StarRocks version 3.0 embarked on a groundbreaking journey by officially embracing the Decoupled Storage and Computing Architecture and redefined how data lakes are analyzed.
Today StarRocks Version 3.1 emerges as a refined iteration. Within the separated storage and compute architecture, StarRocks has supplemented numerous functionalities present in the unified storage-compute paradigm. Notably, it now supports the primary key table model and its related functionalities, ensuring real-time analysis thrives within this separation architecture.
In the data lake landscape, StarRocks deepens its Iceberg integration with enhanced read-write capabilities and Trino syntax compatibility. Asynchronous materialized view updates—including versatile parameters for the creation and refresh of views and intelligent SQL rewriting for diverse scenarios, mean that you can easily build external materialized views to accelerate data lake queries transparently.
Moreover, StarRocks introduces new features and patterns such as random bucketing, expression-based partitioning, and the FILES table function, simplifying table creation, partitioning, and import operations. The continuous advancements in functionality, performance, and user-friendliness have propelled StarRocks to new heights.
Core Features and Enhancements
Improved Data Lake Analytics
StarRocks Version 3.1 brings significant improvements and enhancements to the Iceberg Catalog, elevating its capabilities and performance.
-
Improved Query Capability: Version 3.1 introduces support for accessing Iceberg v2 Merge-on-Read (MOR) tables in Parquet format, expanding query capabilities and compatibility.
-
Enhanced Query Performance: To optimize query speeds for metadata files, a two-tiered cache system combining memory and disk caching has been introduced. This enhancement significantly boosts query performance, especially for scenarios with large metadata files.
-
