✍🏼 About the Author:Kaisen Kang, StarRocks TSC Member, Query Engine & AI Agent Team Lead at CelerData
Modern analytical workloads demand ever-increasing performance, and vectorized execution has become one of the most powerful techniques for accelerating query processing. Broadly speaking, vectorization refers to the use of CPU SIMD (Single Instruction, Multiple Data) instructions to process multiple data elements in parallel rather than one at a time under the traditional scalar model. By allowing a single instruction to operate on a batch of values simultaneously, SIMD significantly increases throughput and forms the hardware foundation for many high-performance analytical databases.
Yet vectorization in a database is far more than simply enabling CPU SIMD instructions. It represents a systematic rethinking of execution models, data layout, and performance engineering. Drawing on StarRocks' hands-on experience building a production-grade vectorized engine, this article explores both the underlying principles and the practical realities of this transformation.
This article consists of three parts: an overview of vectorization fundamentals, an explanation of how databases implement vectorization, and practical insights drawn from StarRocks' experience with vectorized execution.
Why Does Vectorization Improve Database Performance?
Most analytical databases are built on top of CPU architectures. In this article, when we talk about vectorization, we specifically mean CPU-level vectorization. At its core, optimizing database performance is fundamentally the same as optimizing any CPU-bound program.
This leads to two fundamental questions:
-
How do we measure CPU performance?
-
What factors influence CPU performance?
Measuring CPU Performance
The following formula can summarize CPU performance: CPU Time = Instruction Count * CPI * Clock Cycle Time
-
Instruction Count refers to the total number of instructions executed. Any CPU program ultimately translates into machine instructions, and the number of instructions generally depends on the program's complexity.
-
CPI (Cycles Per Instruction) represents the average number of clock cycles required to execute a single instruction.
-
