In recent years, an increasing number of enterprises began to use data to power decision-making, which yields new demands for data exploration and analytics. As database technologies evolve with each passing day, a variety of online analytical processing (OLAP) engines keep popping up. These OLAP engines have distinctive advantages and are designed to suit varied needs with different tradeoffs, such as data volume, performance, or flexibility.
This article compares two popular open-source engines, Apache Druid®, and StarRocks, in several aspects that may interest you the most, including data storage, pre-aggregation, computing network, ease of use, and ease of O&M. It also provides star schema benchmark (SSB) test results to help you understand which scenario favors which more.
Introduction to Apache Druid® and StarRocks
What Is Apache Druid ?
Apache Druid® is an OLAP data storage and analytics system designed for the high-performance processing of massive datasets. It is developed by the ad analytics company Metamarkets. Apache Druid offers low-latency data ingestion, flexible data exploration and analysis, high-performance aggregation, and easy horizontal scaling. It can process data at a high scale and provisions pre-aggregation capabilities. Apache Druid® uses inverted indexes and bitmap indexes to optimize query performance. It has broad use cases in time-series applications such as ad analysis and monitoring and alerting.
Competitive edges of Apache Druid:
- Columnar storage, distributed shared-nothing architecture
- Support for real-time and batch ingestion, immediate query upon ingestion
- Self-healing, self-balancing
- Data stored in deep storage, no data loss
- Pre-aggregation, time-based partitioning, fast filtering based on roaring and concise bitmap indexes
- Support for approximation algorithms
What Is StarRocks?
StarRocks is a new-generation, blazing-fast massively parallel processing (MPP) database designed for all analytics scenarios. It is oriented for multi-dimensional analysis, real-time analysis, and ad hoc queries. StarRocks is highly performant in high-concurrency, low-latency point queries, and high-throughput ad hoc queries. Its unified batch and real-time data ingestion feature make pre-aggregation possible. StarRocks supports various schemas, such as flat, star, and snowflake schemas. It is well suited for various scenarios that have demanding requirements for performance, real-time analytics, high concurrency, and flexibility.
Competitive edges of StarRocks:
- Columnar storage, vectorized SQL engine
- Simple, HA architecture, easy O&M
- Support for standard SQL, compatible with MySQL protocol
- Intelligent query optimization based on cost-based optimizer (CBO)
- Real-time data ingestion and update
- Modern materialized views, accelerated aggregation and query
- Query federation, joint analysis of heterogeneous data sources
Function Comparison
Apache Druid® and StarRocks are positioned as big data analytics engines. They have a lot in common. They both use columnar storage, support ingestion of huge volume of data, high concurrency, distinct count using approximate algorithms, HA deployment, and data self-balancing. However, the two have key differences in data storage, pre-aggregation, computing framework, ease of use, and ease of O&M.
Data Storage
Data ingested into Apache Druid is split into segments before they are stored in deep storage. After data is generated, you can only append data to a segment or overwrite/delete the entire segment. You do not have the flexibility to modify partial data in a segment. Druid partitions data by time or sometimes performs secondary partitioning on specific columns to improve locality, which reduces data access time. In addition, Druid allows you to specify sorting dimensions to improve compression and query performance.
StarRocks uses the partitioning and bucketing mechanism to distribute data. You have the flexibility to specify partition and bucket keys based on the characteristics of data and queries. This helps reduce the volume of data to scan and maximizes the parallel processing capabilities of clusters. StarRocks sorts table data based on the specified columns when it organizes and stores data. You can place columns that are distinctive and frequently queried before other columns to speed up data search. StarRocks' bucketing mechanism is similar to Apache Druid's secondary partitioning mechanism.
In general, StarRocks and Apache Druid have similar storage mechanisms. However, Druid supports only time-based partitioning, whereas data in the first-level partitions of StarRocks can be of various data types (DATE, DATETIME, and INT). In this sense, StarRocks is more flexible than Apache Druid.