Enriched Write Capability: New support enables users to create databases and tables within Iceberg and seamlessly write Parquet format data using INSERT INTO/OVERWRITE. This facilitates the smooth transfer of data processed by StarRocks to other ecosystem components through open formats.
-
Enhanced S3 signing support, allowing smooth collaboration with self-managed and Tabular-managed buckets. Enjoy the flexibility in your data management workflows. Check out the example here: (https://github.com/StarRocks/starrocks/discussions/23616).
Furthermore, Version 3.1 introduces support for additional catalogs: Elasticsearch catalog and Paimon catalog.
One more thing, Trino syntax compatibility has been further enhanced, by setting sql_dialect="trino"; you can work seamlessly with StarRocks using Trino SQL and access a broader ecosystem while continuing to prioritize user-friendliness.
Shared-data architecture
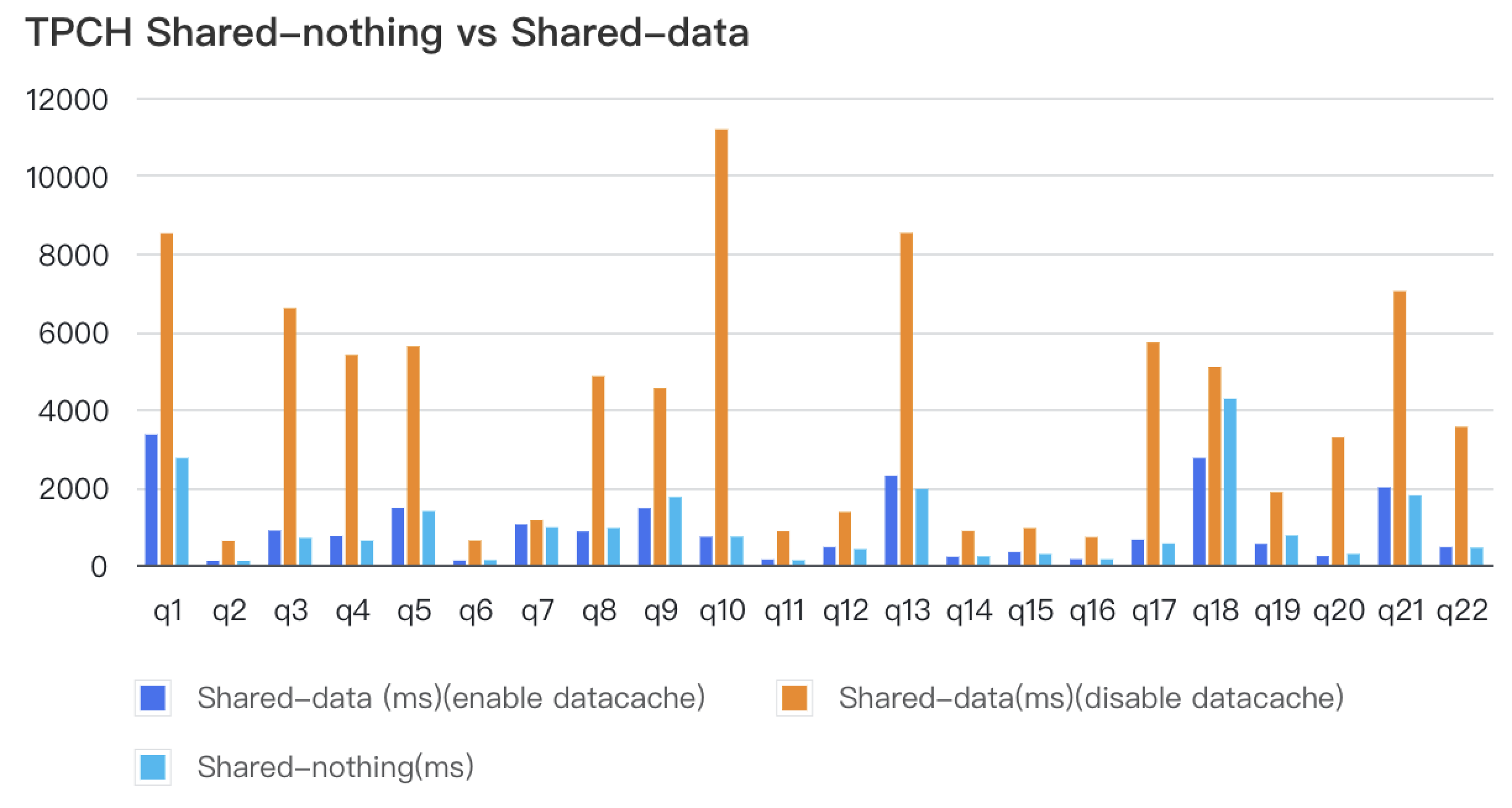
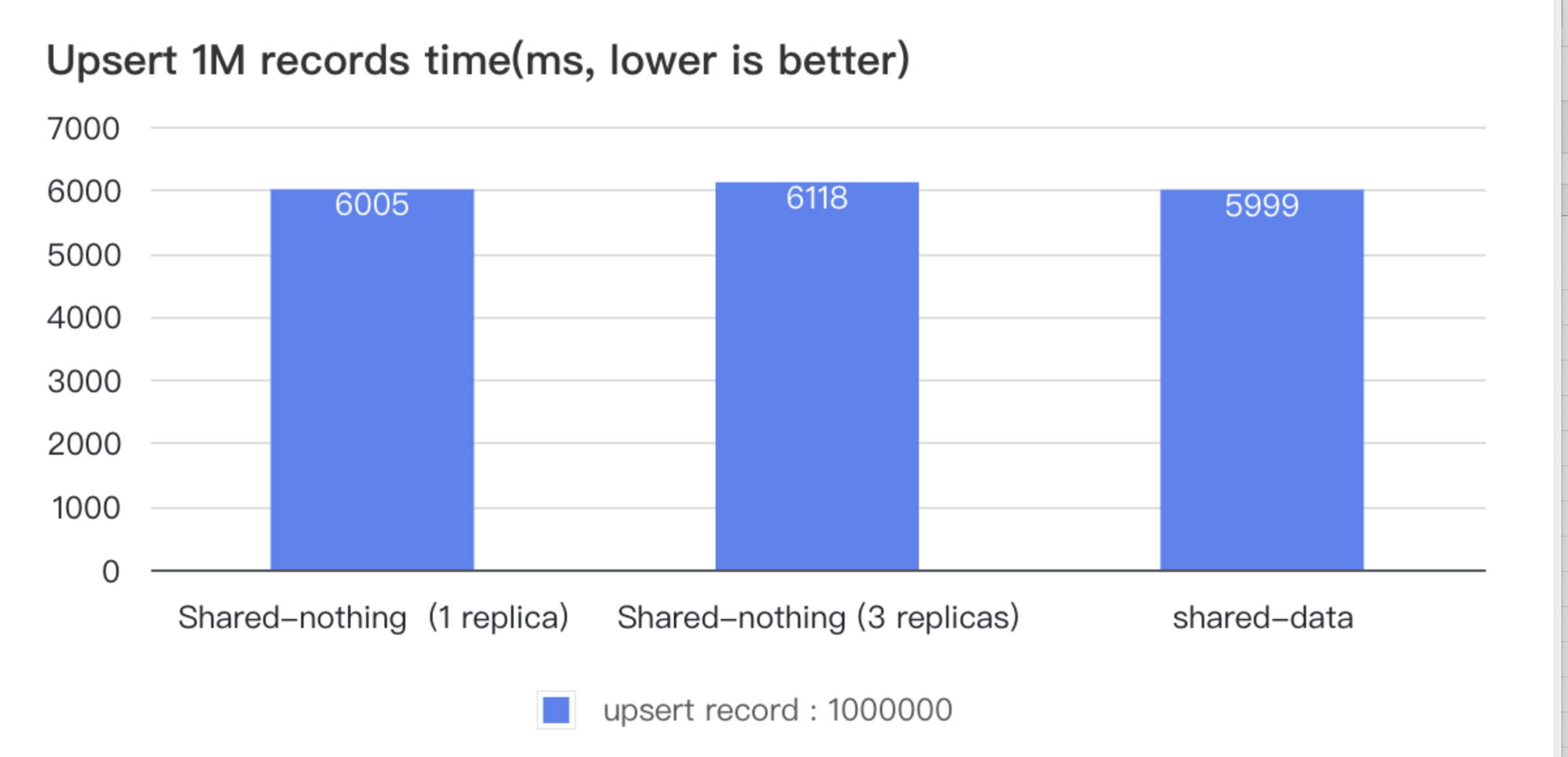
In Version 3.1, StarRocks takes further strides in enhancing the functionality within the Unified Storage-Compute Architecture. This includes introducing support for Primary Key Model tables (with partial column update support), AUTO_INCREMENT attributes, expression-based partitioning, and automatic partition creation during data imports. Additionally, data caching capabilities have been optimized, allowing users to specify the cache scope for hot data; preventing cold data from occupying the cache excessively and impacting query speeds for hot data. With Data cache enabled, the query performance of the separated storage and compute architecture now closely rivals that of the unified architecture, offering significant storage cost reductions without sacrificing query speed.
Moreover, Version 3.1 introduces support for Storage Volume abstraction, making it convenient to configure storage locations and access authorization within the separated storage and compute architecture. Users can easily specify different cloud storage systems, buckets, and storage locations for various import tasks, enhancing ease of use and bolstering data security.
