✍🏼 About the Author:Kaisen Kang, StarRocks TSC Member, Query Engine & AI Agent Team Lead at CelerData
Most databases were built for humans. A human analyst submits a query, waits a few seconds, reads the result, and writes another. The workload is predictable, sequential, and forgiving of latency. That model shaped a generation of analytics infrastructure—and it is exactly the wrong model for AI agents.
AI agents do not wait. They fire dozens of queries in parallel, iterate on partial results in milliseconds, demand data that is current to the second, and operate across multiple users and pipelines simultaneously. Put an AI agent workload on infrastructure designed for human analysts, and the database becomes the bottleneck—not because the underlying hardware is slow, but because the architecture was never designed for this pattern.
StarRocks was. Built from first principles for high-concurrency, low-latency analytical workloads, StarRocks is increasingly the engine teams reach for when they move AI Data Agents from prototype into production. Here is what makes it purpose-built for this workload.
One Question Becomes Dozens of Queries
Traditional analytics engines were optimized for human analysts running a handful of predetermined queries against stable access patterns. AI agents break every assumption in that model.
Consider a concrete example. A business user asks: “Why did revenue drop in Europe last quarter?” A human analyst writes two or three queries and calls it done. An AI agent works differently, it explores revenue by region, breaks it down by product, joins campaign data, examines pricing changes, then drills into anomalies. That single question becomes 20, 30, or even 50 SQL queries, generated iteratively and on the fly. We have seen this pattern collapse otherwise solid infrastructure at the worst possible moment: when an agent is mid-investigation and a production dashboard goes dark.
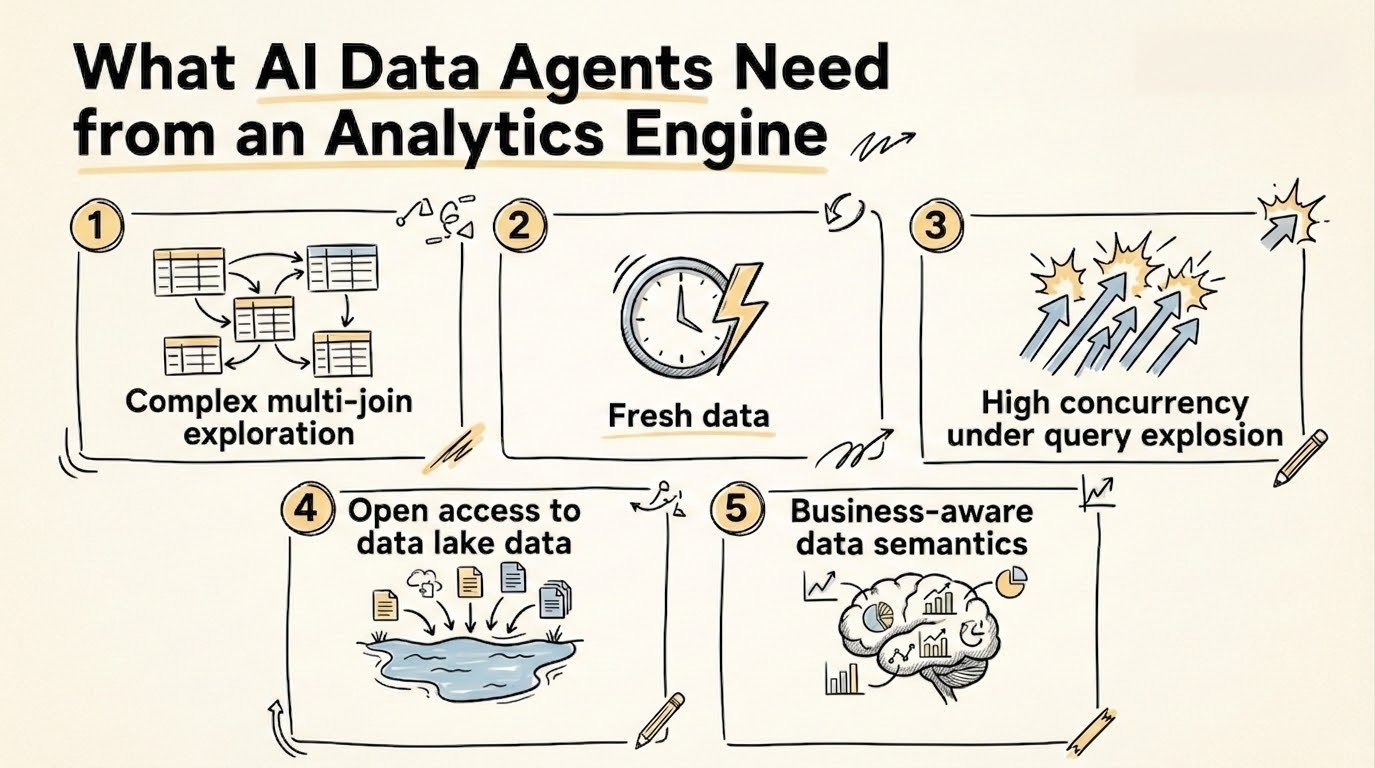
That shift creates five structural challenges that most databases are not built to satisfy:
-
Challenge 1: Complex multi-join exploration: Agent-generated SQL routinely joins five to ten tables, nests aggregations, and refines iteratively. Without a strong optimizer, this workload becomes slow and unstable quickly.
-
Challenge 2: Fresh operational data: Agents reasoning over business monitoring, financial analytics, or customer operations requires second-level data freshness. Hours-old data produces meaningless answers.
-
Challenge 3: High concurrency under query explosion: One user session generates dozens of parallel queries; multiply that across hundreds of concurrent users, and the concurrency pressure becomes extreme.
-
Challenge 4: Open access to data lake formats: Enterprise data lives in Iceberg, Hive, Hudi, Delta Lake, and transactional systems. Agents need a single execution layer spanning all of it.