Clock Cycle Time is the duration of one CPU clock cycle and is tightly coupled with hardware characteristics.
At the software level, we can influence only the first two factors: Instruction Count and CPI.
This raises an important question: for a given CPU program, what specifically affects Instruction Count and CPI?
Understanding CPU Execution
A typical CPU instruction goes through five stages:
-
Instruction Fetch
-
Instruction Decode
-
Execute
-
Memory Access
-
Write Back
The first two stages are handled by the CPU Frontend, while the remaining three are managed by the Backend. Based on this architecture, Intel introduced the Top-Down Microarchitecture Analysis Method to analyze CPU performance bottlenecks.
%EF%B9%96width=2750&height=1822&name=image%20(48).png) Top-Down Microarchitecture Analysis Method by Intel
Top-Down Microarchitecture Analysis Method by Intel
For simplicity, we can roughly categorize CPU performance bottlenecks into four major types: Retiring, Bad Speculation, Frontend Bound, and Backend Bound:
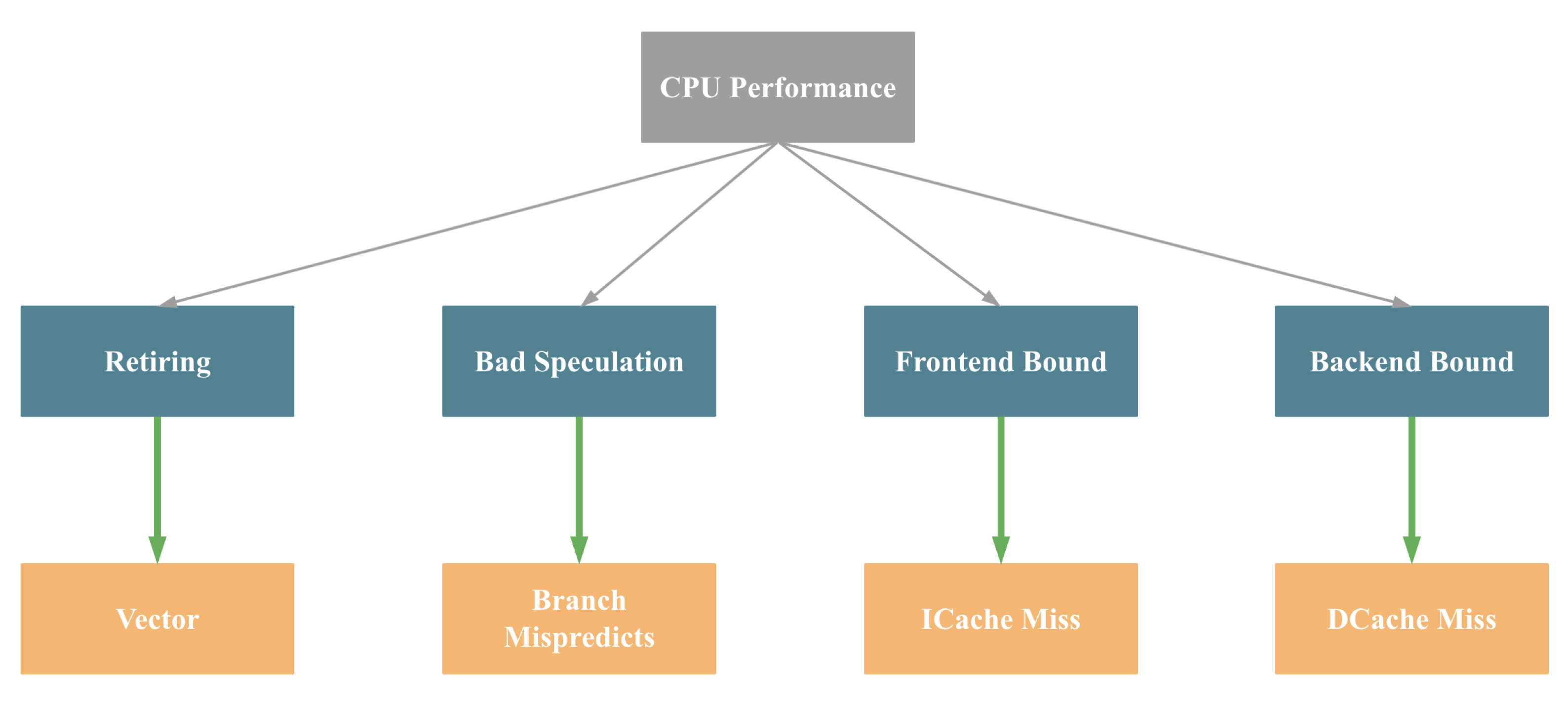
Although this simplification is not fully precise, these bottlenecks are typically associated with the following causes:
-
Retiring → Insufficient SIMD optimization
-
Bad Speculation → Branch misprediction
-
Frontend Bound → Instruction cache misses
-
Backend Bound → Data cache misses
Mapping this back to the earlier CPU time formula, we can draw the following conclusions:
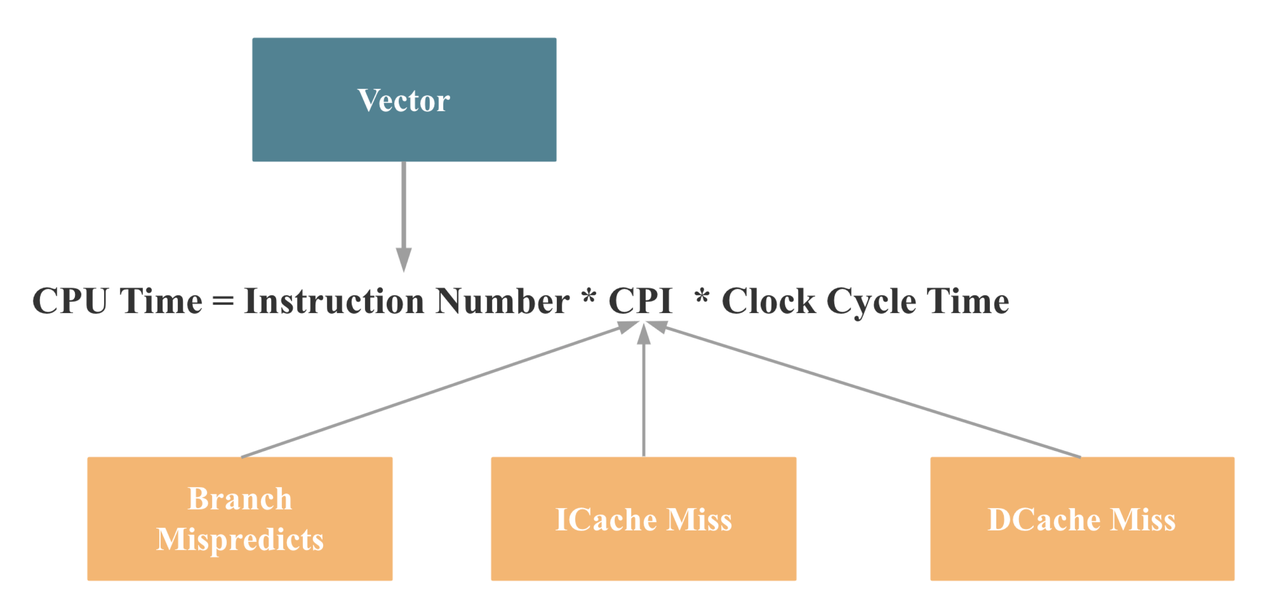
Database vectorization improves all four of these aspects, as we will explain in detail later. At this point, we have established, at a fundamental level, why vectorization can significantly enhance database performance.
Vectorization Fundamentals
Before exploring how databases implement vectorization, we need to understand several core concepts. In this section, vectorization refers specifically to CPU SIMD vectorization (narrow sense), not the broader meaning of vectorization in the database domain.
Introduction to SIMD
SIMD (Single Instruction, Multiple Data) allows a single instruction to operate on multiple data elements simultaneously. This contrasts with SISD (Single Instruction, Single Data), the traditional scalar execution model.