Improved Ease of Use
-
Table Creation Made Easier: Building tables has become more user-friendly in Version 3.1. Users can now configure Random Bucketing (default setting) during table creation, eliminating the need to set bucketing keys. StarRocks automatically distributes imported data across buckets randomly. Moreover, with the auto-setting bucket number feature introduced in Version 2.5.7 (default setting), users no longer need to worry about bucket configurations. List partitioning enhances StarRocks versatility in handling diverse data organization needs with improved query performance and data management efficiency.
-
Simplified Data Import: For data imported from Parquet/ORC format files stored on AWS S3/HDFS, users can effortlessly use INSERT with the FILES() table function to import data. The FILES table function automatically infers the table schema, enabling immediate SELECT queries on the data. For even greater convenience, users can opt for one-click data import using CTAS + FILES.
-
Simplified Deployment: Deploying StarRocks is now more accessible with enhanced Kubernetes Operator and Helm chart support. Refer to the documentation at https://docs.starrocks.io/docs/deployment/sr_operator/ and https://docs.starrocks.io/docs/deployment/helm/ for easy deployment guidance.
StarRocks Version 3.1 prioritizes ease of use—making table creation, data import, and deployment processes smoother and more user-friendly. With these improvements, users can focus on extracting valuable insights from their data without unnecessary complexities.
Enhanced query performance
Materialized view
Since the introduction of asynchronous materialized views in Version 2.4, this feature has found extensive use in query acceleration and data warehousing scenarios. In Version 3.1, significant optimization efforts have been made in MV management, intelligent query rewriting, and usability of asynchronous materialized views.
