Apache Kafka® to consume incremental data and synchronize it to ClickHouse in real time. But because MQ is introduced, it is necessary to ensure a real-time data connection, and the existence of real-time and offline data connection points cannot reduce the overlap.
Use the ReplacingMergeTree engine to replace the VersionedCollapsingMergeTree engine, one shall synchronize the stock data to ClickHouse through Apache Spark, and synchronize the real-time data to the ReplaceMergeTree engine through MQ, which is simpler than VersionedCollapsingMergeTree, and there is no abnormality in offline and real-time data connection points. But using this plan cannot ensure to save the not-duplicated data.
Data update in StarRocks
Compared with ClickHouse, StarRocks is simpler to operate for data update.
StarRocks provides a variety of models to adapt to business requirements such as update operations, detailed recall, and aggregation. The update model can perform UPDATE/DELETE operations according to the primary key. Through storage and index optimization, it can perform efficient queries while concurrent updates. In some e-commerce scenarios, the status of orders needs to be updated frequently, and the number of orders updated every day may reach hundreds of millions. By update model, the real-time update requirements can be well adapted.
| Features | Applied Scenarios | |
| Duplicate model | It is used to save and analyze the original detailed data, with additional writing as the main method, while offers almost no update after the data is written. | Logs, operation records, equipment status sampling, time series data, etc. |
| Aggregate Model | Used to save and analyze summaries (such as max, min, sum, etc.) without querying detailed data. After the data is imported, the aggregation is completed in real time, and there is almost no update after the data is written. | Summarize data by time, region, organization, etc. |
| Primary Key Model | Supports updates based on primary keys, delete-and-insert, and guarantees high-performance queries when importing in large quantities. Used to save and analyze data that needs to be updated. | Orders whose status will change,such as equipment status, etc. |
| Unique Model | Support update based on primary key, Merge On Read, update frequency is higher than primary key model. Used to save and analyze data that needs to be updated. | Orders whose status will change,such as equipment status, etc. |
Before StarRocks version 1.19 , you can use the Unique model to update by the primary key. The Unique model uses the Merge-on-Read strategy, namely when the data is stored in the database, each batch of imported data will be assigned a number and the same primary key. The data may have multiple version numbers. When querying, StarRocks will first merge and return data with the latest version number.
Since StarRocks 1.19 version, the primary key model has been released, which can be updated and deleted through the primary key, which is supportive for real-time/frequent update needs. Compared with the Merge-on-Read mode in the Unique model, the Delete-and-Insert update is used in the primary key model, and the performance will be improved by about three times. For scenarios where the front-end TP library is synchronized to StarRocks in real time via CDC, the primary key model is recommended.
Maintenance of the cluster
Compared with a single-instance database, the maintenance cost of any distributed database will increase exponentially. On the one hand, as the number of nodes increases, the probability of failure becomes higher. For this situation, a good automatic failover mechanism is needed. On the other hand, as the amount of data grows, achieving online elastic expansion and contraction is a must, to ensure the stability and availability of the cluster.
Node expansion and redistribution in ClickHouse
Unlike general distributed databases or Apache Hadoop, HDFS can automatically adjust data balance according to the increase or decrease of cluster nodes. However, the ClickHouse cluster cannot automatically sense changes in the cluster topology, so it cannot automatically balance data. When the cluster data is large, adding cluster nodes may bring great operation and maintenance costs to data load balancing.
Generally speaking, three schemes are offered for adding cluster nodes:
If the business permits, users can set TTL for the tables in the cluster, and the data that has been retained for a long time will be gradually cleaned up, and the new data will be automatically selected for new nodes, and finally load balancing will be achieved.
Create a temporary table in the cluster, copy the data in the original table to the temporary one, and then delete the original table. When the amount of data is large, or the number of tables is too large, the maintenance cost is high,and it is not able to cope with real-time data changes.
Guide the newly written data to the new node by configuring the weight. The weight maintenance cost is relatively high.