-
Challenge 5: Business-aware data semantics: Syntactically valid SQL is not enough. When an agent queries “revenue,” the system must know whether that means gross, net, recognized, or booked—or the answer will be wrong.
Here’s how StarRocks addresses each of them.
Solution 1: Self-Healing Query Optimization for AI-Generated SQL
Here is the dirty secret of AI-generated SQL: it is inherently unpredictable. Join orders shift, aggregations nest arbitrarily, and CTEs appear without warning. A cost-based optimizer calibrated for human-written queries can fail badly when the SQL is generated by an LLM with no awareness of table statistics or data distribution.
StarRocks ships a mature cost-based optimizer continuously hardened against production failure modes: missing statistics, inaccurate sampling, data skew, and plan instability. Global runtime filters reduce scan data on large fact tables by orders of magnitude for complex join queries, delivering 10x to 100x performance improvements on the multi-join patterns AI agents generate most frequently.
The deeper capability is Query Feedback. AI agents generate “black-box” SQL with unpredictable join orders, a pattern traditional optimizers handle poorly when statistics are incomplete. StarRocks’ SQL Tuning Advisor monitors real-time execution, detects bad plans, and automatically corrects them for subsequent runs. In practice, agent-generated SQL that initially performs poorly improves without manual tuning intervention; the system creates a self-healing loop that stabilizes performance as agent query patterns evolve. That matters in production: you cannot hotfix an agent mid-run, so the database has to fix itself.

Solution 2: Second-Level Freshness Without Sacrificing Query Speed
Operational AI agents cannot tolerate delays in the batch pipeline. An agent monitoring for fraud, tracking live inventory, or responding to customer behavior needs data that is current to seconds, not hours. Stale data does not just produce wrong answers; in agentic workflows, it produces confidently wrong answers that propagate downstream.
StarRocks ingests streaming data from Kafka and Flink through native connectors, eliminating ETL lag and making new records queryable in near-real time. More critically, StarRocks supports primary key tables with real-time update and delete through a Delete-and-Insert architecture. When a row is updated, the prior record is marked in a Delete Vector, a Bitmap structure, so queries skip deleted rows at scan time rather than performing expensive merges. Compaction removes stale data asynchronously. The result: second-level freshness with no degradation in query performance, which is the exact combination operational AI agents require.