-
MV creation improvement:
-
Support for specifying sorting keys through ORDER BY and setting colocate_group is introduced. This leverages StarRocks' native storage optimizations, further enhancing the query performance of materialized views.
-
Configurable storage medium and cooldown time (storage_medium, cooldown_time) are supported, facilitating data lifecycle management.
-
Default random bucketing is enabled when no bucket is specified, simplifying materialized view creation.
-
-
Enhance flexibility of MV:
-
Configuration of session variables for materialized view refresh is supported. This allows users to configure separate execution strategies for materialized views, including query timeout, parallelism, memory limits, and operator spilling—free from cluster-wide variable limitations.
-
Materialized views can be created based on views (View), enhancing flexibility in layered modeling.
-
SWAP-based atomic replacement of materialized views is supported, enabling schema changes without affecting nested lineage relationships.
-
Manual activation of invalidated materialized views allows for reusing historical materialized views after base table reconstruction.
-
-
Better query rewrite support for MV:
-
Added support for Join-derived rewriting, Count Distinct, time_slice function, and enhanced Union rewriting capabilities.
-
Introduced support for Stale Rewrite(check mv_rewrite_staleness_second in reference), allowing rewriting on yet-to-be-refreshed materialized views within a specified timeframe. This enhances query concurrency in real-time scenarios allowing certain data latency.
-
Introduced support for View Delta Join, enhancing rewriting capabilities for scenarios like metric platforms and subject-oriented wide tables, reducing materialized view maintenance costs.
-
-
In terms of refresh capabilities, Version 3.1 introduces:
-
A brand-new interface for synchronous materialized view refresh that provides refresh results synchronously.
-
Asynchronous materialized views based on Hive Catalog can detect partition changes and refresh incrementally by partition, accelerating refresh while reducing costs.
-
-
Synchronous materialized views improvement
-
Synchronous materialized views are favored for their synchronous update and incremental calculation capabilities. In previous versions, the limited supported operators constrained its use. Version 3.1 expands the boundaries of synchronous materialized view capabilities. In terms of computation, not only are all aggregation functions supported, but expressions like CASE-WHEN, CAST, and mathematical operations are also supported. Multiple aggregate columns within a single materialized view are also supported.
-
Using HINT for direct queries on synchronous materialized views is now possible.
-
Generated column
Version 3.1 introduces the Generated Column feature, offering automatic expression calculation during import and storage based on defined expressions. This feature enhances query performance by optimizing expression evaluation and rewriting during queries. This is particularly beneficial for accelerating queries involving semi-structured data like JSON, Array, Map, Struct, and complex expressions. Moreover, if the generated column has a simple data type, it can leverage indexes like ZoneMap to further boost query performance.
As illustrated below, "newcol1" and "newcol2" are generated columns resulting from function operations on the "data_array" and "data_json" columns, respectively:
CREATE TABLE t (
id INT NOT NULL,
data_array ARRAY < int > NOT NULL,
data_json JSON NOT NULL,
newcol1 DOUBLE AS array_avg(data_array),
newcol2 STRING AS get_json_string(json_string(data_json), '$.a')
);
Furthermore, StarRocks has optimized partial column updates for the primary key model. When executing an UPDATE statement, a column mode is initiated, significantly enhancing performance in scenarios involving updates to a few columns but numerous rows. In the former "row mode," partial column updates required rewriting the entire row of data. The new "column mode" only necessitates rewriting the updated column data, improving efficiency by up to tenfold. This optimization also extends its benefits to generated columns.
Table pruning for view
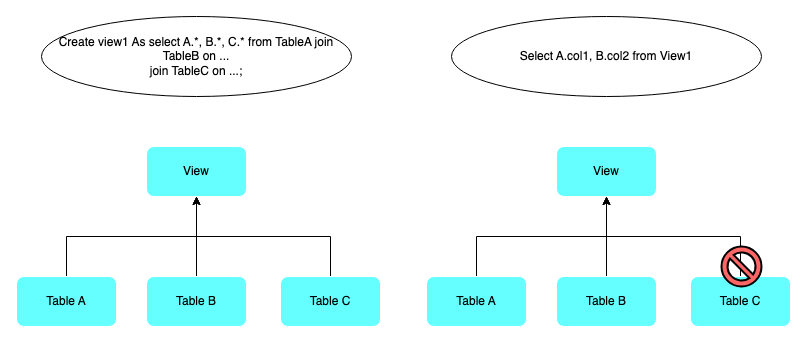
Join operations are commonly used in relational databases to combine data from multiple tables based on a common column or set of columns. However, executing joins can be computationally expensive, especially when dealing with large datasets. It's a common case that people use a large complicated view or CTE to build a simple view for end users, but end users often use some columns that only exist in a few tables.