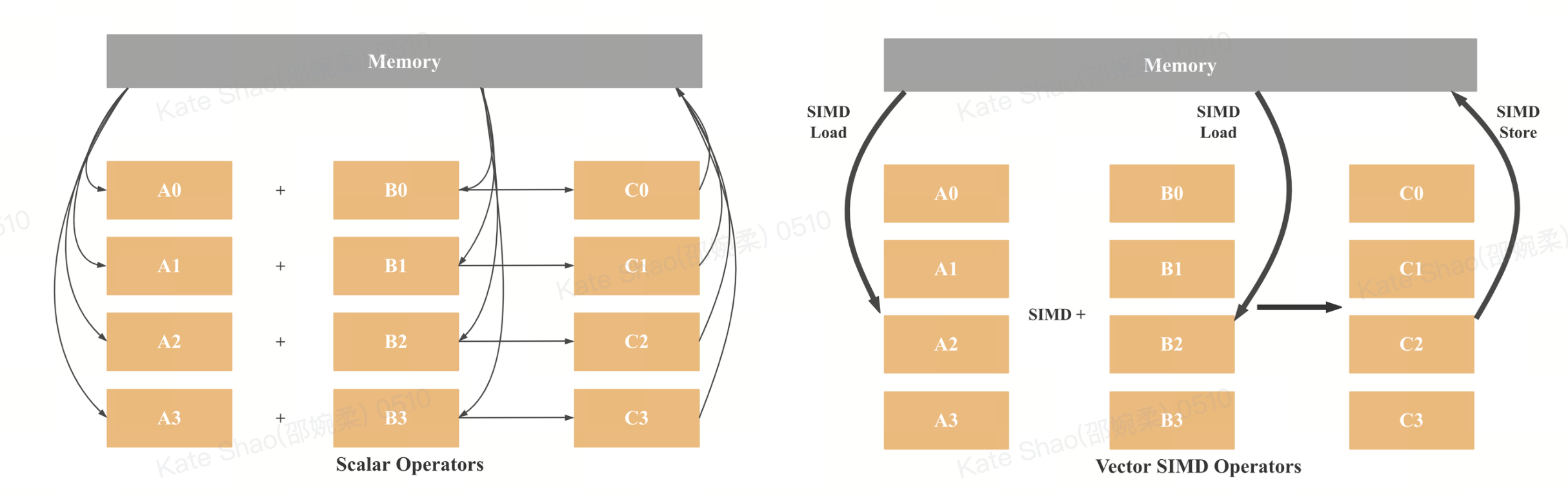
Take a simple example: C = A + B, computed for four pairs of values. With SISD, we would need:
-
8 load instructions (4 for A, 4 for B)
-
4 add instructions
-
4 store instructions
With 128-bit SIMD, the same work requires:
-
2 load instructions
-
1 add instruction
-
1 store instruction
In theory, this delivers a 4× performance improvement. Modern CPUs now support 512-bit vector registers, which can theoretically accelerate integer addition by up to 16×.
How to Enable Vectorization
Because SIMD can significantly improve performance, developers must understand how to trigger it. There are generally six approaches listed here, from highest-level (least manual effort) to lowest-level (most control):
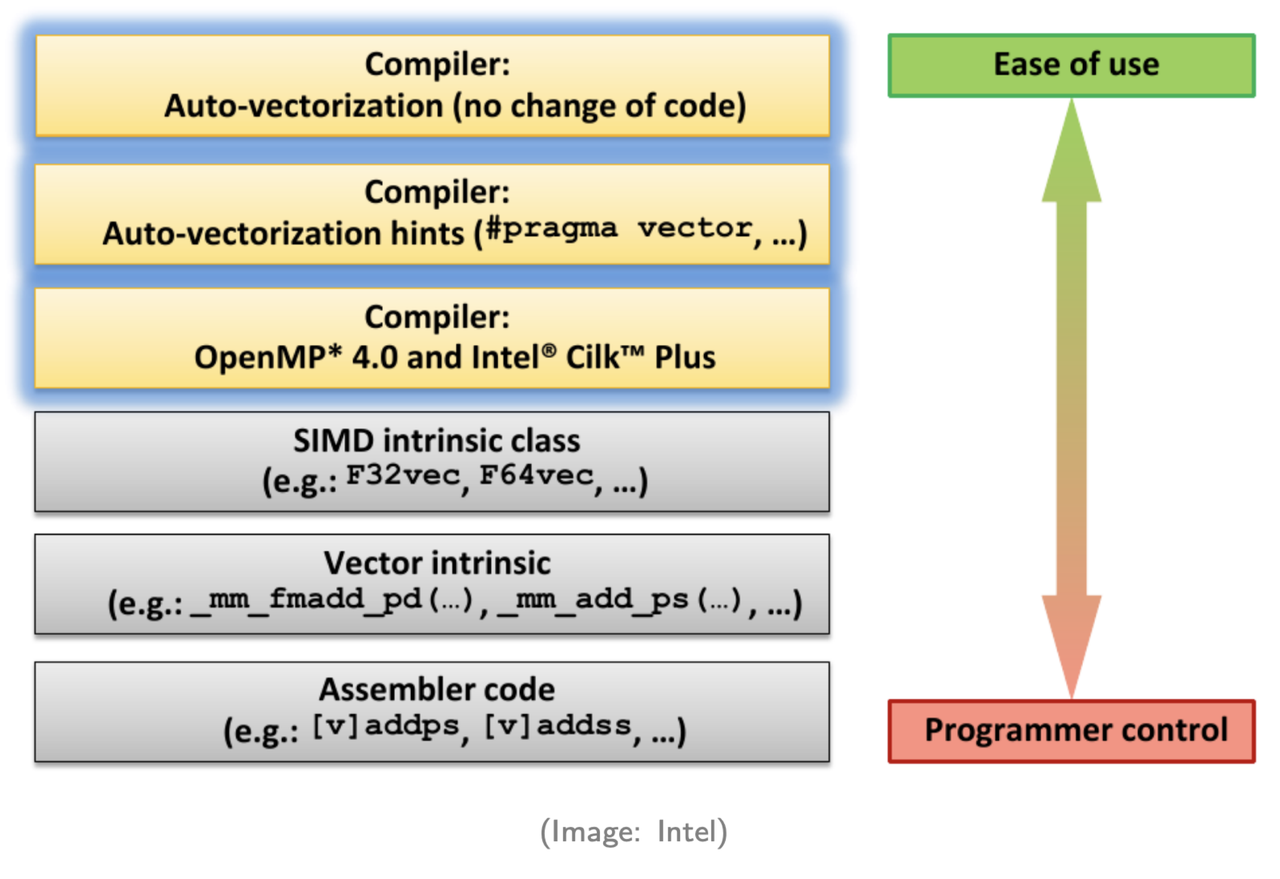
-
Compiler auto-vectorization – The compiler automatically converts scalar code into SIMD instructions. This works well for relatively simple patterns.