Upcoming incremental materialized views extend this further, enabling real-time maintenance of precomputed results for recurring or structurally similar query patterns, a direct performance multiplier for agents that repeatedly ask variations of the same question.
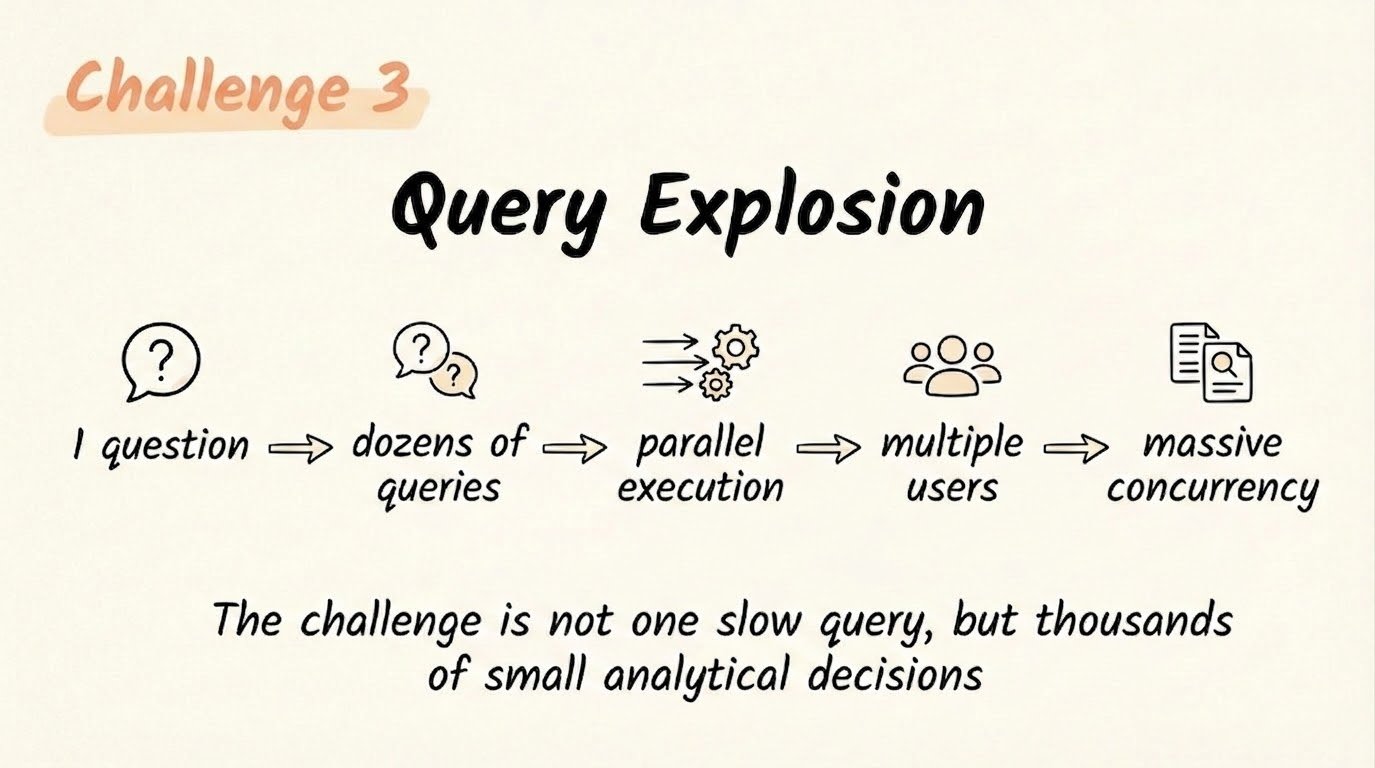
Solution 3: Extreme Concurrency: Built for Query Explosion
The concurrency challenge for AI agents is not just large; it is structurally different from traditional analytics. A single user session generates dozens of parallel SQL queries. Multiply that across hundreds of concurrent users and multiple agent pipelines, and the system must sustain thousands of queries per second without resource contention causing cascading degradation.