For all the above-mentioned solutions, from the perspectives of time cost, hardware resources, real-time performance, etc., ClickHouse is not very suitable for online node expansion and data deployment. Since ClickHouse cannot automatically detect node topology changes, we may need to write a set of data redistribution logic in CMDB. Therefore, we need to estimate the amount of data and the number of nodes as early as possible.
Online elastic scaling in StarRocks
Like HDFS, when the StarRocks cluster perceives a change in the cluster topology, it can perform online elastic expansion and contraction,avoid adding nodes to the business intrusion.
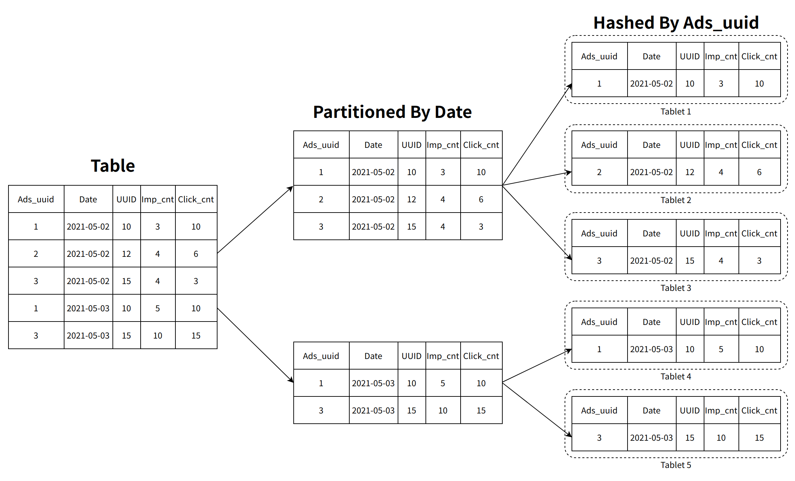
The data in StarRocks is stored by partitioning and bucketing. After the data is bucketed, a hash calculation is performed according to the bucket key, and the data with the same result is divided into the same data slice, which we call a tablet. Tablet is the smallest unit of data redundancy in StarRocks. Usually we store data in three copies by default, and the nodes are replicated through the quorum protocol. When a node goes down, the missing tablets will be automatically filled on other available nodes to achieve an imperceptible failover.
When a new node is added, FE also automatically schedule it, schedule the tablets in the existing node to the expanded node to achieve automatic data slice balancing. In order to avoid the impact on business performance during tablet migration, you can choose to expand or shrink nodes during non-rush hours as much as possible, or adjust scheduling parameters to control the speed of tablet to minimize the impact on services.
Performance comparison between ClickHouse and StarRocks
Single table SSB performance test
Due to the limited capacity of ClickHouse join, the TPCH test cannot be completed. A single table of SSB 100G is used for the test.
Test environment
| Device | Configuration: 3 Alibaba Cloud hosts |
| CPU |
64 core Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.5GHz Cache Size: 36608 KB |
| Memory | 128G |
| Network Bandwidth | 100G |
| Disk | SSD Ultra Disk |
| Version of ClickHouse | 21.9.5.16-2.x86_64 (18-Oct-2021) |
| Version of StarRocks | v1.19.2 |
Test Data
| Table | Number of Rows |
| lineorder | 600 million |
| customer | 3 million |
| part | 1.4 million |
| supplier | 0.2 million |
| dates | 2556 |
|
lineorder_flat (Flattened Table) |
600 million |
Test Results
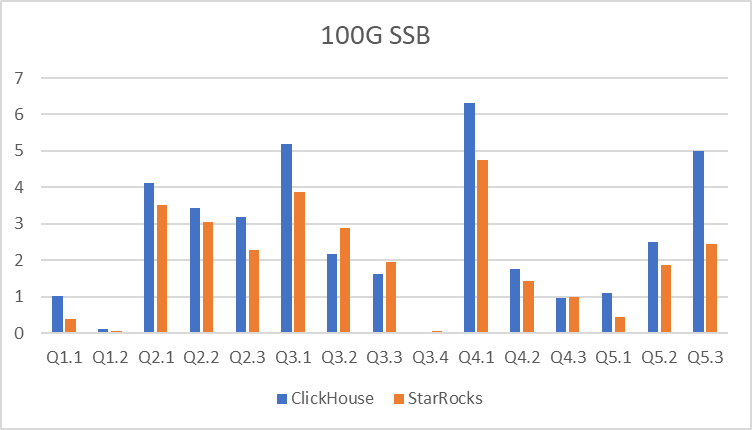
It can be seen from the test results that StarRocks outperforms ClickHouse in 9 SQL out of 14 tests.