In terms of data updates, Apache Druid allows you to delete and update data only by time range. Point deletion and update are not supported. This limitation is more inconvenient when dimensions or data change frequently. StarRocks supports the analysis of detailed data and aggregated data, and real-time data updates. You can use the update model and primary key model provided by StarRocks to implement UPDATE and DELETE operations based on primary keys.
| Scenario | Scenario description | Apache Druid | StarRocks |
| Analysis of detailed data | Stores and analyzes raw detailed data, with appending as the main writing method and almost no data update after data is written | Support | Support |
| Analysis of aggregated data | Stores and analyzes aggregated data, no need to query detailed data, real-time aggregation after data importing, almost no data update after data is written | Support | Support |
| Data update | Stores and analyzes data that needs to be updated | Not supported | Support |
Pre-Aggregation
Apache Druid uses the pre-aggregation model. When data is ingested, the rollup feature combines rows with the same dimension and timestamp values into one row, significantly reducing data volume and speeding up queries. However, after data is aggregated, detailed data is no longer available for query. To query data on Apache Druid, you must specify time columns to scan pre-aggregated segments within these time ranges. Apache Druid®further aggregates the results to generate the final data. However, raw data cannot be retained when rollup is used to rewrite queries. If a large number of dimensions need to be aggregated at small-time granularities, a huge amount of system resources will be occupied by secondary aggregation.
StarRocks uses intelligent materialized views to pre-aggregate data during ingestion. It automatically picks an optimal materialized view for queries. When data in the original table changes, the materialized view is updated accordingly. If you do not need to query raw data, you can use the aggregate key model of StarRocks to store aggregated data, similar to using the pre-aggregation model of Apache Druid.
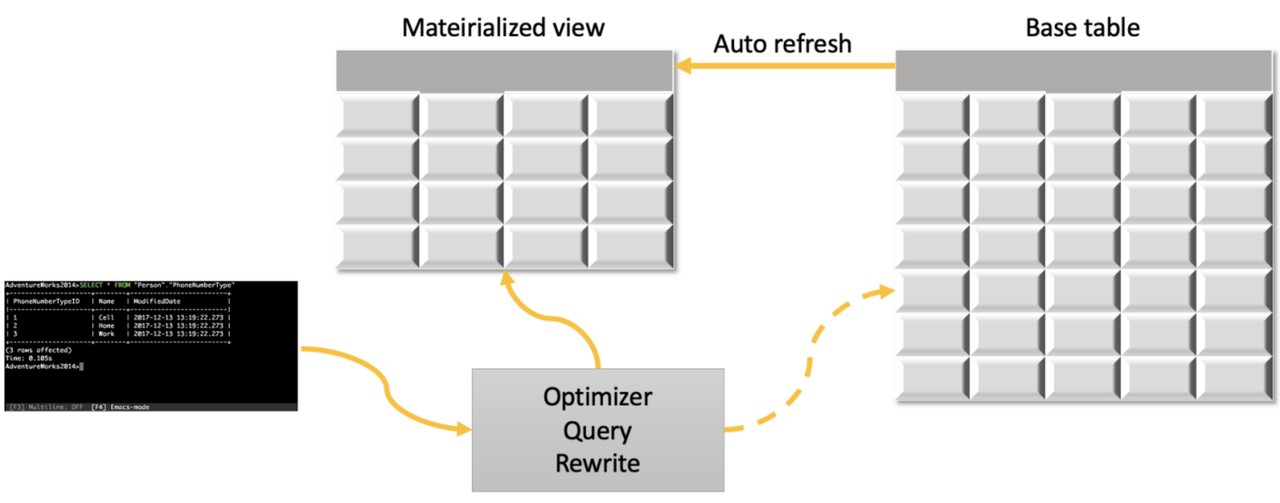
Computing Framework
Vectorized execution accelerates queries by processing multiple sets of data in parallel.
Apache Druid is still optimizing its vectorization technology and its engine has not been fully vectorized. Only groupBy and Timeseries queries can be executed in a vectorized fashion, but with some restrictions. Other queries, such as TopN, Scan, Select, and Search, do not support vectorized execution. Apache Druid uses the scatter-gather approach to run queries. This computing framework is simple but is not suitable for complex queries such as large-table joins and nested queries. In addition, the Gather node has performance bottlenecks. When a large amount of data is generated after groupBy, the Gather node is prone to memory bloat, which undermines cluster stability.