StarRocks handles this through layered execution and isolation:

-
Vectorized engine: Fully utilizes all CPU cores on a single node, maximizing single-node throughput before distribution overhead becomes the limiting factor.
-
MPP distributed execution: Scales horizontally across nodes, allowing the cluster to absorb concurrency increases without architectural changes.
-
Resource groups and multi-warehouse: Resource groups enforce workload isolation at the node level; multi-warehouse extends that isolation to the full cluster. An ad-hoc AI exploration workload never contends with a production BI reporting job, even when both access the same data in S3.
-
Tablet-level query cache: Unlike result-set caches, StarRocks caches intermediate aggregated results at the physical storage unit level. When a second query overlaps with the tablet scan from a prior query, cached intermediate results are reused; only new ranges are recomputed. In high-concurrency AI agent deployments, this approach pushes throughput into the tens of thousands of QPS range.
Solution 4: Open Data Access Across the Lakehouse
Enterprise data does not live in one place. AI agents need to query Iceberg, Hive, Hudi, and Delta Lake alongside natively stored StarRocks data, without ETL pipelines to consolidate everything first.
StarRocks queries open table formats directly with zero-copy access to S3. A common production pattern stores the past week of operational data natively in StarRocks for real-time update and sub-second query performance; historical data remains in Iceberg. The agent queries both seamlessly through a single interface, no additional abstraction layer required.
Performance on open formats is a material differentiator: on a 1TB TPC-DS benchmark using Iceberg on identical clusters, StarRocks runs approximately 8x faster than Trino. StarRocks also supports materialized views over Iceberg tables, compounding that advantage for repeating query patterns agents generate at scale.

Solution 5: Semantic Layer + Knowledge Base
LLMs generate syntactically valid SQL with increasing reliability. But syntax is not the production challenge. The challenge is business meaning.
What is “revenue”? In most organizations, that single word can mean gross revenue, net revenue, recognized revenue, or booked revenue, depending on the context, team, and reporting period. An agent that generates a technically correct query against the wrong definition returns a number that runs without errors and is completely wrong.
StarRocks is building a semantic layer and knowledge base to address this directly. The semantic layer encodes business metrics, dimension definitions, table relationships, and statistics; the knowledge base stores enterprise documents, business rules, and validated historical question-SQL pairs. When an agent generates SQL, it retrieves relevant semantic context and prior validated queries, grounding generation in business reality rather than schema syntax alone.