-
Compiler hints – Providing additional information (e.g., pragmas or directives) helps the compiler generate SIMD code.
-
Parallel programming APIs – Using frameworks such as OpenMP or Intel TBB with pragmas to enable vectorization.
-
SIMD wrapper libraries – Higher-level abstractions over intrinsics.
-
SIMD intrinsics – Direct use of architecture-specific SIMD instructions.
-
Assembly programming – Writing vectorized instructions manually.
In the StarRocks project, our principle is to prioritize compiler auto-vectorization (methods 1 and 2). For performance-critical paths that cannot be auto-vectorized, we use SIMD intrinsics for manual optimization.
Verifying Vectorization
When a project's codebase becomes complex, ensuring that vectorization is actually triggered is a common challenge. We can verify this in two ways.
- The first method: enabling specific compiler flags that report whether certain code sections were vectorized and, if not, explain the reason. For example, with GCC, you can use options such as
-fopt-info-vec-all,-fopt-info-vec-optimized,-fopt-info-vec-missed, and-fopt-info-vec-note. The output will indicate which parts of the code were successfully vectorized and provide diagnostic information for those that were not, as illustrated below.

- The second method: Inspecting assembly code. Tools like Godbolt,
perf, or Intel VTune can help. If you see registers such asxmm,ymm, orzmm, or instructions starting withv, the code has likely been vectorized.
Database Vectorization
StarRocks' vectorized engine took more than two years to evolve from its first line of code into a mature, stable, and industry-leading query execution engine.In our experience, database vectorization is far more than simply enabling CPU SIMD instructions. It is a large-scale, systematic performance engineering effort that spans the entire execution stack.
Key Challenges
To better illustrate what this entails, let's look at some of the key challenges we encountered while building the StarRocks vectorized engine.
- End-to-end columnar layout: Data must be columnar across disk, memory, and network layers, requiring a fundamental redesign of both the storage and execution engines.
- Full operator and expression coverage: Every operator, expression, and function must support vectorized execution, often requiring years of engineering effort.
- Extensive SIMD optimization: Performance-critical logic must leverage SIMD wherever possible, often through detailed, case-by-case tuning.
- Redesigned memory management: Execution shifts from processing one row at a time to thousands of rows per batch, demanding a new memory strategy.
- Rebuilt core data structures: Operators such as Join, Aggregate, and Sort require redesigned internal data structures to operate efficiently in a columnar, batched model.
- Holistic performance gains (5× or more): Achieving significant end-to-end improvements requires eliminating bottlenecks across all operators and expressions. No weak links can remain.
The Key Principle: Batch Compute by Column
From an engineering perspective, database vectorization is primarily reflected in the vectorization of operators and expressions. The key principle behind this can be summarized in one sentence: Batch Compute by Column, as illustrated below.
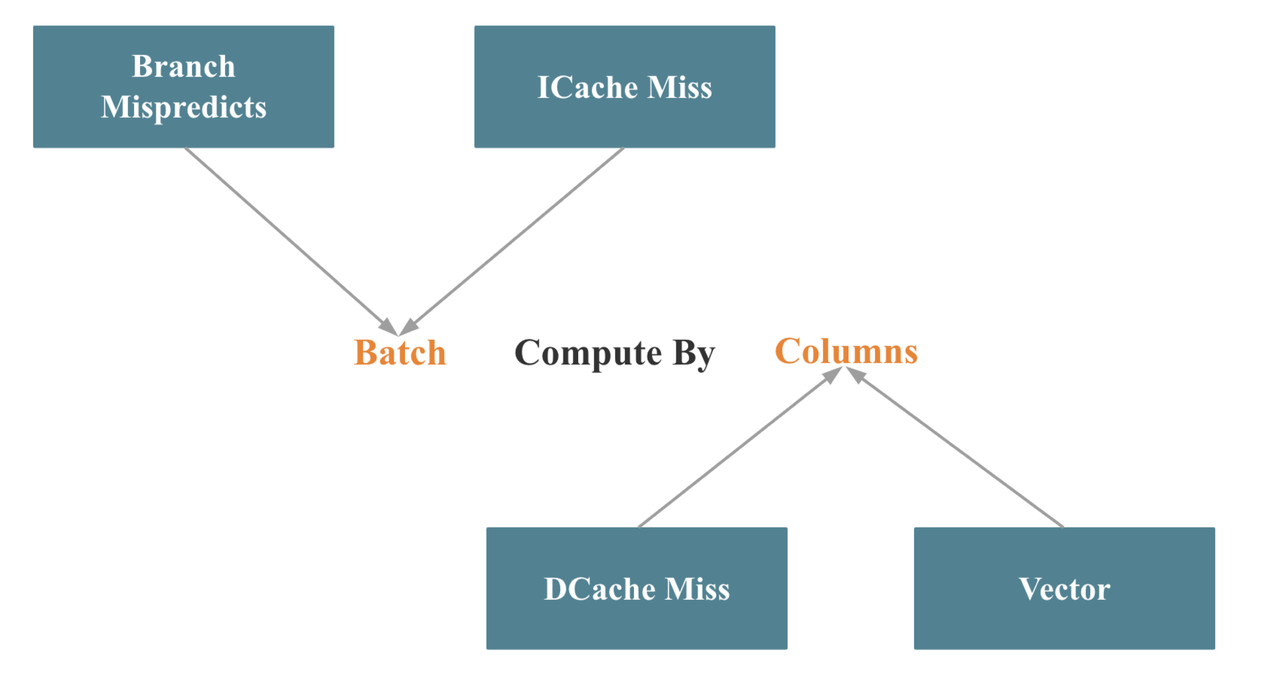
In terms of Intel's Top-Down analysis methodology, batch processing helps reduce branch mispredictions and instruction cache misses, while column-oriented processing improves data cache locality and makes it easier to trigger SIMD optimizations.