Cardinality-preserving join pruning is a feature aimed at improving query performance by eliminating unnecessary join operations without compromising the accuracy of the result. It leverages the cardinality of the join key and the constraints of the table (including foreign key/Primary key/Unique key) to determine whether a particular join can be safely removed from the query execution plan. You can also add a hint to tell which join can be pruned. Here is a join pruning example:
Other highlights
Spilling to disk improvement
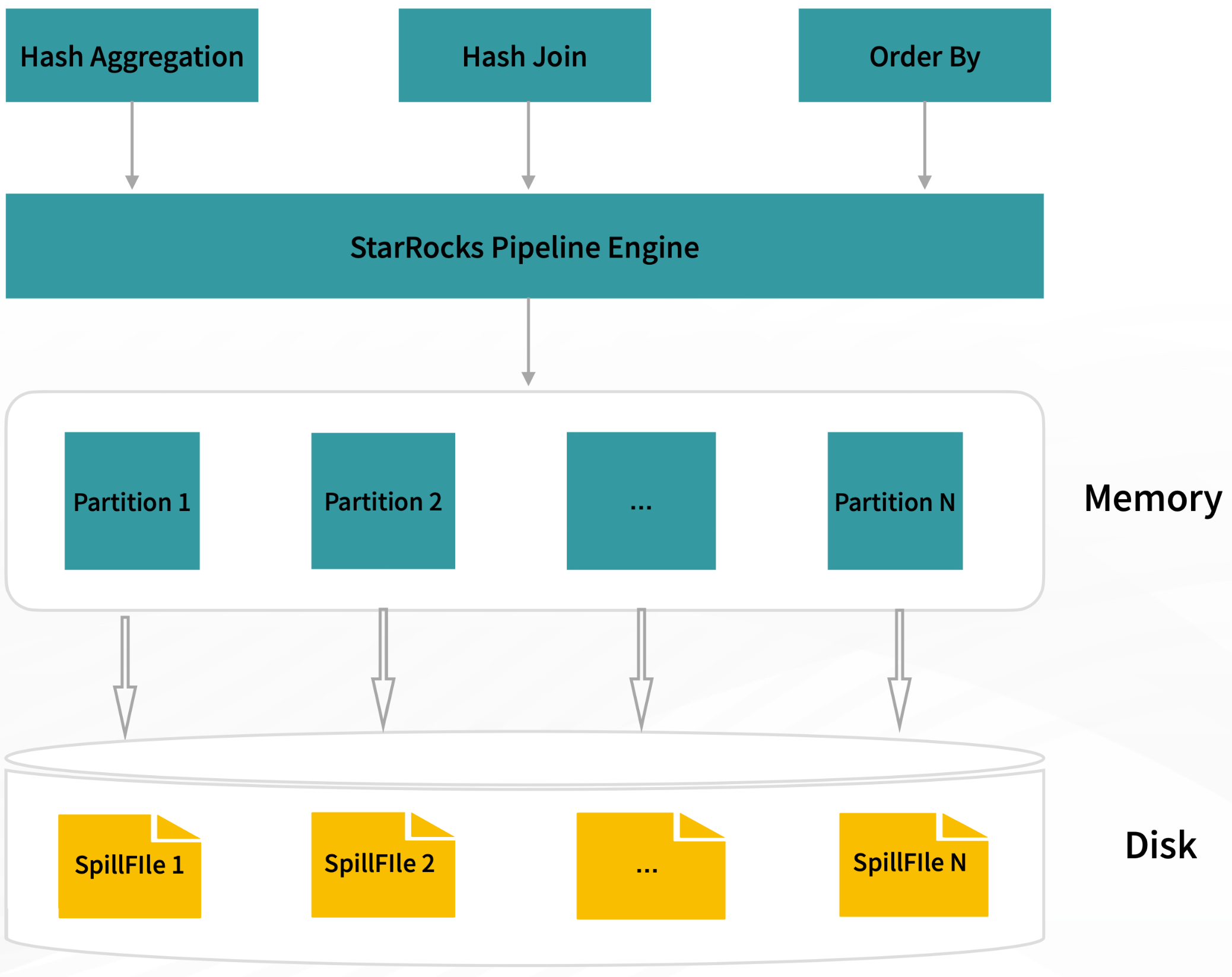
In addition to exceptional query performance, stability while querying large-scale datasets is equally crucial. When queries involve aggregation, sorting, or join operators, enabling spill allows related operators to cache intermediate computation results onto the disk. This significantly reduces memory usage and minimizes the likelihood of query failures due to memory constraints.