| ClickHouse | StarRocks | |
| Q1.1 | 1.022 | 0.37 |
| Q1.2 | 0.105 | 0.05 |
| Q2.1 | 4.107 | 3.51 |
| Q2.2 | 3.421 | 3.06 |
| Q2.3 | 3.175 | 2.28 |
| Q3.1 | 5.196 | 3.86 |
| Q3.2 | 2.159 | 2.88 |
| Q3.3 | 1.61 | 1.95 |
| Q3.4 | 0.036 | 0.05 |
| Q4.1 | 6.304 | 4.75 |
| Q4.2 | 1.761 | 1.43 |
| Q4.3 | 0.969 | 0.98 |
| Q5.1 | 1.107 | 0.45 |
| Q5.2 | 2.499 | 1.86 |
| Q5.3 | 5.009 | 2.44 |
Multi-table TPCH performance test
ClickHouse is not good at multi-table association scenarios. For the TPCH test machine, many queries cannot be done, or leads to out-of-memory, currently only StarRocks' TPCH test is performed.
Test Environment
| Device | Configuration: 3 Alibaba Cloud hosts |
| CPU |
64 core Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.5GHz Cache Size: 36608 KB |
| Memory | 128G |
| Network Bandwidth | 100G |
| Disk | SSD Ultra Disk |
| Version of StarRocks | v1.19.2 |
Test Data
TPCH 100G test set.
| Table | Number of Rows |
| customer | 15000000 |
| lineitem | 600037902 |
| nation | 25 |
| orders | 150000000 |
| part | 20000000 |
| partsupp | 80000000 |
| region | 5 |
| supplier | 1000000 |
Test Results
| StarRocks | |
| Q1 | 0.691s |
| Q2 | 0.290s |
| Q3 | 1.445s |
| Q4 | 0.611s |
| Q5 | 1.361s |
| Q6 | 0.172s |
| Q7 | 2.777s |
| Q8 | 1.81s |
| Q9 | 3.470s |
| Q10 | 1.472s |
| Q11 | 0.241s |
| Q12 | 0.613s |
| Q13 | 2.102s |
| Q14 | 0.298s |
| Q16 | 0.468s |
| Q17 | 7.441s |
| Q18 | 2.479s |
| Q19 | 0.281s |
| Q20 | 2.422s |
| Q21 | 2.402s |
| Q22 | 1.110s |
Import performance test
Whether it is ClickHouse or StarRocks, we both use DataX to import full data, and the incremental part can be written into MQ through the CDC tool and then consumed by the downstream database.
Data set
For the test, ClickHouse Native Format was selected. One xz format compressed file is about 85GB, the original file after decompression is 1.4T, 31 pieces of data. The format is CSV.
Import method
The appearance of HDFS used in ClickHouse. The distributed table in ClickHouse can only choose one integer column as the Sharding Key. Observing the data, it is found that the cardinality is very low, so the rand() distribution form is used.