StarRocks offers a fully vectorized engine for data loading and query. StarRocks adopts the MPP architecture. Unlike the scatter-gather approach which transparently distributes queries to backends, StarRocks first converts queries into an internal execution plan, splits the execution plan into multiple tasks, and distributes the tasks to multiple BE nodes for parallel processing. Data can be redistributed among these tasks to run complex queries such as large-table joins and nested queries. For queries such as groupBy, data is distributed to multiple nodes for execution, which prevents a single-point performance bottleneck. For SQL optimization, StarRocks CBO automatically collects row counts, column cardinality, and min/max values, and automatically tunes the join order. You no longer need to consider SQL execution efficiency when writing SQL statements. However, storage and compute are not separated in StarRocks. It will be an upcoming feature by mid-2022.
Ease of Use
SQL is a mainstream query language used for data analytics. Good support for SQL not only lowers the threshold for using data analytics systems, but also facilitates the migration of existing analytics programs. Compatibility with existing data analytics systems is also a major gauge of ease of use.
Apache Druid supports two query languages: Apache Druid SQL and native queries. Apache Druid does not fully support standard SQL. For join operations, Apache Druid supports two types of joins: join operators and lookups. Lookups can only be used for simple key-value mapping. The lookup tables need to be pre-loaded on all machines in advance and they are only suitable for dimension tables with a small amount of data. Join operators currently can only be used for broadcast hash joins. Tables except the leftmost table must be able to be loaded into the memory, and only equivalent joins can be performed. Apache Druid is not compatible with mainstream MySQL-compliant clients.