Enabling spill, particularly in memory-intensive scenarios such as materialized view construction and data ETL processing, greatly enhances query stability. For instance, TPCH and TPCDS 1TB can now be executed within less than 20GB of memory, a significant reduction from the previous requirement of over 128GB without spill enabled.
Enhanced Semi-Structured Analysis Capabilities
In Version 3.1, StarRocks takes a significant leap in its semi-structured data analysis capabilities by officially introducing native support for Map and Struct data types. This enhancement extends beyond data analysis on the data lake, encompassing table creation, data import, and materialized view construction. Furthermore, a broader array of functions for Map and Struct types has been introduced, encompassing scalar, aggregate, and advanced map functions.
The Array data type has received a boost with the inclusion of Fast Decimal support, and Array functions now accommodate nested structure types such as Map, Struct, and Array. These advancements empower users with unparalleled flexibility in their query and analysis endeavors.
StarRocks Version 3.1 reinforces its role as a comprehensive data analytics platform, catering to diverse data structures and unlocking the potential of semi-structured data for insights and decision-making. With this enhancement, users can delve deeper into their data, drawing meaningful conclusions from complex and varied data formats.
Thanks
The release of StarRocks version 3.1 would have been impossible without the efforts of StarRocks' community of contributors. In this version, 117 contributors submitted a total of 2785 commits. If you are interested to know more about StarRocks, please star/follow us on GitHub and join our Slack community!
Contributor list:
stdpain, Astralidea, mofeiatwork, yandongxiao, kevincai, Seaven, hellolilyliuyi, EsoragotoSpirit, Youngwb, andyziye, packy92, sduzh, meegoo, zaorangyang, caneGuy, silverbullet233, chaoyli, LiShuMing, trueeyu, srlch, liuyehcf, ABingHuang, luohaha, amber-create, miomiocat, sevev, letian-jiang, stephen-shelby, zombee0, nshangyiming, satanson, fzhedu, Smith-Cruise, gengjun-git, decster, TszKitLo40, starrocks-xupeng, evelynzhaojie, ZiheLiu, zhenxiao, wyb, rickif, HangyuanLiu, liuzhongjun89, dirtysalt, abc982627271, wanpengfei-git, SilvaXiang, hongli-my, kangkaisen, liuyufei9527, ggKe, xuzifu666, ucasfl, GavinMar, jkim650, JackeyLee007, tracymacding, huzhichengdd, Moonm3n, silly-carbon, imay, szza, you06, leoyy0316, Johnsonginati, smartlxh, xiangguangyxg, vendanner, QingdongZeng3, zhangruchubaba, wxl24life, banmoy, matchyc, predator4ann, huangfeng1993, dengliu, choury, bowenliang123, sebpop, RamaMalladiAWS, dustinlineweber, jiacheng-celonis, chen9t, blanklin030, wangsimo0, howrocks, qmengss, alberttwong, before-Sunrise, chenjian2664, wangruin, kobebryantlin0, wangxiaobaidu11, creatstar, kateshaowanjou, huandzh, mlimwxxnn, goldenbean, Jay-ju, ss892714028, mchades, cbcbq, shileifu, xiaoyong-z, sfwang218, uncleGen, r-sniper, blackstar-baba, ldsink, gddezero, fieldsfarmer, even986025158, idomic, yangrong688, padmejin, zuyu