Batch execution itself is relatively straightforward to implement. The real challenge lies in redesigning core operators, such as Join, Aggregate, Sort, and Shuffle, to process data column by column. Even more challenging is maximizing SIMD utilization while maintaining a columnar execution model.
Performance Optimization in Practice
As discussed earlier, database vectorization is a comprehensive performance engineering effort. Over the years, we implemented hundreds of optimizations. Based on our experience (focusing on single-threaded execution, excluding concurrency), these optimizations fall into seven categories:
1. High-Performance Third-Party Libraries
Rather than reinventing well-optimized components, we adopt proven libraries where appropriate. In StarRocks, we use libraries such as Parallel HashMap, Fmt, SIMD JSON, and Hyperscan.
2. Data Structures and Algorithms
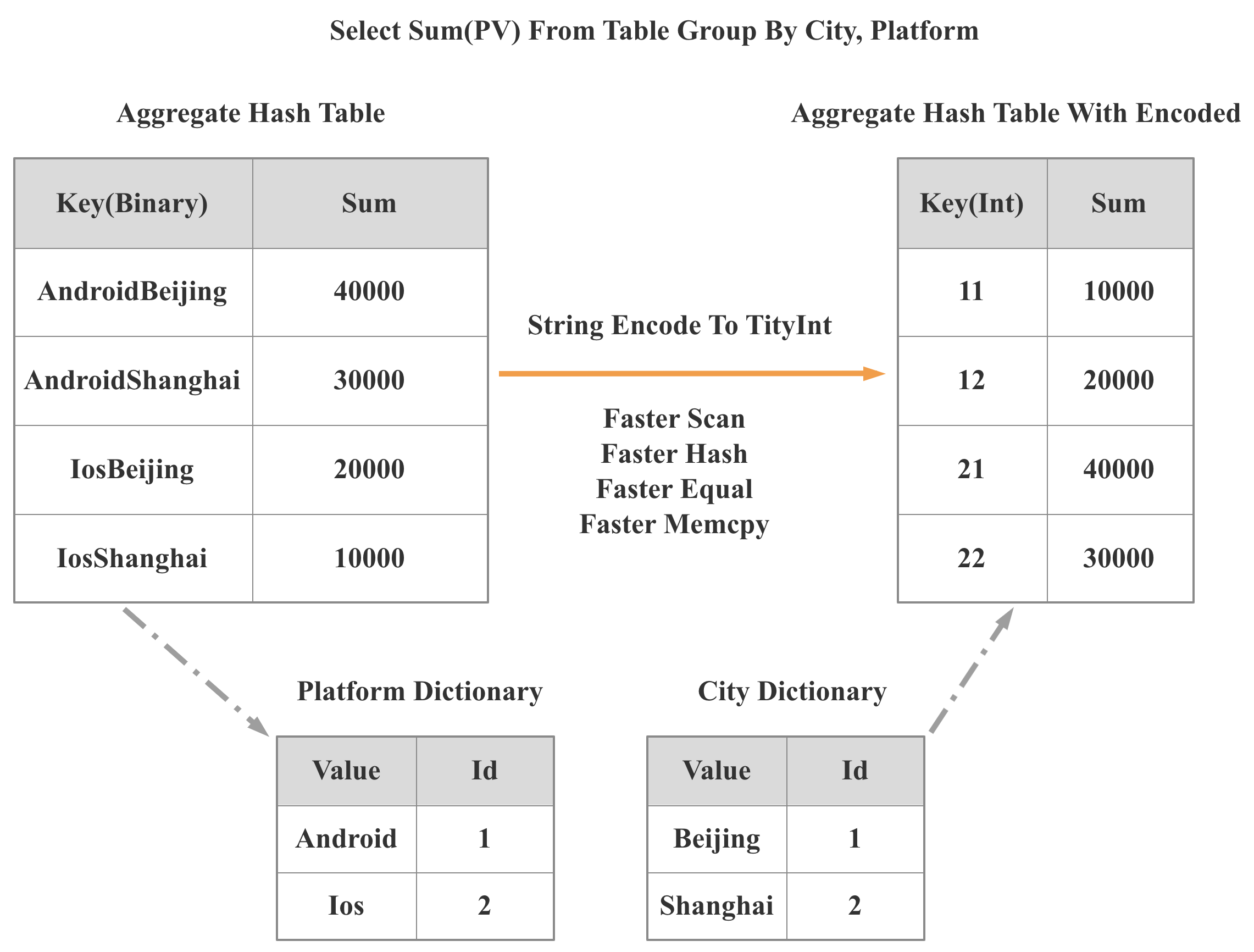
Efficient designs can reduce instruction counts by orders of magnitude. For example, StarRocks 2.0 introduced a low-cardinality global dictionary that converts string operations into integer operations. This change accelerates scanning, hashing, equality checks, and memory copying, delivering up to 3× overall query speedups in some cases.