StarRocks supports standard SQL, including join, sorting, aggregate, window, and custom functions, and exact distinct count. StarRocks supports 22 TPC-H SQL and 99 TPC-DS SQL. It is also compatible with the MySQL protocol. You can access StarRocks by using various clients and BI software.
Ease of O&M
Both Apache Druid and StarRocks support elastic data distribution, online scaling, and HA deployment. However, the two differ greatly in the complexity of deployment and O&M.
Apache Druid uses six types of processes (Overlord, Coordinator, MiddleManager, Router, Broker, and Historical). In addition, Apache Druid relies on MySQL for storing metadata, Apache ZooKeeper™ for electing Coordinator and Overlord processes, and deep storage for storing data. If you want to use HA deployment, you may need to manage many processes. The operations related to anomaly detection and rolling updates are also complex.
StarRocks has two types of nodes: front end (FE) and back end (BE). FE is responsible for metadata and scheduling management. BE is responsible for data storage and calculation. FE and BE nodes can be horizontally scaled. StarRocks does not rely on other third-party components. It is also compatible with the MySQL protocol. You can use a variety of MySQL clients to perform O&M operations on StarRocks.
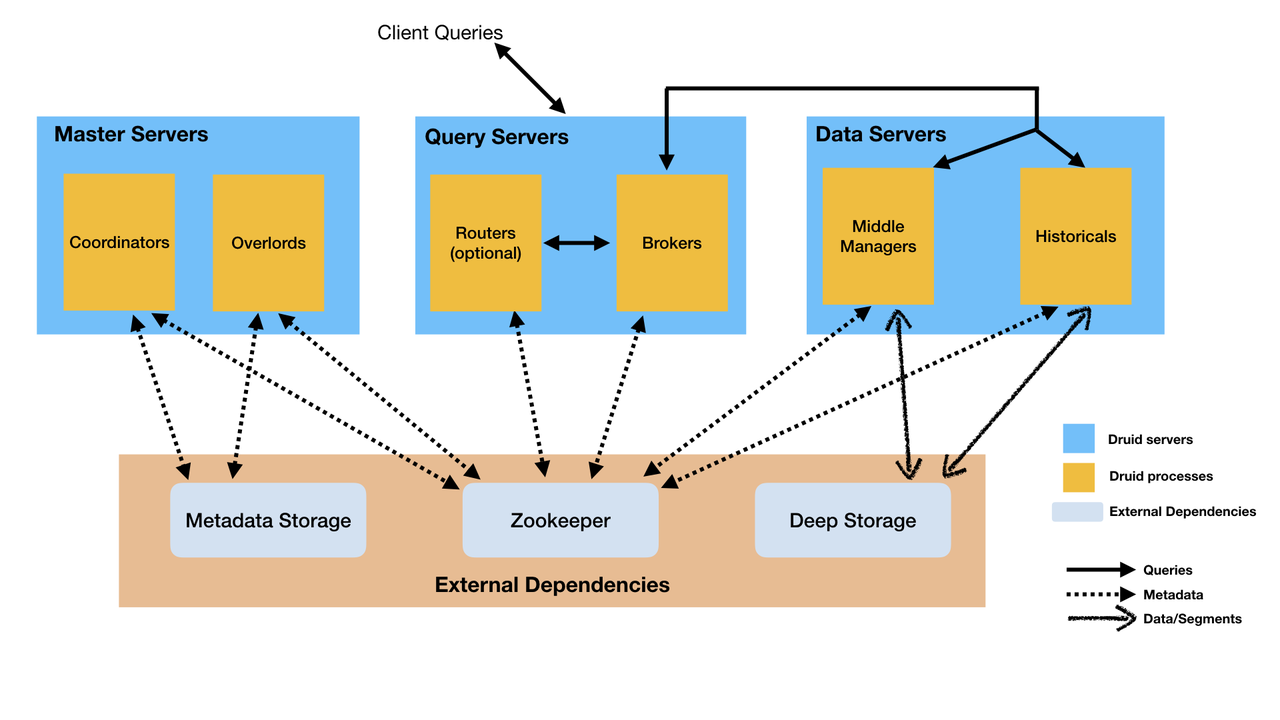
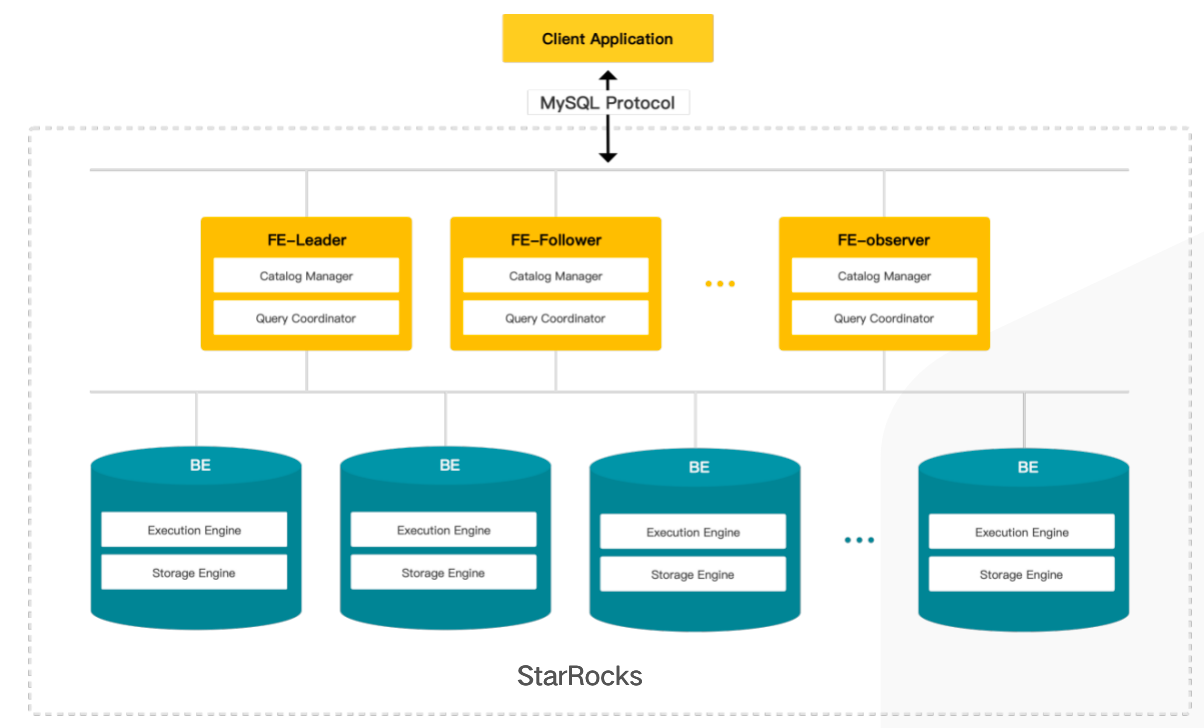
Performance Testing
Test Method
Star schema benchmark (SSB) is used to evaluate the performance of a data warehouse that uses the star schema. It is developed based on TPC-H and has been widely applied since 2007. SSB testing generates test data and 13 SQL queries.