The Direction StarRocks is Heading
These five capabilities form the foundation, but StarRocks is building beyond them. The next frontier is turning the analytics engine itself into an intelligent layer that learns from every agent interaction.
The Self-Improving Agent Loop
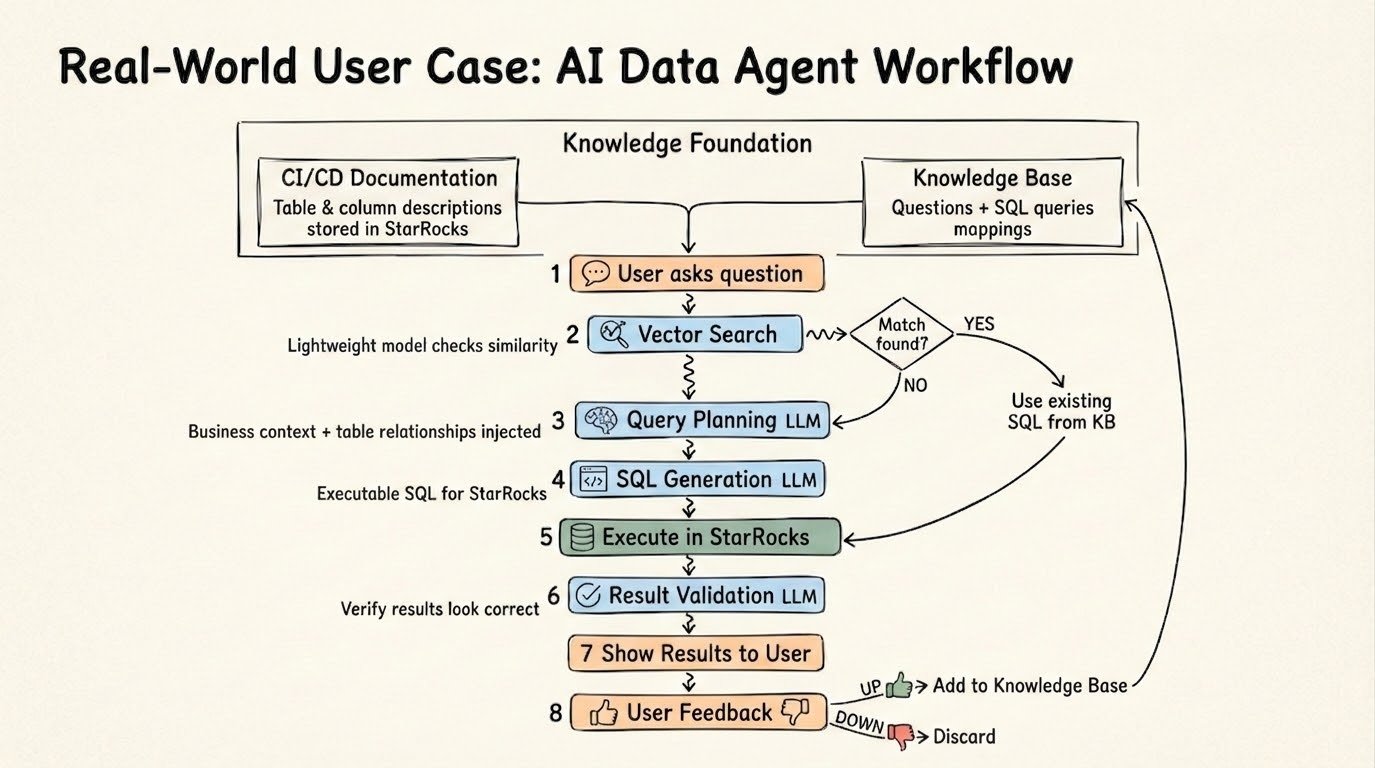
Production deployments of AI Data Agents on StarRocks converge on a pattern that compounds in value over time. When a new question arrives, the system first checks the knowledge base for a close match to a previously validated query—if one exists, the agent reuses the known-good SQL rather than generating it from scratch. If no match is found, the system applies schema relationships and business context to plan and generate new SQL, executes it in StarRocks, validates the result, and adds the confirmed question-SQL pair back into the knowledge base.
The result is a continuously self-improving loop: retrieve, plan, execute, validate, and learn. Agent accuracy and response speed increase over time without manual intervention.
StarRocks as the Knowledge Lake Foundation
The trajectory for production AI Data Agents points toward two complementary components. The DB Agent embeds intelligence inside the database itself, analyzing SQL patterns generated by AI agents, identifying optimization opportunities, and automatically adjusting schemas, indexes, and materialized views. The Knowledge Brain Agent provides memory, business context, and accumulated enterprise knowledge, continuously improving from historical queries, documents, and user feedback.
StarRocks is evolving to serve as the shared foundation for both: a Knowledge Lake that unifies hybrid search, a semantic layer, structured data, and unstructured data in a single system. In this architecture, the analytics engine is not just an execution target; it is the intelligence substrate that makes production-grade AI Data Agents possible.
The Right Foundation for AI-Native Analytics
Picking the right analytics engine for an AI agent deployment is not a performance tuning decision—it is an architectural one. The five challenges described here are not edge cases. They are the baseline requirements for any agent that needs to operate reliably in production: handling complex exploration queries, reasoning over fresh data, surviving concurrency spikes, accessing the full enterprise data estate, and returning answers grounded in business meaning.
Start building with StarRocks at starrocks.io, or join our StarRocks community on Slack to talk about how it performs under your production AI workload.
Further Reading
Inside StarRocks: Why Joins Are Faster Than You’d Expect
Deep Dive: How StarRocks Built a High-Performance Vectorized Engine