3. Adaptive Optimization
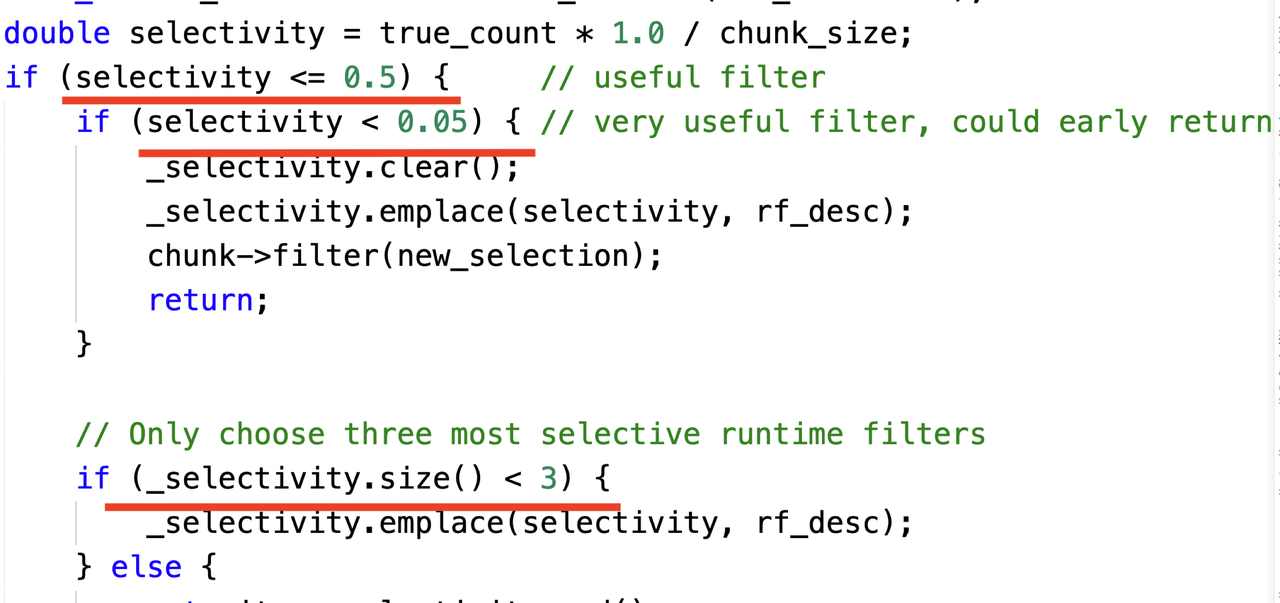
In many cases, having more context or runtime information enables more targeted optimizations. However, such information is often only available during query execution. Therefore, we must dynamically adjust execution strategies based on runtime context, a technique known as adaptive optimization. The example below illustrates how we dynamically select Join runtime filters based on selectivity. There are three key principles:
- If a filter eliminates almost no data, we do not select it.
- If a filter eliminates nearly all data, we retain only one such filter.
- We keep at most three effective filters.
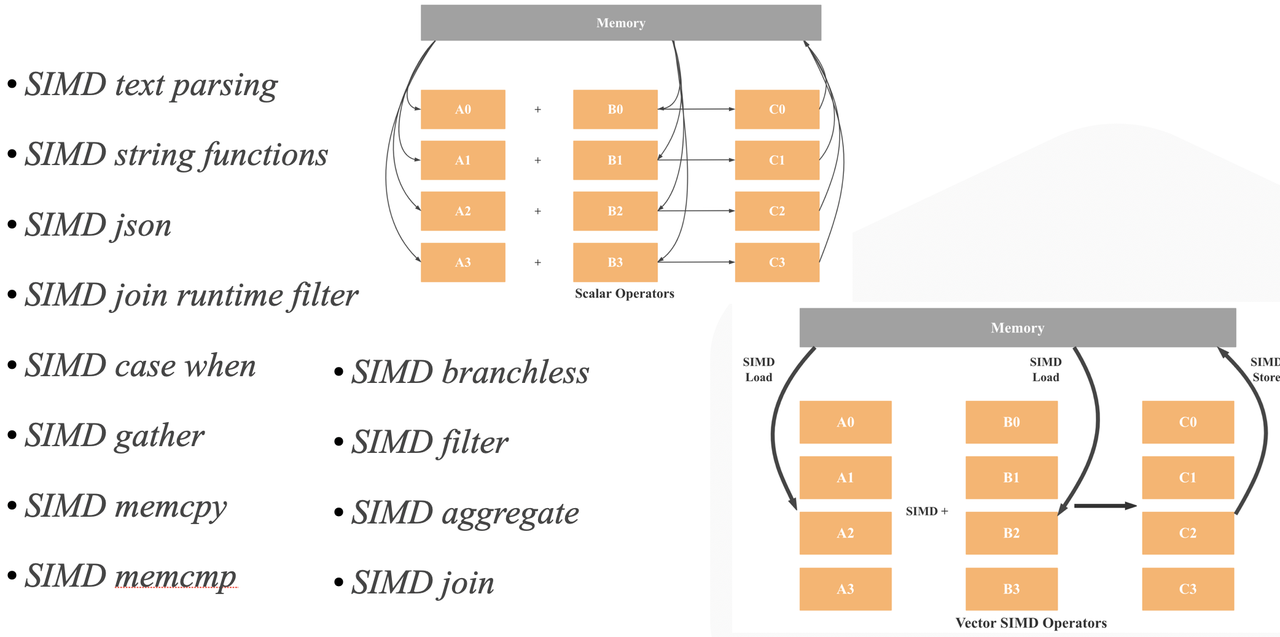
4. SIMD Optimization
As shown below, StarRocks makes extensive use of SIMD instructions across operators and expressions to improve performance.