This test uses an SSB 100 GB dataset for SSB equivalent standard testing. It mainly tests the on-site single-table and multi-table query performance of Apache Druid and StarRocks. Therefore, the result cache is disabled for each system.
Test Environment
| Machine |
1 header node ecs.g6.2xlarge |
3 worker nodes ecs.g6.4xlarge |
| CPU | 8 core | 16 core |
| Memory | 32 GB | 64 GB |
| Disk |
Data disk: one ESSD 80 GB System disk: one ESSD 120 GB |
Data disk: four ESSD 150 GB System disk: one ESSD 120 GB |
Software Environment
The following table describes the deployment architecture.
| Node type | StarRocks | Apache Druid |
| emr-header-1 | FE | Broker, Coordinator, Overlord, Router |
| emr-worker-1 | BE | Historical, MiddleManager |
| emr-worker-2 | BE | Historical, MiddleManager |
| emr-worker-3 | BE | Historical, MiddleManager |
Test Data
| Table name | Number of rows | Description |
| lineorder | 600 million | Lineorder fact table |
| customer | 3 million | Customer dimension table |
| part | 1.4 million | Part dimension table |
| supplier | 200,000 | Supplier dimension table |
| dates | 2,556 | Date dimension table |
| lineorder_flat | 600 million | lineorder flat table |
Test Results
Single-Table Query
| Query | StarRocks query latency (ms) | Apache Druid query latency (ms) | Improvement (times) (StarRocks over Apache Druid) |
| Q1.1 | 40 | 650 | 16 |
| Q1.2 | 13 | 260 | 20 |
| Q1.3 | 33 | 810 | 25 |
| Q2.1 | 127 | 290 | 2 |
| Q2.2 | 53 | 340 | 6 |
| Q2.3 | 37 | 130 | 4 |
| Q3.1 | 356 | 370 | 1 |
| Q3.2 | 113 | 190 | 2 |
| Q3.3 | 30 | 120 | 4 |
| Q3.4 | 20 | 60 | 3 |
| Q4.1 | 453 | 510 | 1 |
| Q4.2 | 73 | 190 | 3 |
| Q4.3 | 40 | 210 | 5 |
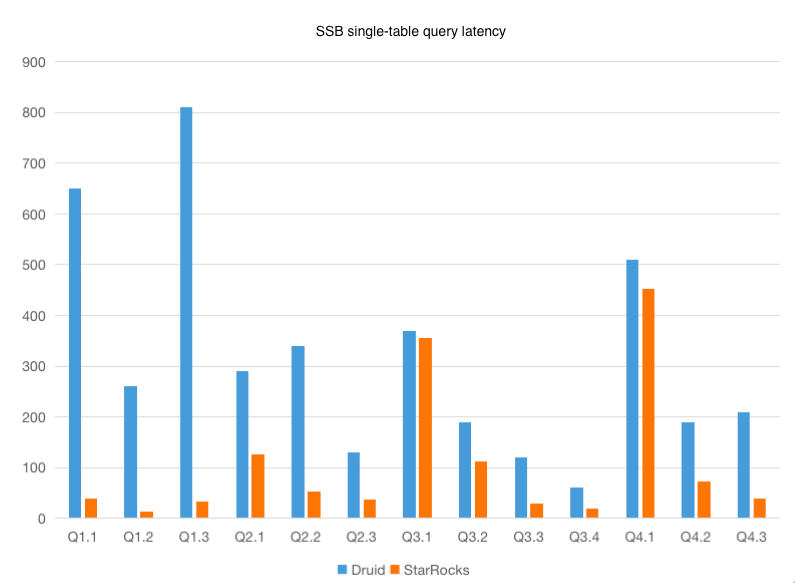
The test results show that StarRocks has better performance in the SSB 100 GB single-table test. Among the 11 queries, StarRocks outperforms Apache Druid by a large margin in 9 queries.