CREATE TABLE github_events_all AS github_events_local \
ENGINE = Distributed( \
perftest_3shards_1replicas, \
github, \
github_events_local, \
rand());
The external table of HDFS is defined as follows
CREATE TABLE github_events_hdfs
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4,
'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8,
'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11,
'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15,
'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19,
'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9,
'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
body String,
path String,
position Int32,
line Int32,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
locked UInt8,
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
comments UInt32,
author_association Enum('NONE' = 0, 'CONTRIBUTOR' = 1, 'OWNER' = 2, 'COLLABORATOR' = 3, 'MEMBER' = 4, 'MANNEQUIN' = 5),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
requested_teams Array(LowCardinality(String)),
head_ref LowCardinality(String),
head_sha String,
base_ref LowCardinality(String),
base_sha String,
merged UInt8,
mergeable UInt8,
rebaseable UInt8,
mergeable_state Enum('unknown' = 0, 'dirty' = 1, 'clean' = 2, 'unstable' = 3, 'draft' = 4),
merged_by LowCardinality(String),
review_comments UInt32,
maintainer_can_modify UInt8,
commits UInt32,
additions UInt32,
deletions UInt32,
changed_files UInt32,
diff_hunk String,
original_position UInt32,
commit_id String,
original_commit_id String,
push_size UInt32,
push_distinct_size UInt32,
member_login LowCardinality(String),
release_tag_name String,
release_name String,
review_state Enum('none' = 0, 'approved' = 1, 'changes_requested' = 2, 'commented' = 3, 'dismissed' = 4, 'pending' = 5)
)
ENGINE = HDFS('hdfs://XXXXXXXXXX:9000/user/stephen/data/github-02/*', 'TSV')
In StarRocks, the Broker Load mode is adopted for import, the command is as follows:
LOAD LABEL github.xxzddszxxzz (
DATA INFILE("hdfs://XXXXXXXXXX:9000/user/stephen/data/github/*")
INTO TABLE `github_events`
(event_type,repo_name,created_at,file_time,actor_login,updated_at,action,comment_id,body,path,position,line,ref,ref_type,creator_user_login,number,title,labels,state,locked,assignee,assignees,comments,author_association,closed_at,merged_at,merge_commit_sha,requested_reviewers,requested_teams,head_ref,head_sha,base_ref,base_sha,merged,mergeable,rebaseable,mergeable_state,merged_by,review_comments,maintainer_can_modify,commits,additions,deletions,changed_files,diff_hunk,original_position,commit_id,original_commit_id,push_size,push_distinct_size,member_login,release_tag_name,release_name,review_state)
)
WITH BROKER oss_broker1 ("username"="user", "password"="password")
PROPERTIES
(
"max_filter_ratio" = "0.1"
);
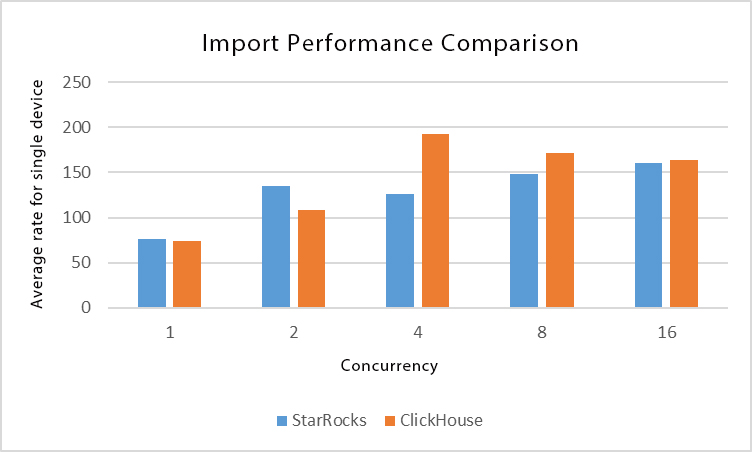
Results
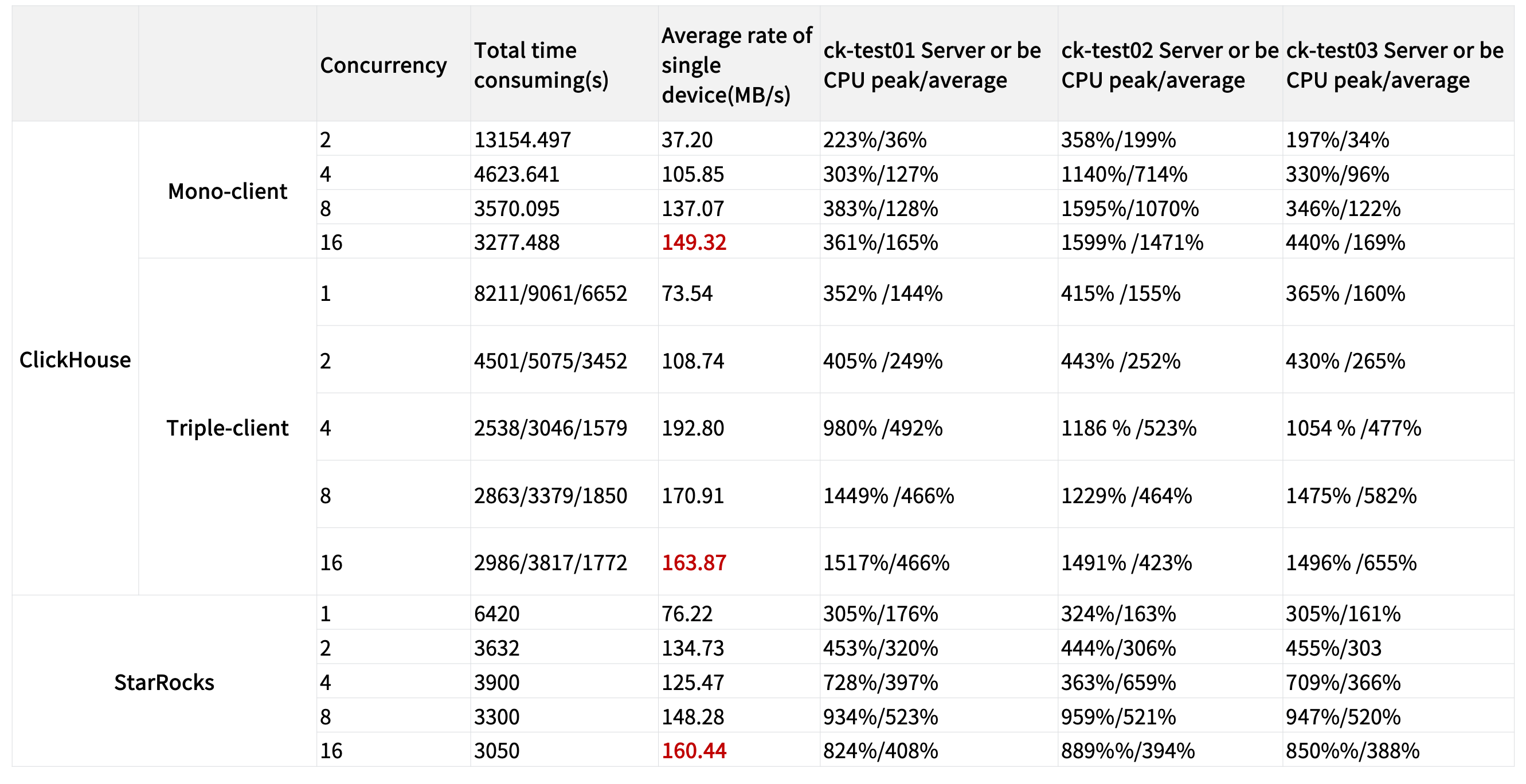
It can be seen that when using the github data set for import, the performance of StarRocks and ClickHouse import is basically the same
Conclusion
ClickHouse and StarRocks are both outstanding OLAP databases. The two have many similarities, and both provide extreme performance for analytical queries and do not rely on the Apache Hadoop ecosystem. From this comparison, it can be seen that in certain scenarios, StarRocks has better performance than ClickHouse. ClickHouse is suitable for the scene of flat table with less dimensional changes. StarRocks not only has a better performance in the single table test, but also has a greater advantage in multi-table associations.
This article is an excerpt from DZone. For the full article, visit https://dzone.com/articles/clickhouse-or-starrocks-detailed-comparison.
Apache®, Apache Spark™,Apache Flink®,Apache Kafka®,Apache Hadoop®,Apache Hive™,Apache ZooKeeper™ and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