5. Low-Level C++ Optimization
Even with identical algorithms and data structures, implementation details matter. Examples include avoiding unnecessary copies, reserving vector capacity, aggressive inlining, loop optimizations, and compile-time evaluation.
6. Memory Management Optimization
Larger batch sizes increase memory allocation pressure. We introduced a Column Pool to reuse column memory, significantly improving performance. For example, optimizing memory allocation in an HLL aggregation function, by switching to block-based allocation and reuse, improved performance by 5×.
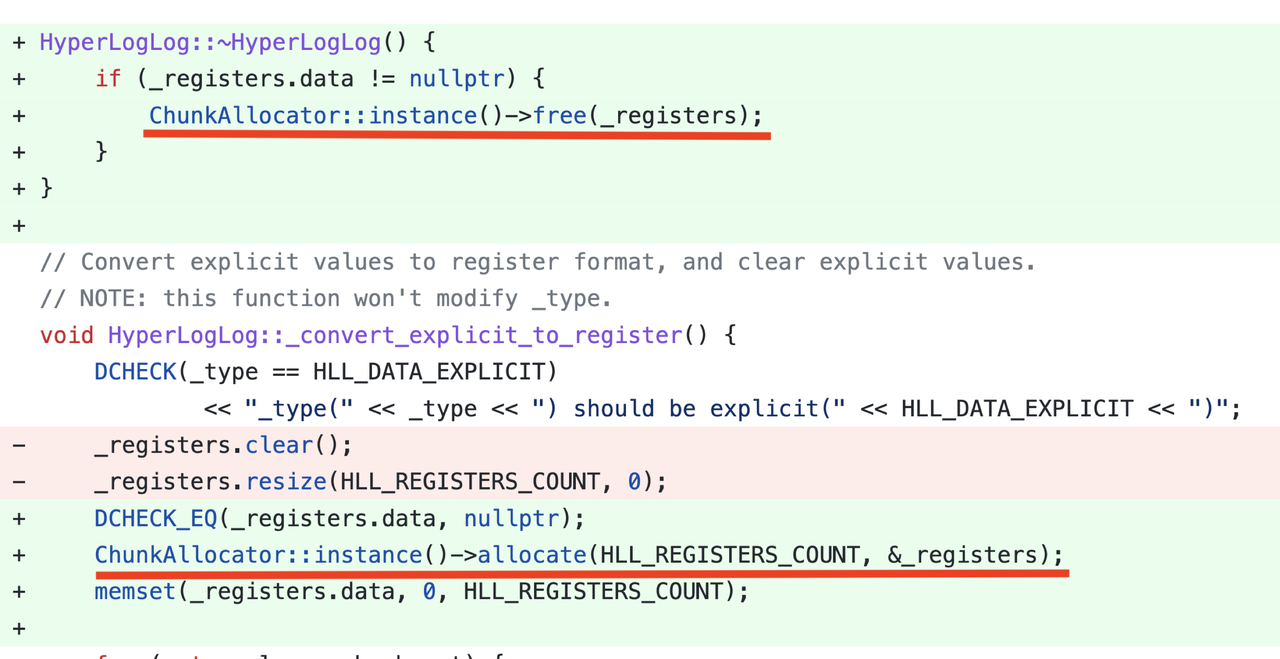
7. CPU Cache Optimization
Cache misses have a profound performance impact. After SIMD optimization, workloads often shift from CPU-bound to memory-bound. As performance improves, bottlenecks tend to migrate.