Multi-Table Query
Currently, Apache Druid uses lookup and join to implement multi-table association. Apache Druid®join supports only broadcast hash joins and tables except the leftmost table must be able to be stored in memory. It has some limitations but lacks optimizations. This test uses Apache Druid lookups that have relatively good performance for the multi-table association. In actual implementation, lookup functions outperform lookup table joins. Therefore, this test uses lookup functions for the multi-table association.
| Query | StarRocks query latency (ms) | Apache Druid query latency (ms) | Improvement (times) (StarRocks over Apache Druid) |
| Q1.1 | 183 | 277 | 2 |
| Q1.2 | 117 | 316 | 3 |
| Q1.3 | 93 | 217 | 2 |
| Q2.1 | 370 | 6112 | 17 |
| Q2.2 | 257 | 11045 | 43 |
| Q2.3 | 230 | 5704 | 25 |
| Q3.1 | 690 | 5489 | 8 |
| Q3.2 | 307 | 4561 | 15 |
| Q3.3 | 280 | 3619 | 13 |
| Q3.4 | 237 | 485 | 2 |
| Q4.1 | 997 | 6748 | 7 |
| Q4.2 | 1080 | 2404 | 2 |
| Q4.3 | 1013 | 2388 | 2 |
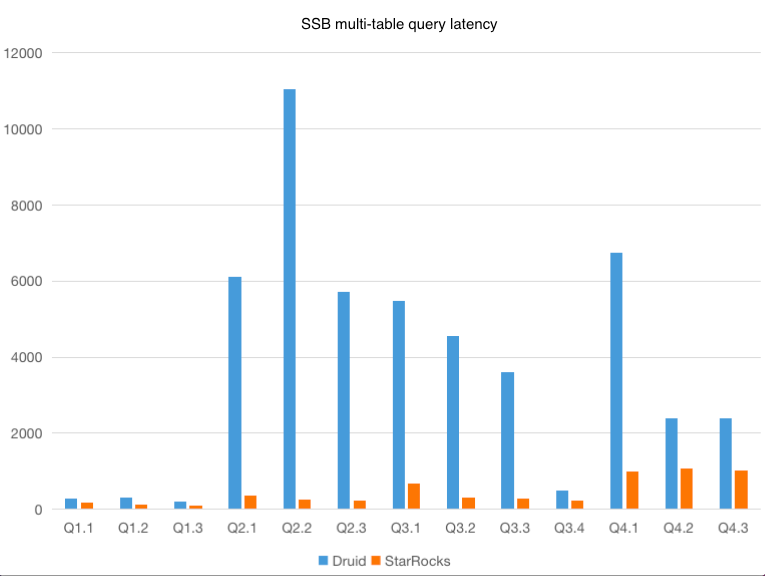
The test results show that StarRocks has better performance in multi-table association. Apache Druid® lookup pre-loads table data to the memory of each node. It has advantages in scenarios where dimension tables contain only a moderate volume of data and frequent shuffling operations are not required. However, Apache Druid® lookup can only be used for simple key-value mapping.
Conclusion
Apache Druid and StarRocks are two excellent OLAP engines with distinctive characteristics. They are all positioned for data analytics. Apache Druid uses a pre-aggregation model to pre-aggregate data at ingestion time based on dimension combinations, which accelerates follow-up calculation. However, detailed data cannot be queried. ETL operations must be performed before data is ingested. Apache Druid is more suitable for reports with fixed dimensions. StarRocks supports pre-aggregation, uses a fast vectorized execution engine to perform flat, star, and snowflake modeling. It offers fast query speed and uses various data models to power scenarios that have frequent dimension changes and data updates.
This article is an excerpt from DZone. For the full article, visit https://dzone.com/articles/apache-druid-vs-starrocks-a-deep-dive.
Apache®, Apache Druid®, Apache ZooKeeper™, and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