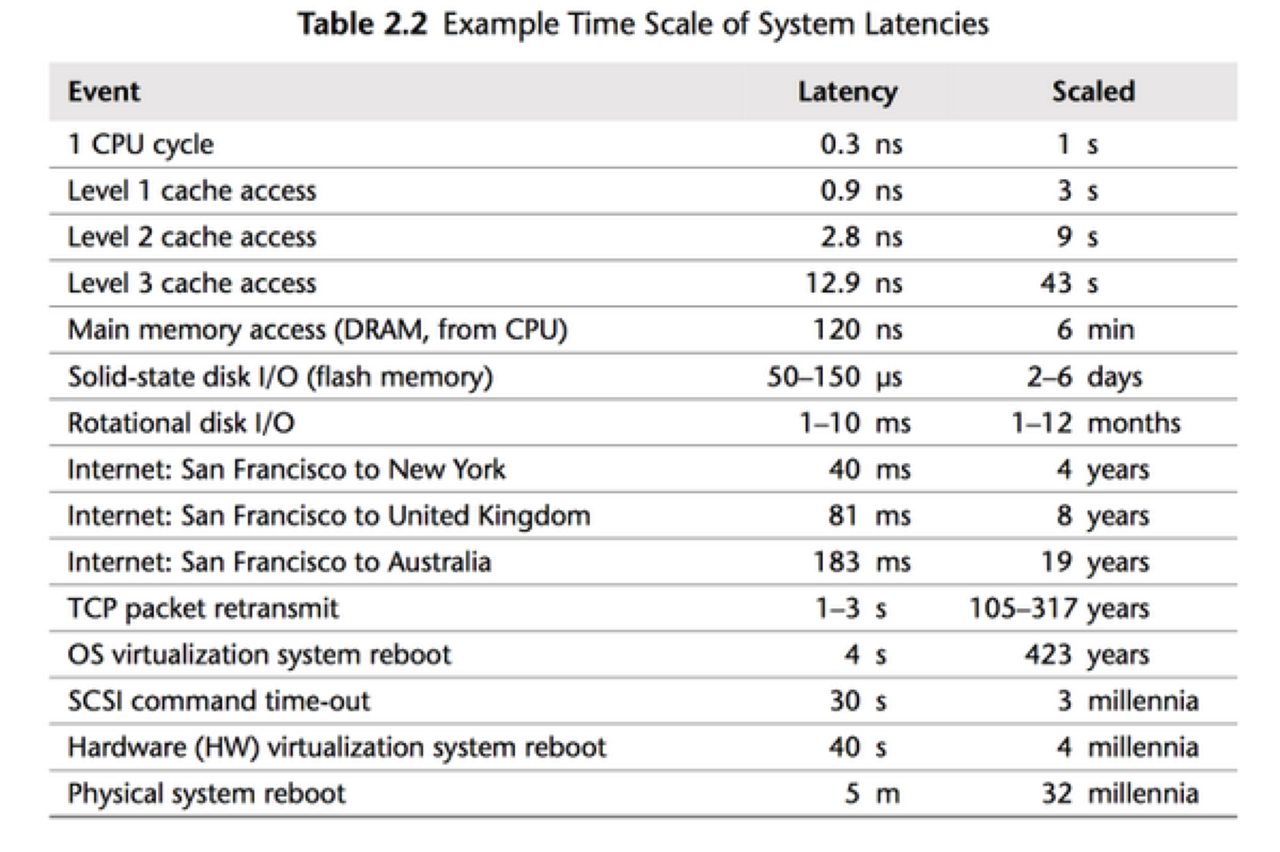
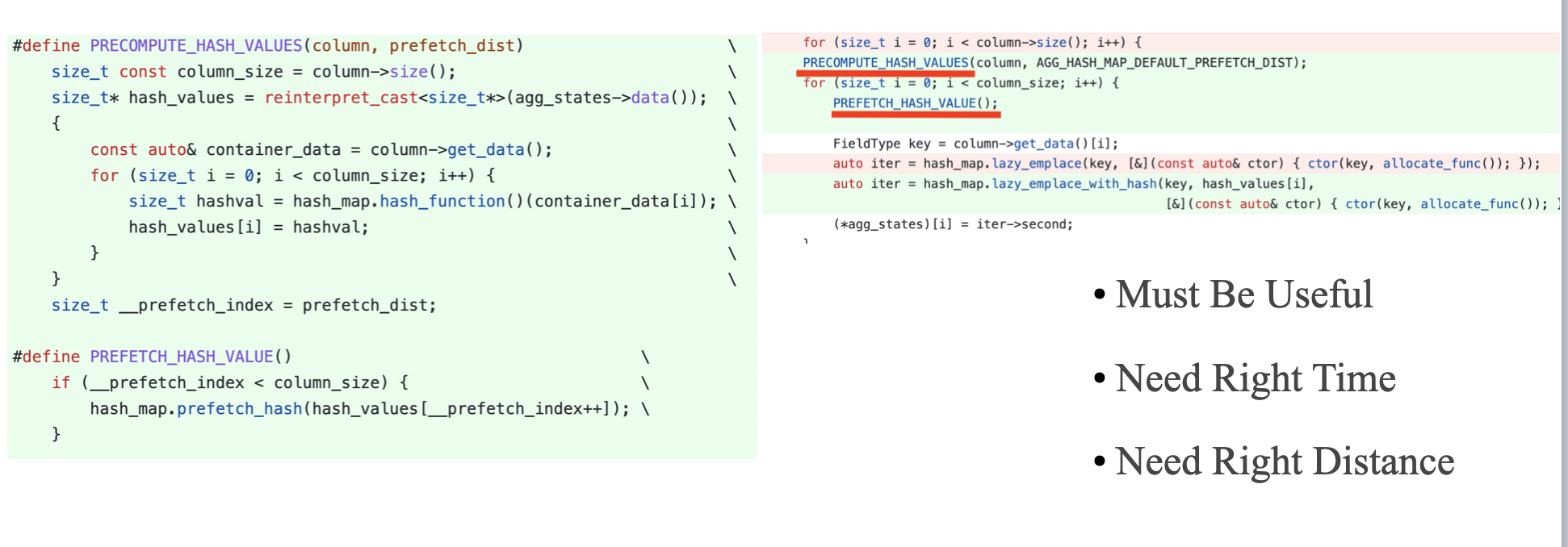
Reflections on the StarRocks Vectorization Journey
As I deepened my understanding of CPU microarchitecture, I began to see striking parallels between CPUs and database systems. Both follow a Frontend–Backend architecture: in a CPU, the Frontend handles instruction fetch and decode while the Backend executes instructions and interacts with data; in StarRocks, the Frontend parses SQL and generates execution plans, while the Backend executes queries and communicates with storage. The more systems you study, the more these structural patterns reveal themselves.
